昨天介紹了 QoS (Quality of Service) 與 存活探針(Liveness), 就緒探針(Readiness) and 啟動探針(Startup Probes),今天我們來介紹一個能減少服務中斷時間的措施 - Graceful -shutdown
再解釋為什麼做 Graceful-shutdown 之前,需要簡略介紹一下 Service 為什麼能把流量分配到 Pod 的。
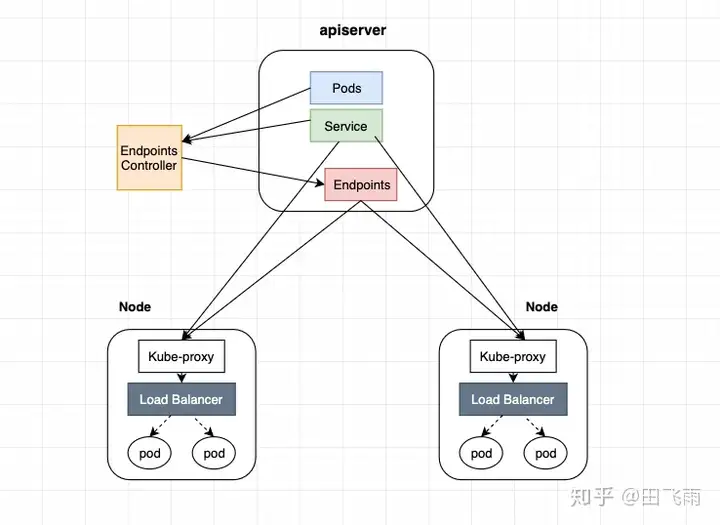
圖檔來自 田飞雨 / kubernetes service 原理解析
流量分配與負載均衡依賴以下三個組件來實現
隨便挑個 Pod,透過 -o wide 檢視 Pod IP
kubectl get pod -o wide -l app=demo-deployment
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
demo-deployment-767f4b86d9-jvmj5 1/1 Running 0 2d5h 10.244.1.13 my-cluster-worker <none> <none>
能看到這個 Pod 被隨機分配的 IP是 10.244.1.13
我們來檢視 service 與 endpoints 物件
kubectl get svc,ep demo-deployment
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/demo-deployment ClusterIP 10.96.86.32 <none> 8080/TCP 36s
NAME ENDPOINTS AGE
endpoints/demo-deployment 10.244.1.13:8080 36s
能看到 service 是被綁定了一個 CLUSTER-IP,來提供負載均衡的端點。而 Pod IP 被綁定在 endpoints 上。
讓我們增加幾個 Pod,看是否 endpoints 會更新 IP List
kubectl scale deployment demo-deployment --replicas=3
kubectl get pod -o wide -l app=demo-deployment
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
demo-deployment-767f4b86d9-dxc9v 1/1 Running 0 79s 10.244.1.49 my-cluster-worker <none> <none>
demo-deployment-767f4b86d9-jvmj5 1/1 Running 0 2d5h 10.244.1.13 my-cluster-worker <none> <none>
demo-deployment-767f4b86d9-q7ls7 1/1 Running 0 79s 10.244.1.48 my-cluster-worker <none> <none>
能看到共有 3 個 Pod,分別被隨機分配到一個 IP
10.244.1.49
10.244.1.13
10.244.1.48
再查一次 service, endpoints 看看是否有變化
kubectl get svc,ep demo-deployment
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/demo-deployment ClusterIP 10.96.86.32 <none> 8080/TCP 8m34s
NAME ENDPOINTS AGE
endpoints/demo-deployment 10.244.1.13:8080,10.244.1.48:8080,10.244.1.49:8080 8m34s
能看到 endpoints 的服務發現機制,感知到有三個新的 Pod 被建立,並且收集到該 Pod IP,代表後續 Service 收到請求後,會隨機分配流量到這三個 Pod。
如果想更確認 iptable 的配置是否正確,也能透過 docker exec 到 worker node 節點中確認
docker exec -it ${k8s worker node container id} /bin/bash
iptables -t nat -L -n -v | grep demo-deployment
0 0 KUBE-MARK-MASQ all -- * * 10.244.1.13 0.0.0.0/0 /* default/demo-deployment */
0 0 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* default/demo-deployment */ tcp to:10.244.1.13:8080
0 0 KUBE-MARK-MASQ all -- * * 10.244.1.49 0.0.0.0/0 /* default/demo-deployment */
0 0 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* default/demo-deployment */ tcp to:10.244.1.49:8080
0 0 KUBE-MARK-MASQ all -- * * 10.244.1.48 0.0.0.0/0 /* default/demo-deployment */
0 0 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* default/demo-deployment */ tcp to:10.244.1.48:8080
0 0 KUBE-SVC-DQLHYT6BA522LQEE tcp -- * * 0.0.0.0/0 10.96.86.32 /* default/demo-deployment cluster IP */ tcp dpt:8080
