「反爬蟲」主要是針對「惡意的爬蟲程式」所設計的防堵技術,許多網站為了保護資料或減少網頁負擔,多少都會加入一些「反爬蟲」機制,本篇教學將會介紹一些破解反爬蟲的方法,可以針對一些簡單的反爬蟲機制,進行對應的處理。
原文參考:破解反爬蟲的方法
執行 selenium 會啟動 chromedriver,所以所以請使用本機環境 ( 參考:使用 Python 虛擬環境 ) 或使用 Anaconda Jupyter 進行實作 ( 參考:使用 Anaconda ) 。
「反爬蟲」主要是針對「惡意的爬蟲程式」所設計的防堵技術,許多網站為了保護資料、減少網頁負擔、或避免網頁上的公開資訊被網頁爬蟲給抓取,多少都會押入一些「反爬蟲」機制,常見的反爬蟲機制有下列幾種:
判斷瀏覽器 headers 資訊
利用 headers 判斷來源是否合法,headers 通常會由瀏覽器自動產生,直接透過程式所發出的請求預設沒有 headers,破解難度:低。
使用動態頁面
將網頁內容全部由動態產生,大幅增加爬蟲處理網頁結構的複雜度,破解難度:中低。
加入使用者行為判斷
在網頁的某些元素,加入使用者行為的判斷,例如滑鼠移動順序、滑鼠是否接觸...等,增加爬蟲處理的難度,破解難度:中。
模擬真實用戶登入授權
在使用者登入時,會將使用者的授權 ( token ) 加入瀏覽器的 Cookie 當中,藉由判斷 Cookie 確認使用者是否合法,破解難度:中。
加入驗證碼機制
相當常見的驗證機制,可相當程度的防堵惡意的干擾與攻擊,對於非人類操作與大量頻繁操作都有不錯的防範機制 ( 例如防堵高鐵搶票、演唱會搶票...等 ),破解難度:高。
封鎖代理伺服器與第三方 IP
針對惡意攻擊的 IP 進行封鎖,破解難度:高
針對「判斷瀏覽器 headers 資訊」的網頁,只要能透過爬蟲程式,送出模擬瀏覽器的 headers 資訊,就能進行破解。
模擬 headers 常用的內容:
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36或
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15
使用 Requests 函式庫:
import requests
url = '要爬的網址'
# 假的 headers 資訊
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'}
# 加入 headers 資訊
web = requests.get(url, headers=headers)
web.encoding = 'utf8'
print(web.text)
使用 Selenium 函式庫:
from selenium import webdriver
# 假的 headers 資訊
user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.3 Safari/605.1.15"
opt = webdriver.ChromeOptions()
# 加入 headers 資訊
opt.add_argument('--user-agent=%s' % user_agent)
driver = webdriver.Chrome('./chromedriver', options=opt)
driver.get('要爬的網址')
有些反爬蟲的網頁,會檢測瀏覽器的 window.navigator 是否包含 webdriver 屬性,在正常使用瀏覽器的情況下,webdriver 屬性是 undefined,一旦使用了 selenium 函式庫,這個屬性就被初始化為 true,只要藉由 Javascript 判斷這個屬性,就能簡單的進行反爬蟲。
下方的程式使用 selenium webdriver 的 execute_cdp_cmd 的方法,將 webdriver 設定為 undefined,就能避開這個檢查機制。
from selenium import webdriver
driver = webdriver.Chrome('./chromedriver')
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
針對「使用動態頁面」的網頁,只要確認動態頁面的架構,就能進行破解,如果打開的網頁是動態頁面,「檢視網頁原始碼」時看到的結構往往會很簡單,通常都只會是一些簡單的 HTML、CSS 和壓縮過的 js 文件。

這時可以使用 Chrome 開啟網頁,在網頁任意位置按下滑鼠右鍵,選擇「檢視」,開啟 Chrome 開發者工具,從中就能看到動態網頁載入後的完整架構。
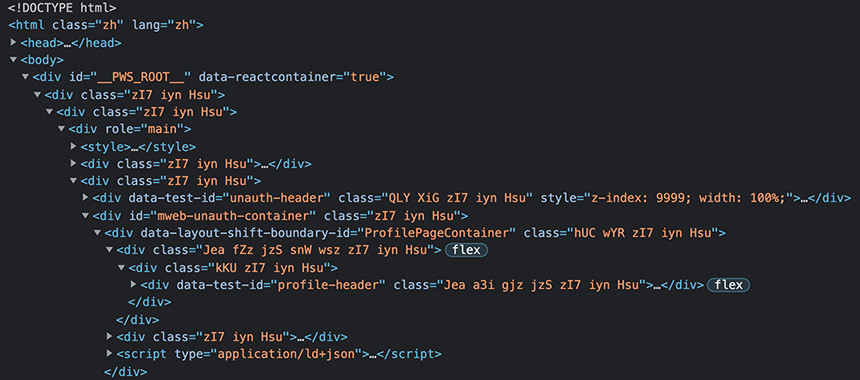
取得網頁結構後,進一步分析網頁結構,下方的程式使用 Selenium 函式庫的功能,抓取特定的網頁元素或進行指定的動作。
from selenium import webdriver
driver = webdriver.Chrome('./chromedriver')
