在做深度學習的時候,通常會採用自監督式學習的方式去做,也就是會使用 pre-train 的模型來提升效能。舉例來說,在進行影像的分類與分割任務時,最常見的是使用 ImageNet。然而,就有人開始思考,如果不使用不同分布的數據進行預訓練,而是改用半監督式學習的方式,對未標記的數據進行訓練,是否會有更好的效果呢?
因此,今天要來介紹一種半監督學習的演算法,用來對未標記的數據分配標籤!
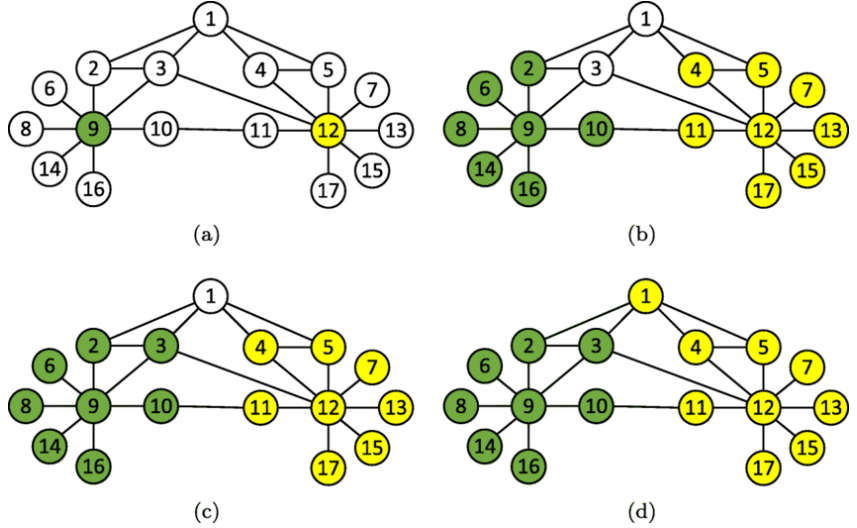
是一種基於圖的半監督式演算法,這個演算法的核心思想是:相似的資料點應該具有相同的標籤
它的運作方式是讓模型根據已知的資訊(標籤)自動學習,並將這些知識擴散到相似的資料點,讓相似的資料點具有相似的標籤。具體而言,它通過產生一個帶有權重邊的圖(Graph),將所有資料點相互連接起來,然後在相鄰的資料點之間傳播標籤。換句話說,資料點之間的相似性和連接性是關鍵因素。如果兩個資料點在空間中靠近,或者它們之間有較強的連接,那麼它們更有可能具有相同的標籤。這個演算法會逐漸將標籤傳播擴散給相似的資料點,直到達到穩定狀態。
LPA 的優點是無需事先知道有多少個標籤,它可以自動適應資料的特性,比較適合數據集具有一定聚類結構或者是相似性結構的情況
Self-training當道:對比Pre-training的優缺點


 iThome鐵人賽
iThome鐵人賽