0 0 KUBE-MARK-MASQ tcp -- * * !10.244.0.0/16 10.96.86.32 /* default/demo-deployment cluster IP */ tcp dpt:8080
0 0 KUBE-SEP-QNWYV3WQ24VOLNDR all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/demo-deployment -> 10.244.1.13:8080 */ statistic mode random probability 0.33333333349
0 0 KUBE-SEP-S7C5UNC7WZYGDOLF all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/demo-deployment -> 10.244.1.48:8080 */ statistic mode random probability 0.50000000000
0 0 KUBE-SEP-S3M2SWKRDC2XB5F5 all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/demo-deployment -> 10.244.1.49:8080 */
透過 Service 實現的原理,我們能了解當新增一個 Pod 時,只有在該 Pod 的 readiness 探測通過後(在之前的介紹中有提到),流量才會被允許進入。這是通過 Endpoints 進行服務發現實現的,使得 kube-proxy 可以在 iptables 中添加相應的 Pod IP 地址,以確保流量能正確地流向該 Pod。
Kubernetes 在 Pod 被刪除時需要執行幾個重要的步驟:
首先,它發送一個 SIGTERM 信號給容器中的應用程序服務,請求它優雅地結束運行,盡量完成正在處理的工作並清理資源,以避免資源洩漏。
同時,Kubernetes 也需要移除 iptables 中的轉發規則,以停止將流量引導到已被刪除的 Pod。
然而,值得注意的是,SIGTERM 信號和 iptables 規則的移除是同時發生的。這可能導致 race conditions(競態條件),即 iptables 可能在容器關閉之前移除相應的 Pod IP,或者容器可能在 iptables 規則被移除之前被關閉。這種情況可能導致流量不正確地引導到已被刪除的 Pod,或者容器無法完成清理工作。

圖檔來自 Graceful shutdown and zero downtime deployments in Kubernetes
這份時序圖有兩部分,分別描述了以下情況:
從下半部分的情況中可以看出,如果 Pod 在 iptables 移除相應 IP 之前被關閉,這可能導致流量仍然被轉發到已經關閉的 Pod IP。由於該 Pod IP 上已經沒有運行容器實例,這可能導致流量的丟失,對用戶而言,這會表現為服務不可用的情況。
因此,Graceful-shutdown 變得非常重要,它確保容器能夠優雅地結束運行,同時防止競態條件和可能的問題,確保應用程序的可靠性和穩定性。
實現關鍵在於提供 endpoint controller 在 Pod 關閉之前,有足夠的時間去更新 iptables,主要有兩種做法
lifecycle.preStop 執行 sleep,延後 Pod 關閉的時間
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
lifecycle:
preStop:
exec:
command: ["sleep", "30"]
terminationGracePeriodSeconds: 60 # 此數字務必大於 sleep 的時間,通常能配置為 sleep秒數 + 30s
terminationGracePeriodSeconds代表收到刪除 Pod 的請求後,提供 Pod 多久時間來關閉 (預設 30s),此時間包含 preStop + container 關閉的時間,若該值小於 sleep 時間,可能會導致 容器收不到SIGTERM信號就被強制關閉了。
SIGTERM 信號後,自行 sleep 數秒,延後 Pod 關閉的時間。
terminationGracePeriodSeconds一樣要大於 sleep 時間。
透過以上兩種方式,在大部分 Kubernetes master 運作正常的狀況下,能解決 race conditions(競態條件)了。
SIGTERM當應用程序接收到 SIGTERM 信號時,應該進行妥善的處理,包括資源清理和盡可能完成正在進行的操作,而不應立即關閉應用程序。否則,可能會導致未完成的操作或資源泄漏的問題。
通常,應該根據運行的容器來選擇適當的處理方式。以 Spring Boot 為例,它提供了相關的功能配置,您可以參考這個教程來了解更多。
如果客戶端使用長連線(keep-alive)時,即使伺服器端實施了Graceful-shutdown,由於長連線的機制,仍然可能將請求發送到已經關閉的 Pod IP。
目前,筆者尚未解決這個問題,解決思路可能需要在應用程序接收到 SIGTERM 信號後,為每個回應都添加 Connection: close 標頭,以通知客戶端重新建立連線(將連接到新的 Pod)。然而,即使存在這個問題,仍建議採取今天介紹的其他措施,以解決可能導致流量丟失的其他情況。
今天介紹了 Service 實現原理 與 如何實施 Graceful-shutdown,讓服務在更新時,能將對用戶的影響降低到更小的幅度,讓服務維持可用性。
在實施 如何實施 Graceful-shutdown 時務必注意幾個部分
terminationGracePeriodSeconds 務必大於 sleep 的秒數,避免容器被強制關閉,通常能配置為 sleep 秒數 + 30s(terminationGracePeriodSeconds預設值)
SIGTERM 信號時,應妥善處裡當前運行的作業與清理資源,能查詢你的應用程序或框架是否支援此功能。
