這個 P0 事件是在筆者參賽鐵人賽時發生的,而發生事件的當下,筆者正準備想要趕一下鐵人賽進度^^
這個事件本身與上一篇文章中提到的 P0 事件遵尋一套幾乎一模一樣的規則。來自於 EC2 註冊到 OpsWorks 時,在 OpsWorks 裡執行安裝相關必要需求的時候安裝失敗。因此在一開始收到系統簡報的時候,筆者原本以為只是老毛病又犯了。但在經過日誌查詢後,發現了與之前完全不一樣的錯誤。訊息如下:
[2023-09-12T11:47:14+00:00] ERROR: apt_update[treasure-data] (/opt/chef/embedded/lib/ruby/gems/2.3.0/gems/chef-12.18.31/lib/chef/provider/apt_repository.rb line 59) had an error: Mixlib::ShellOut::ShellCommandFailed: execute[apt-get -q update] (/opt/chef/embedded/lib/ruby/gems/2.3.0/gems/chef-12.18.31/lib/chef/provider/apt_update.rb line 80) had an error: Mixlib::ShellOut::ShellCommandFailed: Expected process to exit with [0], but received '100'
[0m gnutls_handshake() failed: A TLS packet with unexpected length was received.
[0mSTDERR: W: Failed to fetch http://packages.treasuredata.com/3/ubuntu/trusty/dists/trusty/contrib/binary-amd64/Packages gnutls_handshake() failed: A TLS packet with unexpected length was received.
在同一時間,已經下班的同事(負責部署流水線團隊的前輩)傳來了訊息,經過一番討論後,得知該問題其實在其它環境已經有被測試出來,該錯誤會導致 TD-Agent 無法被安裝(我們透過該服務來把 log 丟到 Fluentd server),而只要無法被安裝的錯誤出現,整個部署流程就一定會失敗。
換句話來說,經過初步確認,在沒有經過大修改的情況下,以目前的流水線,沒有任何新的 EC2 有辦法被開起來。這顯然比上一篇文章中所提到的狀況還要嚴重許多,因為在上一篇的狀況裡,只要 Ubuntu 的伺服器修復後,新的 EC2 就可以正常被啟動,但這裡則無法透過緊急處置的方式完全修好這個新伺服器開不起來的問題。
不過,也幸虧於有了上一篇文章中的經驗,筆者馬上進入出問題的幾個服務的 auto-scaling group (ASG),先手動將目前還在運行中的 EC2 ,透過 Scale in Protection 的方式來保護起來。如下圖:
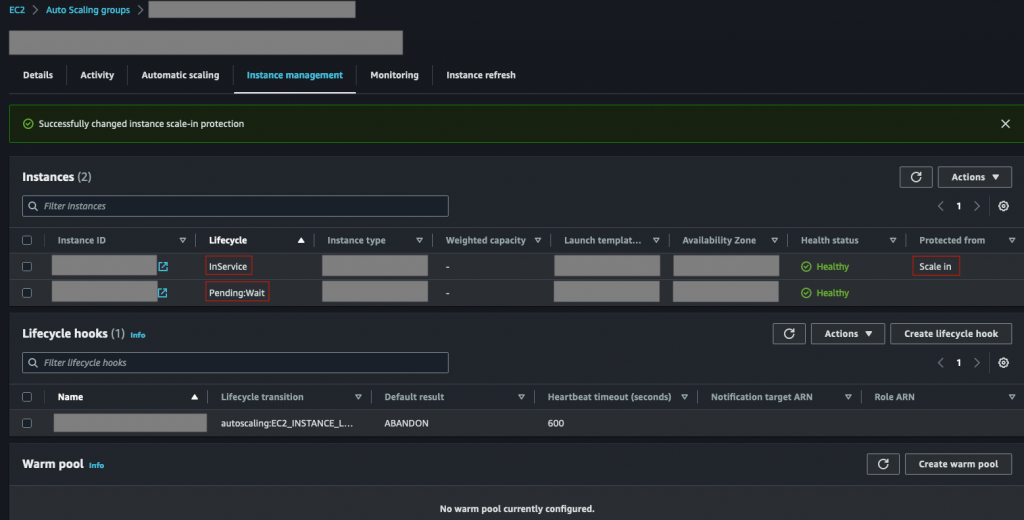
可以在圖中看到,在該 ASG 中有兩台 EC2,而新開的 EC2 因為在 OpsWorks 安裝套件失敗的關係,持續卡在 Lifecycle Hook 的 Pending:Wait 中(與〈日常維運3: 註冊OpsWorks失敗,UserData與LifeCycle Hooks - iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天 (ithome.com.tw)〉中所提到的一樣),一直到 timeout 被 terminate 為止。
