前面介紹的 P0 事件中,經過調查後,大部分的成因來自於公司外部,因此相對沒有什麼下手的空間。當然,第二個事件中還有 memory leak 的問題,而該問題就可以跟據事件的嚴重程度,以及透過與產品經理的資源協調,來或多或少加快問題解決的速度。
在這次要介紹的事件中,成因大致上就比較能歸責於公司內部了,因此相對來說,也會有更多的施力空間。讀者應該也可以從另一個角度,來看到 SRE 在一些重要的改善事項中,能夠扮演什麼樣子的角色或是起到什麼樣子的作用。
相信各位讀者應該已經很熟悉這個系列事件的開頭,也就是一連串的 P0 警報了。因為這次的警報數量非常多,宛如發生了某種程度的系統雪崩一樣。此外,該事件也發生過至少4次,而每次會發出的警報都有些不同。這邊先羅列並整理如下:
在事件必定會發生的警報:
在事件中常常會伴隨發生的警報:
有時候會接續發生的警報:
之前曾經在「日常維運系列」的「棒球賽」系列文章中提及,筆者認為 SRE 一定程度上就是一個說書人的角色。在此我們又要開始充分發揮這個能力了。因為這些警報的發生時間點都非常相近,而且幾次事件中都以類似的模式出現,因此我們應該可以先預設這些警報彼此之間有些因果關係。
在這個前提之下讀者也許可以先試著想想看,如果給了上面這些條件,應該要怎麼切入並排查問題呢?
從筆者的角度來看,馬上會先出現以下3個猜測:
對於 Web 的成因相對單純,因為該服務本身並沒有出現其它異常警報,只是單純無法存取或異常緩而已。因此經過簡單的調查之後,先是確認了 Web 服務本身沒有問題,並進一步確認了 Web 與 A-API 之間的串接關係。該 API 是服務瀏覽網站而且沒有登入的使用者,因此可以判斷,是因為 A-API 的故障,才導致 Web 的讀取緩慢或無法存取。
至於為什麼會出現伺服器啟動失敗的狀況呢?這件事情其實在「日常維運系列」文章中的「註冊OpsWorks」失敗有提到。因為在短時間內大量向 AWS API 發出請求時,有機會出現請求失敗的狀況。我們透過 UserData 和 LifeCycle Hooks 的解決方案來強迫註冊 OpsWorks 失敗機器要關閉,以避免幽靈機的出現,但關閉的時候會觸發 EC2 啟動失敗的警報。在這個事件中因為有大量機器同時加開的狀況,因此才會出現啟動失敗的警報。
前面有提到,一開始筆者先猜測 A-API 故障的理由來自於請求的飆升,因此一開始是先試著以尋找請求飆升的原因來解決問題的。但翻開 CloudWatch 的圖表後,卻發現完全不是那麼一回事。
