都是透過程式自動抓取網站上資訊。
差異在於:Web crawling 目的是盡可能取得網站所有內容,並建立索引。例如: Google、Yahoo 的搜尋引擎。
Web scraping 是抓取網站特定資訊並進行整理。例如:股價資訊、訂房資訊。
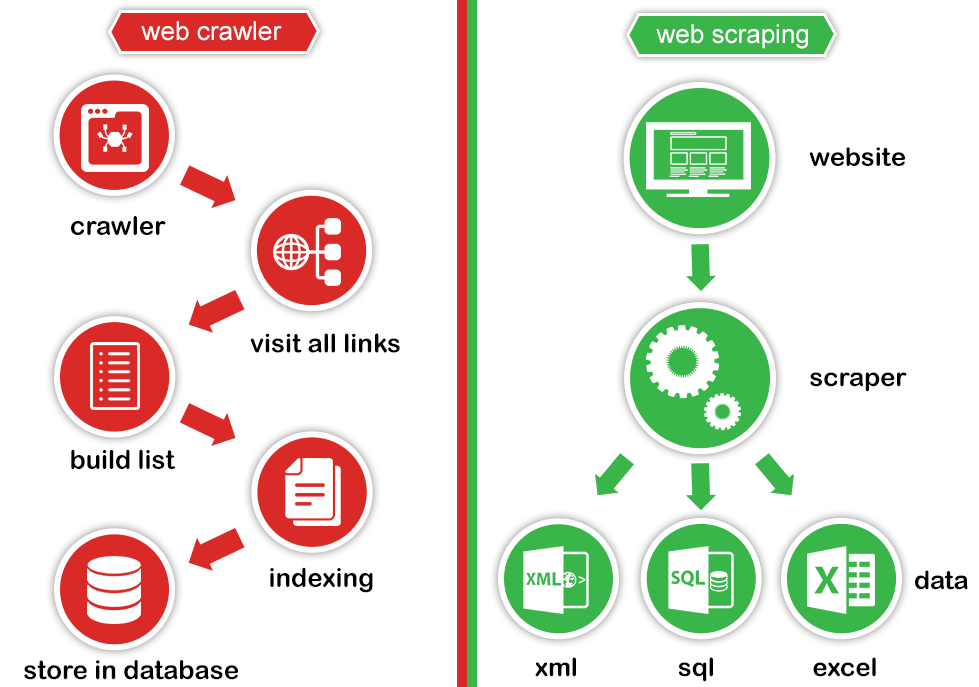
圖取自 Web Scraping Vs Web Crawling
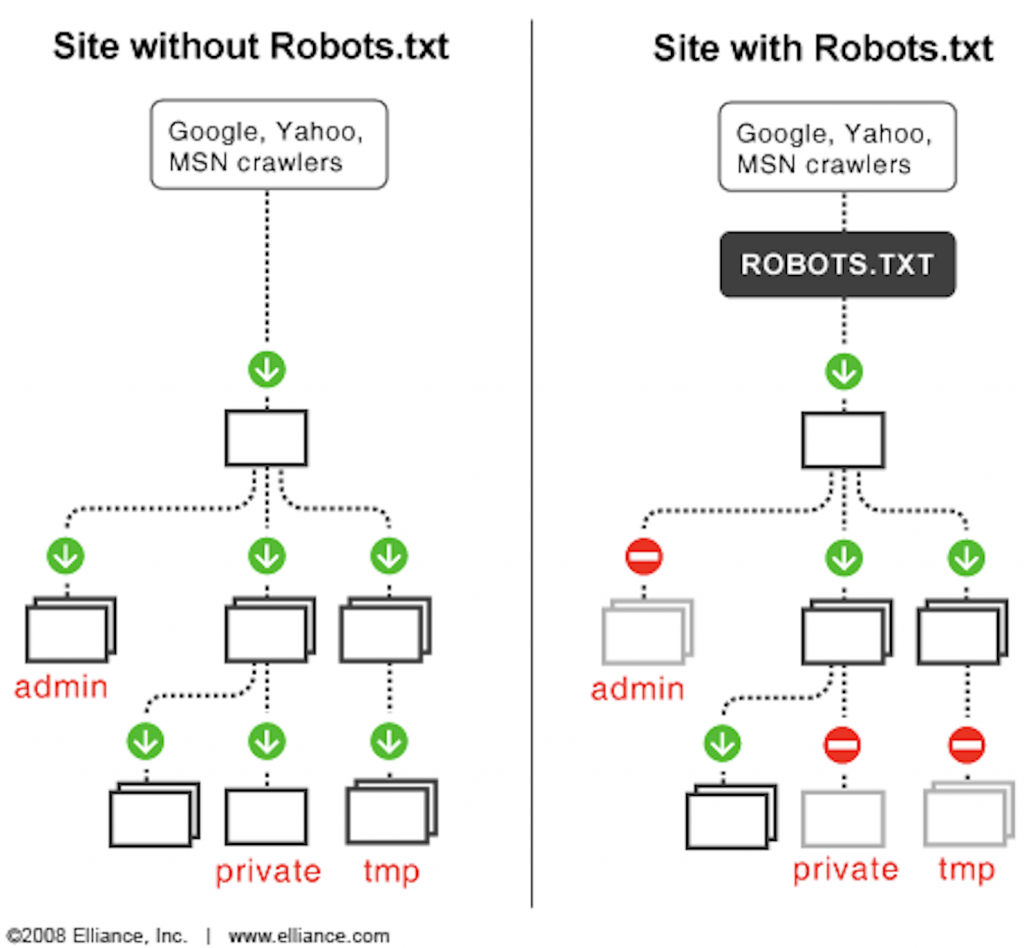
要注意的是:不是所有資料都可以抓取。有些網站會限制哪些頁面可以搜集。可以透過 robots.txt 確認資料是否可以搜集,例如:https://www.imdb.com/robots.txt。
imdb robots.txt 範例:
# robots.txt for https://www.imdb.com properties
User-agent: *
Disallow: /OnThisDay
Disallow: /ads/
Disallow: /ap/
Disallow: /mymovies/
Disallow: /r/
Disallow: /register
Disallow: /registration/
Disallow: /search/name-text
Disallow: /search/title-text
Disallow: /find
Disallow: /find$
Disallow: /find/
Disallow: /tvschedule
robots.txt 中會載明哪些 URL 搜尋引擎/bot 可以抓取或是特定的頁面不允許抓取,避免請求數超過負荷。
Web Crawling/Scraping 雖不違法,但仍處於一個灰色地帶,不論是否商用/用途為何,都一定要遵守網站 robots.txt 的規範。
robots.txt 檔案會放在網站根目錄下,例如 www.example.com/robots.txt,在一個robots.txt 中可包含多組設定,一組設定可包含多條規則。而每一組設定是針對特定的 user-agent/crawler 去做規範,使用空行來區隔每組 user agent/crawler。
基本格式:
User-agent: [user-agent name]
Disallow: [URL string not to be crawled]
| 規則 | 說明 |
|---|---|
| User-agent | 指定 web crawler |
| Disallow | 告訴 web crawler 禁止抓取的 URL, 只寫 Disallow: 代表每一個 URL 都允許 |
