
如果你是 PostgreSQL 的使用者,那麼使用 extension pgvector 就是入門最好的方法。PostgreSQL 是一個開源的對象關聯型資料庫管理系統(ORDBMS),它提供了 SQL 查詢語言的實現。由於其性能強大、功能多樣、社群支援完成,也因此成為很主流的資料庫之一。
將 PostgreSQL 和 pgvector 結合在一起,可以發揮出的 ORDBMS 的優勢,並專門用於處理向量數據,從而創建一個在性能和功能方面表現出色的多功能數據存儲解決方案。但是唯一的缺點是慢,不過如果你的資料量沒有大會有顯著的校能瓶頸的話,其實可以用 PostgreSQL 就很夠了。
ankane/pgvector 這個 image,並用 docker-compose.yml 來建立環境。並且使用 docker-compose up -d 這個指令執行這個 yaml 檔。version: '3'
services:
db:
image: ankane/pgvector
restart: always
environment:
POSTGRES_USER: user
POSTGRES_PASSWORD: password
POSTGRES_DB: vector
volumes:
- ./data:/var/lib/postgresql/data
ports:
- '5432:5432'
安裝 pgAdmin,這個這個 PostgreSQL 常用的管理工具。如果沒有安裝過的話,可以去這裡下載 https://www.pgadmin.org/
安裝完成 pgAdmin 之後,使用 docker-compose 中設定的帳號密碼和 port number,連線到 PostgreSQL 資料庫。
接著我們直接利用 pgAdmin 的管理介面的優勢,直接把 pgvector 這個 extension 安裝進去。如下圖所示。
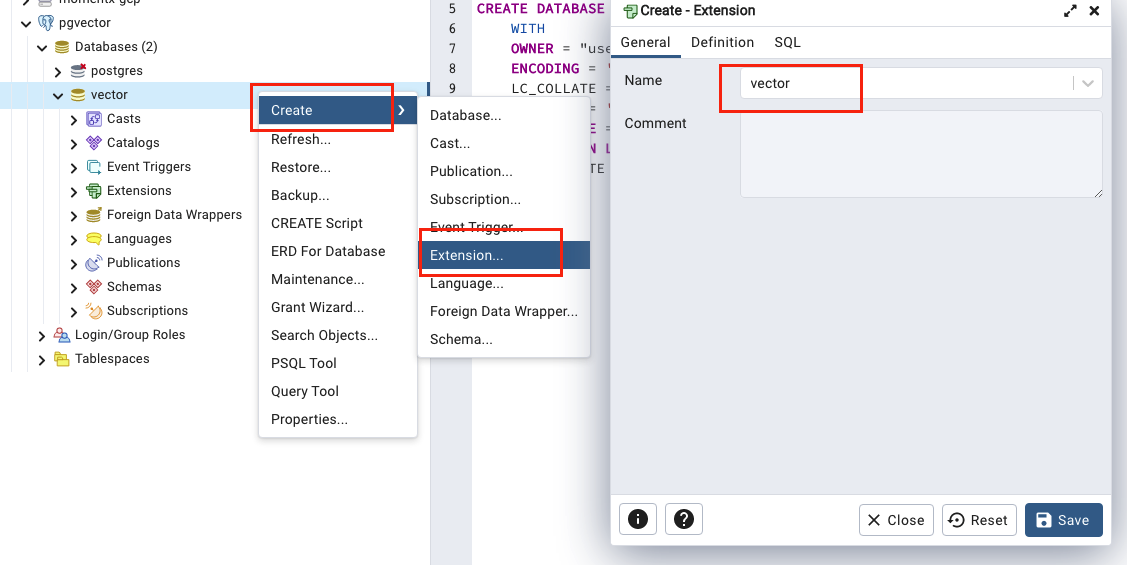
當然你也可以使用指令來安裝 CREATE EXTENSION IF NOT EXISTS vector;
接著我們來做個簡單的測試。我們先建了一張帶有 embedding 欄位的 table,使用指令 CREATE TABLE items (id bigserial PRIMARY KEY, embedding vector(3));。指令中的 vector(3) 就是三個維度的向量。
接著我們插入兩筆資料,使用指令 INSERT INTO items (embedding) VALUES ('[1, 0, 0.1]'), ('[1, 0, -0.1]');。這都是 SQL 的指令,要增刪改都可以用類似的邏輯。
和增刪改一樣,查詢向量可以用 select 指令。
我們使用指令 SELECT * FROM items ORDER BY embedding <-> '[1, 1, 0.1]' LIMIT 2;
可以得到:
id, embedding
2, "[1,0,0.1]"
1, "[1,0,-0.1]"
這是我們預想中的結果,[1, 1, 0.1] 向量的確比較接近我們剛剛存入的 [1,0,0.1]。這裡的 <-> 是歐幾里德距離。
我們也可以直接列出歐幾里德距離,使用指令 SELECT embedding <-> '[1, 1, 0.1]' AS distance FROM items;,這樣會得到結果 1 和 1.0198038840154646。
我們也可以用 <=> 來取得 cosine 距離。只要把上面的指令的運算子換成 <=> 即可。
如果要從 cosine 距離轉換成 cosine similarity 的話,可以使用指令 SELECT 1 - (embedding <=> '[1, 1, 0.1]') AS cosine_similarity FROM items;
如果要用內積法的話,運算子是 <#>。不過這個因為 PostgreSQL 的限制,只會回傳負值。不過也沒關係,我們在做 LLM 時用到的機會相對小一點。
Pgvector 支援兩種搜尋的演算法,IVFFlat 和 HNSW。
IVFFlat 較適用於有限的資源和需要快速建立索引的場景,但可能需要進一步優化以達到較高的查詢性能。
HNSW 在查詢性能方面較佳,但需要更多的時間和內存來建立索引,這可能在有充足資源和對高性能有嚴格要求的場景下是可以接受的。
一般來說大家比較會使用 HNSW ,不過也是需要看你的應用場景而定。
要使用 HNSW 的話,可以用這個指令 CREATE INDEX ON items USING hnsw (embedding vector_cosine_ops);
需注意如果要這麼做的話,pgvector 只支援到 2000 個維度。還好 OpenAI 的 text-embedding-ada-002 的維度是 1536 維。
明天開始我們來講怎麼使用 Python 來操作 pgvector,一樣會使用 text-embedding-ada-002。

 iThome鐵人賽
iThome鐵人賽