而上面那台舊的 InService 的 EC2 ,則透過手動的方式先設定了 Scale in 的保護機制,避免該機器誤被 ASG 關閉,而直接導致系統下線。也因為有 Lifecycle Hook 的關係,Load Balancer 目前不會把流量導向另一台有問題的機器,因此服務雖然可能會有點慢,但還勉強堪用。此外,在當下因為有三支 API 一起撞到這個問題,因此那三支 API 的 ASG 都一起做了相同的設定。
這裡也可以分享在 OpsWorks 主控台界面看到的狀況,如下圖:
麻煩的地方在於,在發生警報的當下,即將要進入該專案的 promotion 活動。事實上,該警報的發生也正是在因應 promotion 而設立的預先加開 EC2 這個過程中所撞到的。由於目前的 EC2 數量絕對無法撐過整個 promotion 活動,而在無法加開新 EC2 的情況下,我們決定要直接原地升級已存在 EC2 的規格。透過垂直擴展來解決無法水平擴展的問題。
原地升級 EC2 的具體步驟如下:
在緊急得到產品經理以及主管的同意後,因為同時間也已經得到了其他資深前輩的關心,所以當下我們就一起協助分工,有人負責換規格,有人負責清除已經開失敗的機器,不同的 API 也分配給不同的人做,雖然已經進入 promotion 了,但最後也還算是及時避免服務直接下線的結果。
不過,其實在整個過程中,因為某些操作上的失誤而導致機器被誤刪掉,因此有一度造成 Pingdom DOWN 的結果。這是因為我們一開始在原地升級的時候,其實並沒有真正遵尋上面描述的步驟,或是說,其實上面描述的步驟是不小心把部分機器關掉之後,再繼續研究而得到的正解。有一支 API 原本尚存 4 台機器,但因為不小心被關掉 2 台機器,在最後 2 台依序升級的時候,就短暫出現了服務無法存取的結果。所幸幾分鐘後就回來了,沒有造成太嚴重的後果。
在筆者寫這篇文章的時候,還沒有找到具體的成因,比較肯定的事情比較算是說,這段應該沒有經過什麼修正的部署程式,突然在某幾段指令就發生錯誤了。
而具體發生錯誤的地方,則分別是以下與 GPG Key 有關的驗證錯誤:
[0m gnutls_handshake() failed: A TLS packet with unexpected length was received.
以及另一個與 treasuredata 的 TLS handshake 失敗:
[0mSTDERR: W: Failed to fetch http://packages.treasuredata.com/3/ubuntu/trusty/dists/trusty/contrib/binary-amd64/Packages gnutls_handshake() failed: A TLS packet with unexpected length was received.
雖然懷疑這與 Ubuntu 過舊有關係,但因為我們在使用的很多套件或甚至作業系統本身都過舊,在早就已經不再受到官方支援的情況下,本來就難以有任何的保證。
由於這裡的目的主要是要安裝 TD-agent,因此目前由其他資源前輩提到來的解方,就是直接到 TD-agent 存放套件的 S3 bucket ,直接手動把需要的套件下載存到我們自己家(應該也是 S3),之後需要該套件時,相關指令則修改成從我們家拿。雖然這會導致無法收取到後續的更新,但因為早就 EOL ,所以本來就不會有相關更新了。
至於後續比較長期的解方,可能則是要依序升級一些必要套件,但除了需要開發與測試的額外人力安排之外,也可能會需要再花點時間研究具體的成因。但至少,目前系統已經可以正常運作了。
在這次的 P0 事件中,除了它本身是一個非常新的事件之外,筆者認為其中最特別之處,就是在於目前該事件的解決方案還停留在短期解方。與上一篇不同的事情是,只要肯投入人力資源進去,其實無論是成因的發現,還是問題的長期解決,都應該是可以預期的。
而筆者主要想分享的事情是,有時候公司基於人力資源的考量,可能會考慮先以比較臨時應對的方式來處理。人力畢竟還是一個非常珍貴的資源,因此會跟據事件優先度上來去進行任務的安排或分配。而在處理類似這樣的系統狀況時,有時候為了節省人力,SRE 也有可能會需要提出一些單純短期用的解決方案。
下一篇,將會是重大 P0 事件簿的最後一個事件。

