接著我會介紹專案可能會用到的兩個模型
DETR 是我可能會用到的 RT-DETR的初始模型,以下是相關的介紹
DETR(Detection Transformer)是一種基於Transformer架構的新穎物體檢測模型,由Facebook AI於2020年提出。與傳統的物體檢測模型(如Faster R-CNN,YOLO等)不同,DETR採用了一種全新的檢測機制,並利用了Transformer的自注意力機制來捕捉圖像中不同位置間的相互關係。
以下是DETR模型的一些主要特點和組件:
DETR是一個端到端訓練的模型,它不依賴於傳統的區域提議網絡(RPN)和非極大值抑制(NMS)等手段,從而簡化了物體檢測流程。
DETR利用了Transformer架構,該架構最初被設計用於自然語言處理(NLP)任務,但在DETR中得到了成功的應用。Transformer幫助模型理解圖像中的上下文信息,並處理物體之間的關係。
DETR引入了一種名為雙邊匹配損失(Bipartite Matching Loss)的新型損失函數,用於在訓練過程中匹配預測邊界框和真實邊界框。這種方法解決了物體檢測中的賦值問題。
DETR使用一種稱為「無物體類別」("no object" class)的機制來區分圖像中的物體和背景,這有助於模型更準確地進行物體檢測。
DETR利用卷積神經網絡(CNN)提取多尺度的特徵表示,並將這些特徵融合到Transformer中,以捕捉不同大小和形狀的物體。
通過自注意力機制,DETR能夠全局地理解圖像,這使得模型能夠處理一些複雜的場景和遮擋情況。
DETR在提出時展示了與當時領先的物體檢測模型相當的性能,同時提供了一種新穎且統一的檢測架構。由於其獨特的設計和優異的性能,DETR已成為計算機視覺領域的重要研究對象。
DETR(DE tection TR ansformer)的 PyTorch 訓練程式碼和預訓練模型。此模型用 Transformer 取代了完整複雜的手工製作的目標檢測管道,並將 Faster R-CNN 與 ResNet-50 相匹配,使用一半的計算能力 (FLOPs) 和相同數量的參數在 COCO 上獲得42 AP 。用 50 行 PyTorch 進行推理。

與傳統的電腦視覺技術不同,DETR 將物件偵測作為直接作為預測問題來處理。它由基於集合的全局損失(透過二分匹配強制進行預測)和 Transformer 編碼器-解碼器架構組成,給定一小組固定的學習對象查詢集,DETR 會推理物件與全域影像上下文的關係,以直接並行輸出最終的預測集。DETR 由於這種並行特性非常快速且有效率。
關於代碼。官方認為物件偵測不應該比分類更困難,也不應該需要複雜的函式庫來進行訓練和推理。DETR 的實作和實驗非常簡單,官方提供了一個Colab Notebook, 展示如何只用幾行 PyTorch 程式碼即可使用 DETR 進行推理。訓練程式碼遵循這個想法 - 它不是一個庫,而只是一個main.py,使用標準訓練循環導入模型和標準定義。
有關詳細信息,請參閱 Nicolas Carion、Francisco Massa、Gabriel Synnaeve、Nicolas Usunier、Alexander Kirillov 和 Sergey Zagoruyko 編寫的[《Transformers 端到端物件檢測》](End-to-End Object Detection with Transformers) 。
