
為什麼我們要寫pipeline?其實理由很單純,那就是要提升開發人員體驗,增加開發能量。
要知道,去人力資源市場上看看,一個開發人員的用人成本,跟一般非技術性的用人成本絕對有落差。更何況一個強者,如果整天叫他去做一些雜務,開發體驗很差的狀況,很容易他就跟你說掰掰了。
在我們這裡,以前沒有azure devops的時候,如同之前說的自己寫好的程式,自己想辦法用遠端桌面連線丟到測試環境去給使用者測試。你要做的事情不過是 打開遠端桌面連線->找到對的ip->找出自己可能忘記的測試環境帳號密碼->找到不見得還記得的IIS佈署位置->整包給他貼過去。
萬一user又報了一個Bug,你又幫他開發完了,上面那堆事情又要再做一次。那萬一你跟另外一個同事共同開發怎麼辦?
這一切真的很麻煩
所以去年開始我們就在測試環境建立共同使用的gitlab,讓兩人以上開發的專案領先享受git repo共同開發以及pipeline自動化佈署到測試環境的甜頭,當然也是有遇到一些問題。
就如同前一天我說的,之前負責撰寫pipeline yaml的我,與當時source code 跟yaml住在同一個repo的時候,可能因為沒有好好設計,所以一直不斷互相打擾,例如我要驗證我的yaml到底可不可以好好跑,實驗的過程一定會把yaml寫壞的時候,剛好開發人員source code 準備要cicd到測試環境,就壞掉了。
雖說大家人都很好,弄壞了趕快修就好,但是這種相互打擾的狀態,其實對於開發的速度一定會有影響。
這一次在Azure DevOps Service上就採取了pipeline獨立一個repo,盡量讓兩邊不會互相干擾。
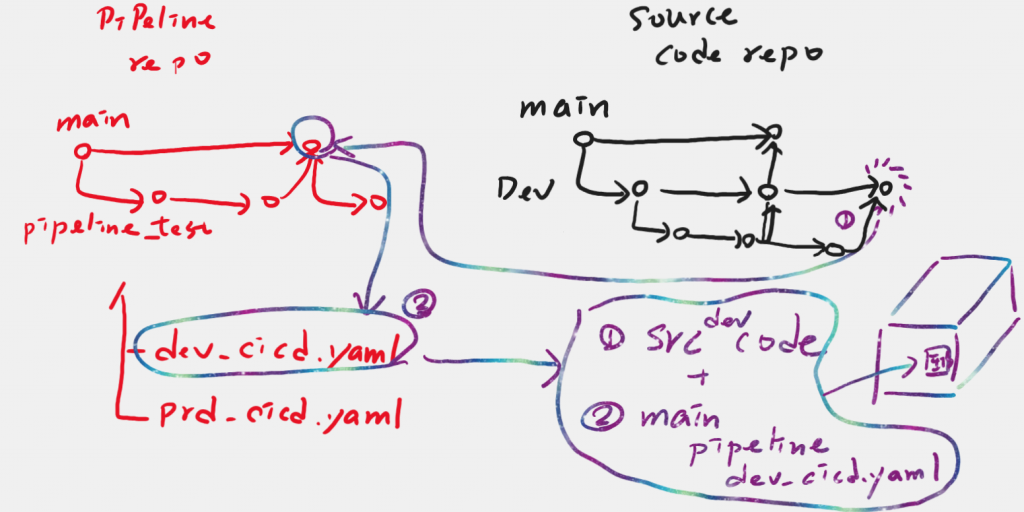
上圖就採取了兩個repo的策略,我簡單介紹如下:
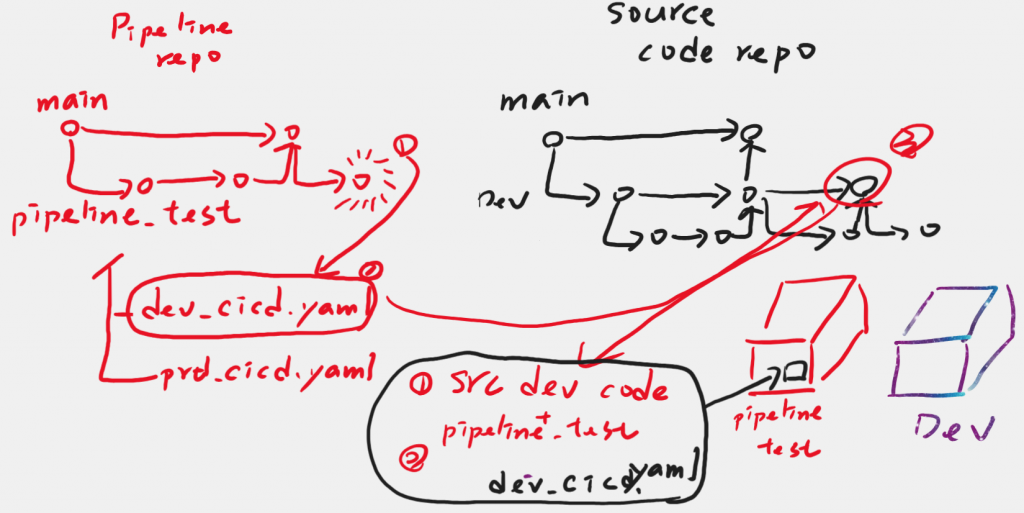
上圖則是代表著,Ops這邊在開發pipeline的狀態,在pipeline_test的這個branch,更新都會對應到另外一台主機,讓Ops確定他所寫出來的yaml可以正常的被執行。
上面這兩種的設計方式,基本上就可以達到我想要做的,最低程度打擾開發人員的目的。Developer與他的使用者為了需求本身頻繁的互動,Operator 則可以專心在他的pipeline yaml中進行實驗與設計。
前陣子才在激烈的討論,到底pipeline的yaml審核,到底要不要像source code一樣,做金融業嚴格的 科員->組長->科長這樣的審核呢?其實沒有一個答案。其實我們是ap單位,有一點點像是developer的開發工作,但是卻又兼著operator負責維運的作業。
source code的層層review,其實工作負擔已經越來越重了,更何況程式語言百百種,我簡單盤點一下光.net framework 從2.0~4.8都有,內部.net core從3.1~6也有,Java 6-8,前端語言根據我聽過的,三大前端框架全部都有,jquery也有,python、nodejs等等....我只確定沒有php,其他你想的到的我們這裡都有。
要知道,認知負荷這件事情是有極限的,就算再神也很難精通這麼多的語言,更何況後來又出現了docker,所以要看dockerfile,然後k8s也跑出來,又要看yaml,然後有廠商用podman、Docker Swarm........沒完沒了。
以筆者目前的意見是,審核的目的當然是以防出錯了,既然要有能力看出是否有出錯,那至少在一個領域(如現在提及的pipeline yaml)要有可以相互協助的一對人,這樣才可以在Pull Request的時候有辦法進行審核與討論。
而且有關於Ops在維護的yaml,我比較把它定義成環境設定檔,不同的環境會有不同對應的檔案,最新的版本就是在main中,用檔案分開,可以看上面那兩張圖都有出現dev與prod都是不同的檔案。
到最後,我們決定只有main接受branch policy的保護,需要經過pull request才可以進版。
好,終於,可以準備要來寫pipeline了

 iThome鐵人賽
iThome鐵人賽