上一篇提到的 Variance 過高可能會發生 Overfitting 的問題,為了解決 Overfitting,因此我們採用正規化( Regularization)來處理
以結果而言,Regularization 就是在 Loss function 加上一個 penalty(一個數字),來限制範圍
這邊分成兩種:
L1, L2 其實只差在要用哪個 Norm 來計算 penalty
我這句話會不會反而讓大家更搞混 :P
我在想能不能表示:
Cost function 就是 Loss function 的總和
後面的 L1 即為 penalty term = Regularization Term ,控制模型的複雜性
也被稱作 Weight Decay
用的是 L2-norm 同時也叫做 Forbenius norm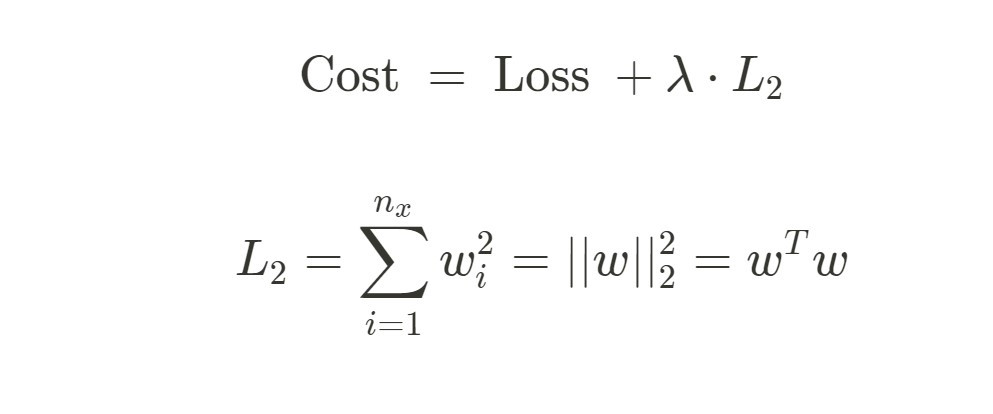
這是另外一個正規化的方法,目的是減少 Neuron 的數量,以避免 Overfitting
以這張圖為例: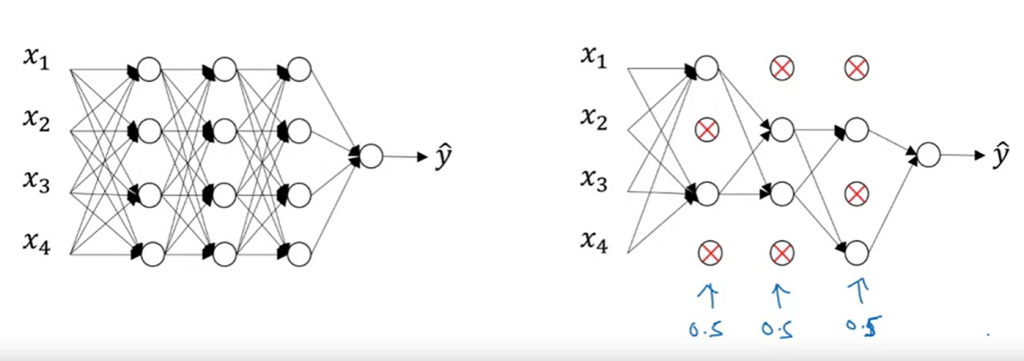
左邊是原本的 NN,我們每一層保留的機率設為 50%,因此平均下來砍掉了一半的 Neuron
寫得很淺很淺
這邊打 真的很出車禍,終於懂為何大家都用圖片了


 iThome鐵人賽
iThome鐵人賽