網路爬蟲 ( spider 或 web crawler ),是一種可以「自動」瀏覽全球資訊網的網路機器人,許多的搜尋入口網站 ( 例如 Google ),都會透過網路爬蟲收集網路上的各種資訊,進一步分析後成為使用者搜尋的資料,許多開發者也會自行開發不同的爬蟲程式,進行大數據收集與分析的動作。
原文參考:關於網路爬蟲
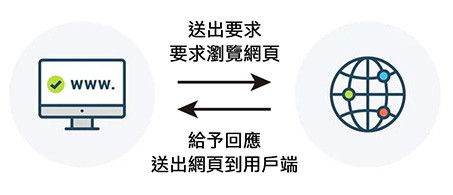
靜態網站是指網站完成一個請求 ( request ) 與回應 ( response ) 後,用戶端即不再與伺服器有任何的交流,所有的互動都只與瀏覽器的網頁互動,資訊不會傳遞到後端伺服器。
通常靜態網站爬蟲比較容易實作,只要爬蟲已經閱讀完整份網頁,就可以取得這個網頁所有的資訊進行分析 ( 如同去餐廳吃飯點了餐,餐送上來之後就可以慢慢品嚐 )。
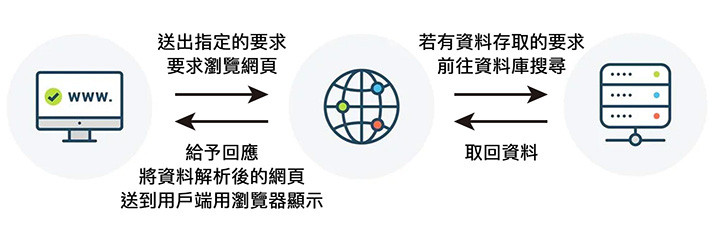
動態網站是指網站會依照使用者的行為不斷的與伺服器進行交流,例如傳送了 apple 資訊給伺服器,資訊經過伺服器處理後,才會回應 apple 是甜的、紅的、脆的...等相關資訊,不少動態網站甚至需要進行「登入」的動作,像是 Facebook、Instagram...等。
通常動態網站爬蟲實作比較複雜,爬蟲必須要知道網站需要什麼「資訊」,提供了正確的資訊,才能取得所需要的資料 ( 如同開啟保險箱一般,輸入了正確的密碼,才能開啟保險箱的內容 )。
網路爬蟲可以透過過程式「自動抓取」網站資料,所以能夠取代許多純人工手動取得資料的過程,大幅節省時間,以下列舉幾種相關的應用:
單純使用網路爬蟲並不違法,但如果過度使用網路爬蟲,造成伺服器過大的負擔,或者透過爬蟲搭配駭客技術來攻擊網站,就有可能因此違法,所以在使用網路爬蟲時,需要注意相關的禮儀:
不造成網站伺服器的負擔
每次爬取資料時,設定適當的等待延遲,避免短時間內送出大量的請求而造成伺服器的負擔 ( DDoS 攻擊,根據刑法第 360 條可能會觸法 )。
確認網站是否有提供 API
如果網站有提供 API 供第三方直接取得資料,可以直接透過 API 抓取資料,節省讀取與分析網站 HTML 的時間。
注意 robots.txt
robots.txt 會規範一個網站允許什麼樣的 User-Agent 訪問,也會規範 Crawl-delay 訪問間隔時間,如果 Crawl-delay 設定 1,表示這個網站期望每次訪問的時間間隔一秒鐘。
大家好,我是 OXXO,是個即將邁入中年的斜槓青年,我有個超過一千篇教學的 STEAM 教育學習網,有興趣可以參考下方連結呦~ ^_^