參考:https://github.com/facebookresearch/detr
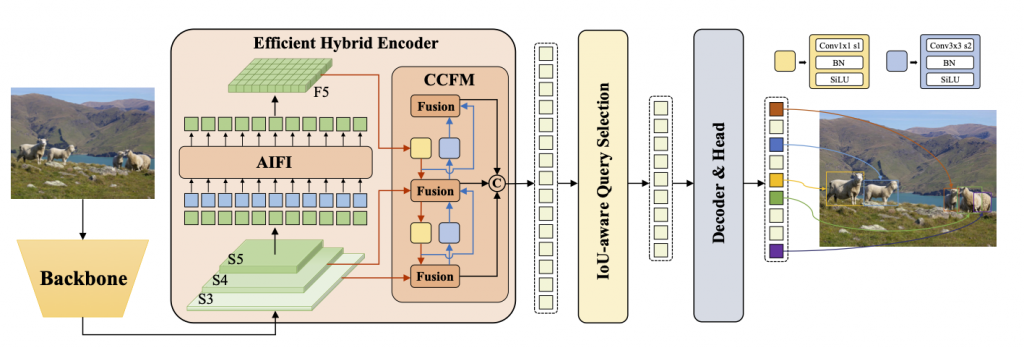
即時偵測變壓器(RT-DETR)由百度開發,是一款尖端的端對端物體偵測器,可在提供即時效能的同時保持高精度。它利用視覺變換器(ViT)的技術,透過解耦尺度內互動和跨尺度融合來高效處理多尺度特徵。RT-DETR具有很強的適應性,支援使用不同解碼器層靈活調整推理速度,而無需重新訓練。該模型在特定後端(例如具有 TensorRT 的 CUDA)上表現出色,優於許多其他即時物件偵測器。
百度RT-DETR概述。RT-DETR模型架構圖顯示了骨幹網路的最後三個階段{S3,S4,S5}作為編碼器的輸入。高效率的混合編碼器透過尺度內特徵交互作用 AIFI)和跨尺度特徵融合模組(CCFM)將多尺度特徵轉換為影像特徵序列。IoU 感知查詢選擇用於選擇固定數量的圖像特徵作為解碼器的初始物件查詢。最後,具有輔助預測頭的解碼器迭代最佳化物件查詢以產生框和置信度分數(來源)。
主要的功能:
高效的混合編碼器:百度的RT-DETR採用高效率混合編碼器,透過解耦尺度內互動和跨尺度融合來處理多尺度特徵。這種獨特的基於 Vision Transformers 的設計降低了計算成本,並允許即時物件偵測。
IoU 感知查詢選擇:百度的 RT-DETR 透過利用 IoU 感知查詢選擇來改進物件查詢初始化。這使得模型能夠專注於場景中最相關的對象,從而提高檢測精度。
推理速度自適應:百度的RT-DETR支援透過使用不同的解碼層靈活調整推理速度,無需重新訓練。這種適應性有助於在各種即時目標偵測場景中的實際應用。
我這邊的實作會使用 Ultralytics (yolo v8 的開發公司)的 API 訓練跟開發。
以下是可能會用到的,但不一定絕對會實裝
(我知道這不是物體檢測,是影像分割方向的模型)
Segment Anything Model(SAM)是一種尖端的影像分割模型,可進行快速分割,為影像分析任務提供無與倫比的多功能性。SAM 構成了 Segment Anything 計畫的核心,這是一個開創性的項目,引入了用於影像分割的新穎模型、任務和資料集。
SAM 的先進設計使其能夠在無需先驗知識的情況下適應新的影像分佈和任務,這項功能稱為零樣本傳輸。SAM 在龐大的SA-1B 資料集上進行訓練,該資料集包含超過10 億個掩模,分佈在1100 萬張精心策劃的圖像中,SAM 表現出了令人印象深刻的零樣本性能,在許多情況下超越了先前完全監督的結果。
Segment Anything 的主要特色:
若要深入了解 Segment Anything 模型和 SA-1B 資料集,請造訪Segment Anything 官網並查看研究論文Segment Anything。
MobileSAM 論文現已在arXiv 看到。
Mac i5 CPU 上的效能大約需要 3 秒。在 Hugging Face 演示中(目前不能用 呵呵),介面和效能較低的 CPU 導致響應速度較慢,但它仍然可以有效運作。
這邊我也會以 Ultralytics 他家的APi實作看看。