| Allow | 僅 Googlebot 使用,告訴 Googlebot 哪些頁面或是子目錄可以取得 |
| Crawl-delay | 每次抓取內容需間隔多少秒,Googlebot 會忽略這項規則,需到 Google Search Console 設定。 |
| Sitemap | sitemap.xml 位址,紀錄網站所有網址 |
範例:
User-agent: Googlebot
Disallow: /nogooglebot/
User-agent: *
Allow: /
Sitemap: https://www.example.com/sitemap.xml
// 說明:
- user-agent Googlebot 不允許抓取 https://example.com/nogooglebot/ 開頭的網頁內容
- Googlebot 以外的所有 user-agent 可以抓取整個網站的內容
- sitemap 檔案放在 https://www.example.com/sitemap.xml
注意事項:
robots.txt
robots.txt 檔案https://example.com/robots.txt規則只用在 https://example.com/,https://m.example.com/ 及 http://example.com/ 不算限制所有 user-agent 取得根目錄下任何內容,即禁止 web crawling/scraping
User-agent: *
Disallow: /
允許所有的 user-agent 可取得任何內容
User-agent: *
Disallow:
禁止 Googlebot 取得 /example-subfolder/ 目錄下的任何內容
User-agent: Googlebot
Disallow: /example-subfolder/
禁止任何 user-agent 取得網站內容,但 public 子目錄除外
User-agent: *
Disallow: /
Allow: /public/
禁止 Googlebot 取得所有.gif結尾的檔案
User-agent: Googlebot
Disallow: /*.gif$
認識網路爬蟲
What is a web crawler? | How web spiders work
How to scrape data from a website
MOZ - Robots.txt
How to write and submit a robots.txt file


 iThome鐵人賽
iThome鐵人賽