driver.get('爬取的網址')
# 從載入後的動態網頁裡,找到指定的元素
imgCount = driver.find_element(By.CSS_SELECTOR, 'CSS 選擇器')
針對「加入使用者行為判斷」的網頁,確認頁面加入的使用者行為,就能模擬並進行破解,舉例來說,有些網頁會在按鈕加上「滑鼠碰觸」的保護,如果不是真的用滑鼠碰觸,只是用程式撰寫「點擊」指令,就會被當作爬蟲而被阻擋。
下方的程式使用 Selenium 函式庫的功能,模擬出先碰觸元素,再進行點擊的動作,藉此突破這個反爬蟲的機制。
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
submitBtn = driver.find_element(By.CSS_SELECTOR, '#submitBtn')
actions = ActionChains(driver)
# 滑鼠先移到 submitBtn 上,然後再點擊 submitBtn
actions.move_to_element(submitBtn).click(submitBtn)
actions.perform()
有些網頁也會判斷使用者刷新網頁的時間 ( 通常使用者不會在極短的時間內連續刷新 ),這時也可以使用 time 函式庫的 sleep 方法讓網頁有所等待,避開這個檢查機制
from selenium import webdriver
from time import sleep
submitBtn = driver.find_element(By.CSS_SELECTOR, '#submitBtn')
sleep(1) # 等待一秒
submitBtn.click()
sleep(0.5) # 等待 0.5 秒
submitBtn.click()
針對「模擬真實用戶登入授權」的網頁,只要知道 request 與 response 的機制後,取得 Cookie 內的 token 就能破解。舉例來說,下圖為 Ptt 八卦版網頁,從 Chrome 開發者工具裡可以看到所需要的 Cookies 資訊。
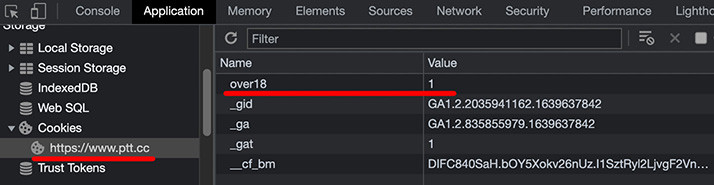
知道所需的 cookies 資訊後,就能在 Requests 函式庫裡,增加相對應的資訊,就能順利爬取到資料。
import requests
cookies = {'over18':'1'}
# 加入 Cookies 資訊
web = requests.get('https://www.ptt.cc/bbs/Gossiping/index.html', cookies=cookies)
print(web.text)
針對「加入驗證碼機制」的網頁,必須搭配一些 AI 來處理圖形、數字、文字的識別,通常只要能識別驗證碼就能破解。如果要破解一般驗證碼,需要先將網頁上的驗證碼圖片下載,再將圖片提交到 2Captcha 服務來幫我們進行辨識,等同於執行兩次爬蟲,先爬取目標網頁,在爬取 2Captcha 網頁取得辨識後的驗證碼,最後再把驗證把輸入目標網頁。
因為步驟較為繁複,會用另外的篇幅介紹,此處僅介紹相關的原理。
2Captcha 服務:https://2captcha.com/
針對「封鎖代理伺服器與第三方 IP」的網頁,通常必須更換 IP 或更換代理伺服器才能破解,許多網站上也有提供免費的 Proxy IP,以 Free Proxy List 網站為例,就能取得許多免費的 Proxy IP。
Free Proxy List:https://free-proxy-list.net/
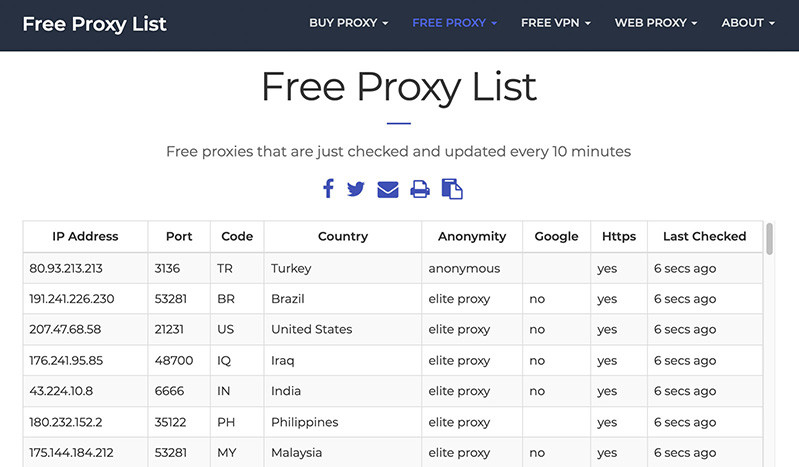
下方的程式碼會透過代理伺服器 IP 的方式,執行 requests 函式庫的 get 方法,如果該 IP 已經無法使用,就會出現 invalid 的提示。
import requests
# 建立 Proxy List
proxy_ips = ['80.93.213.213:3136',
'191.241.226.230:53281',
'207.47.68.58:21231',
'176.241.95.85:48700'
]
# 依序執行 get 方法
for ip in proxy_ips:
try:
result = requests.get('https://www.google.com', proxies={'http': 'ip', 'https': ip})
print(result.text)
except:
print(f"{ip} invalid")
其實反爬蟲的機制非常的多變 ( 甚至有些還會用一問一答的方式 ),不過也有很多網站沒有加上反爬蟲的保護,甚至直接提供了 API 的方式來讓爬蟲獲取資料,總而言之,如果有 API 就直接取用,如果沒有 API 又遇上反爬蟲,就只能針對反爬蟲的機制,採取對應的措施了。
大家好,我是 OXXO,是個即將邁入中年的斜槓青年,我有個超過一千篇教學的 STEAM 教育學習網,有興趣可以參考下方連結呦~ ^_^


 iThome鐵人賽
iThome鐵人賽