Pandas提供了多種方法來處理缺失值(Missing Values)和重覆值(Duplicate Values)。來試試看一些常用的技巧:
數據中的某些項目或特徵沒有被正確填寫、紀錄,導致值未知或不存在
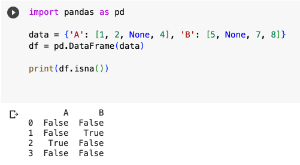
import pandas as pd
data = {'A': [1, 2, None, 4], 'B': [5, None, 7, 8]}
df = pd.DataFrame(data)
print(df.isna())
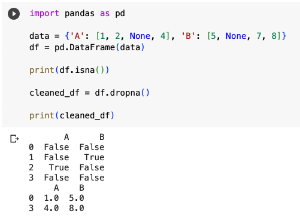
2. 去除缺失值:用dropna()來刪除包含缺失值的行、列。
import pandas as pd
data = {'A': [1, 2, None, 4], 'B': [5, None, 7, 8]}
df = pd.DataFrame(data)
print(df.isna())
cleaned_df = df.dropna()
print(cleaned_df)
3. 填補缺失值:用fillna()來填補。
import pandas as pd
data = {'A': [1, 2, None, 4], 'B': [5, None, 7, 8]}
df = pd.DataFrame(data)
print(df.isna())
cleaned_df = df.dropna()
print(cleaned_df)

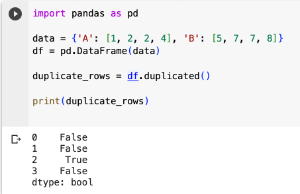
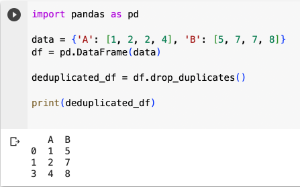
數據中某些項目或觀察值在數據中出現多次,可能是因為數據錯誤、提取錯誤導致。
import pandas as pd
data = {'A': [1, 2, 2, 4], 'B': [5, 7, 7, 8]}
df = pd.DataFrame(data)
deduplicated_df = df.drop_duplicates()
print(deduplicated_df)
現在我們匯入一筆資料來看看實際的效果:
from google.colab import files
uploaded = files.upload()
import io
import pandas as pd
df = pd.read_excel('test.xlsx')
print(len(df))
df.head(21)
偵測缺失值,然後刪除含有缺失值的資料,再來也可以填補缺失的資料:
print(df.isna())
cleaned_df = df.dropna()
filled_df = df.fillna(0)
print()
print(cleaned_df)
print()
print(filled_df)
會看到結果如下: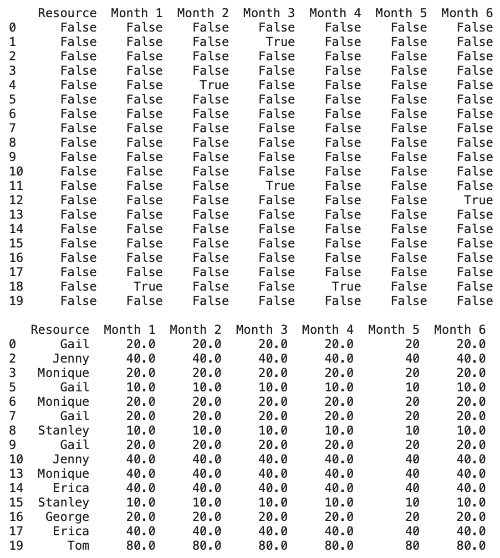
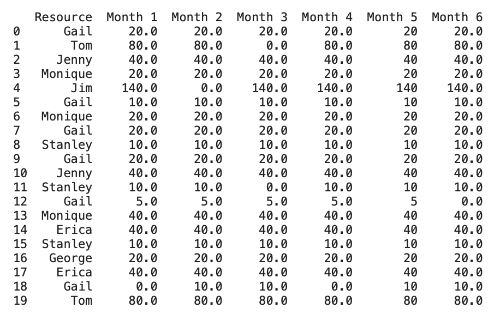
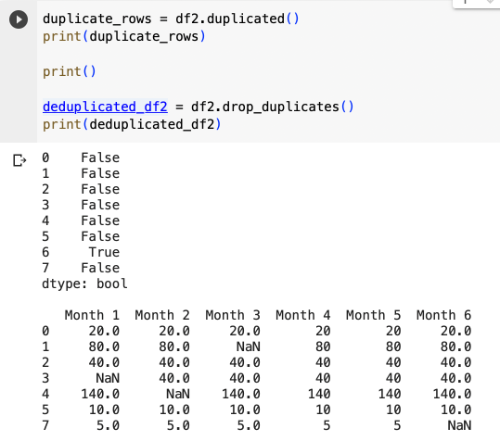
再來稍微修改一下資料,只留下兩行有重複值,然後偵測出重複值,並把重複值刪除:
duplicate_rows = df2.duplicated()
print(duplicate_rows)
print()
deduplicated_df2 = df2.drop_duplicates()
print(deduplicated_df2)
以上就是處理缺失值跟重複值的簡單應用,再來明天會繼續介紹更多技巧!

