正規化
當你現在想找出兩個(以上)數據或特徵的之間關係時,為了不要被單位影響,會把這兩者的數據範圍放到同一個尺度下以利觀察,這就是正規化(Normalize)的基本目的
主要還是為了
假如你現在想觀察資料的兩個特徵,但這兩個特徵(w, b)的變化量差異極大,變化幅度不同
以下圖為例: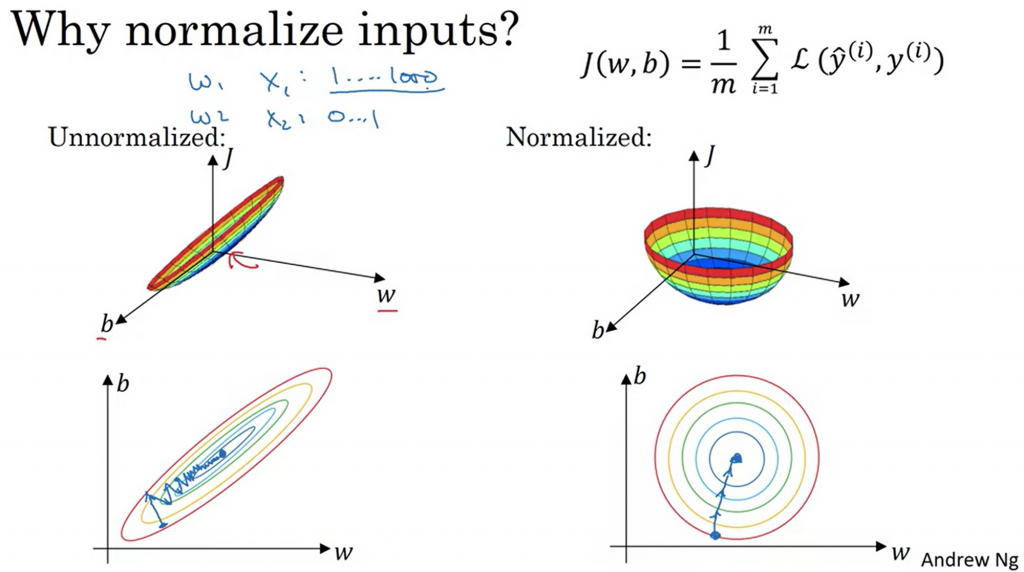
左圖沒有經過正則化的原始數據,右邊則是經過正則化後的樣子
底下兩張則是在做 Gradient Descent 的圖,可以看到沒有正則化前的路線比較曲折,沒那麼順暢
正則化後也能加速 GD 的進行過程
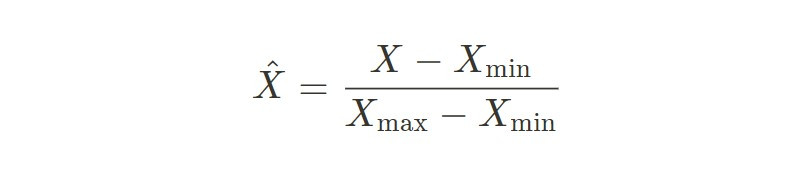
X hat 為正規化後的數據,用這個方法可以將 X hat 通通打到 [0, 1] 區間裡面
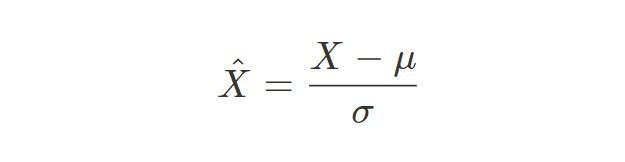
這方法則是可以將正則化後的數據平均數變成0,標準差變成1
以上就是簡短的介紹


 iThome鐵人賽
iThome鐵人賽