請先參照以下一系列與該 API 有關的圖表(橫軸皆為時間):
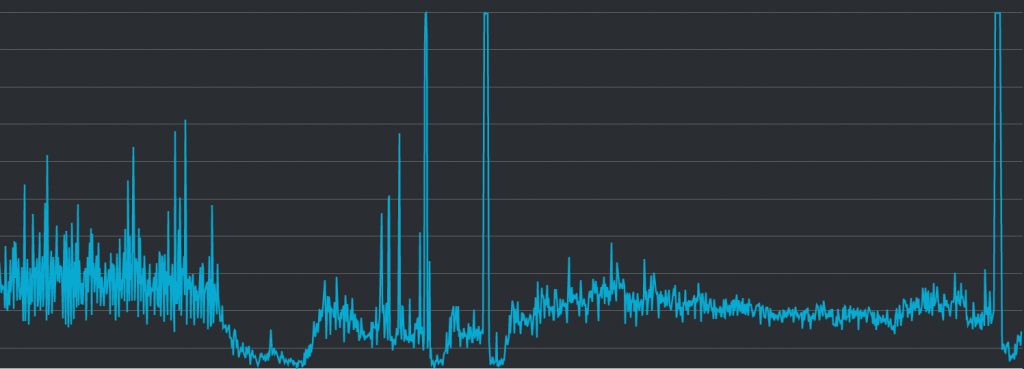
API 伺服器的 CPU 使用量:
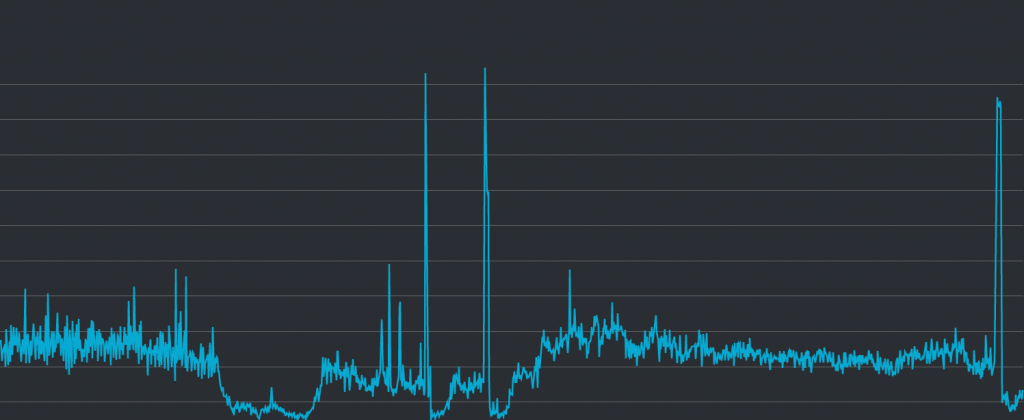
API 伺服器的 Network In:
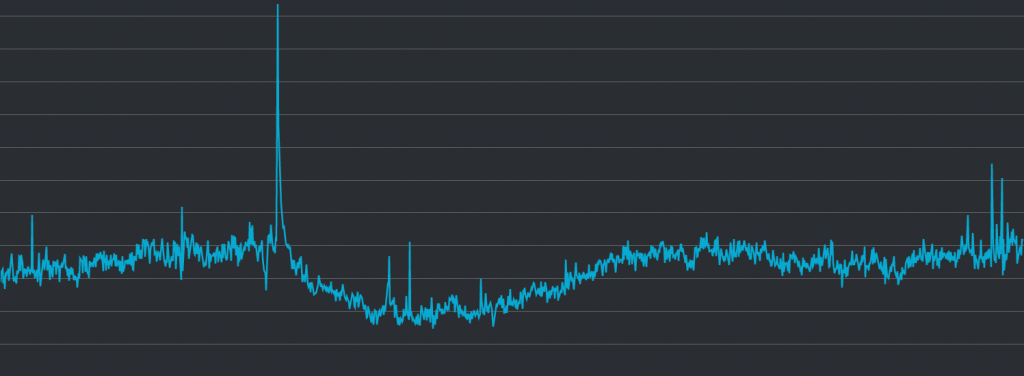
伺服器前面的 Load Balancer 收到的請求量(request counts):
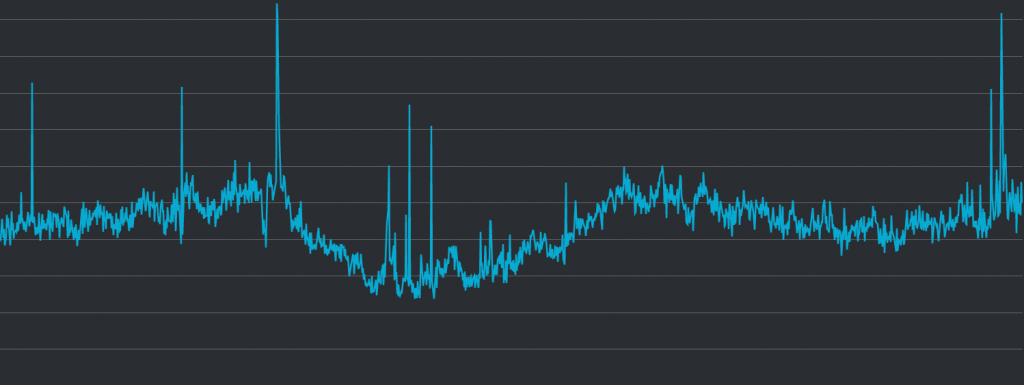
伺服器前面的 Load Balancer 的新連線(new connection)數量:
從第一張圖出發,可以看到 CPU 使用量共有三個異常高起的地方,這與事件發生的時間點一致,可以看出來在這三個時間點的時候,伺服器因為太過繁忙而無法給出回應。
接續看第二張圖,可以看出針對該 API 所啟動的連線的圖表,看起來與 CPU 使用量高度相關,幾乎可以直接判定為有直接的因果關係。也就是說,因為不明原因而導致的大量連線,導致了 CPU 使用量過高的這件事情,應該是可以被肯定的。
然而這個「不明原因」,原本猜測是短時間內的大量請求,卻在接下來的分析中遭遇到了困難。
請接續看第三張圖,因為我們在 EC2 的前面放了 Application Load Balancer (ALB) 來分散流量,因此在原本的猜測中, ALB 的請求數量也應該要出現類似的上升或下降的狀況。但就如圖中所呈現的,我們幾乎可以直接判斷為兩者完全沒有因果關係,因為實在是長得完全不一樣。反而有一個請求量似乎異常升高的地方,但該時間點的當下, API 伺服器其實沒有任何異常。
在接著看第四張圖,在針對 ALB 的新連線數量中,偏左測有一個明顯高起的地方,有對應到第三張圖中的高峰,顯示請求大量出現的時候會導致連線數量飆升。這雖然合理,卻和本次事件看起來沒有任何關係。
不過,第四張圖中也可以看到中間偏左測,以及最右邊,也稍微有一些異常攀升之處,並且似乎與前兩張有關 API 伺服器的折線圖有一些關聯。
這邊看起來能先得到一個不太肯定的猜測。雖然該異常事件與請求飆升可能沒有直接關聯,但 Client 端針對 ALB 的連線似乎可以看出一些端倪。
我們將在下一篇文章中進一步找出成因,並分享解決方法。

