
| 資訊處理流程 | 生成 | 收集 | 儲存 | 使用 |
|---|---|---|---|---|
| Fluent Bit | ✓ |
Fluent Bit 是資料收集器 Fluentd 的輕量化版本。在經歷了 Observability 的大爆發後,Fluent Bit 將自己重新定位成 「Telemetry Agent for Logs, Metrics and Traces」,將這三個 Telemetry Data 視為主要的資料來源。Fluent Bit 可以從不同來源收集 Logs、Metrics 或 Traces,並支援多種處理或儲存服務,如 Loki、Fluentd、Elasticsearch、DataDog、Kafka 以及各式雲端服務。

Fluent Bit 是由 Eduardo Silva 在 2014 年於 Treasure Data工作時建立的開源專案。Treasure Data 是由 Fluentd 的作者 Sadayuki Furuhashi 創辦,提供數據收集與分析平台。Fluent Bit 設計的最初目的是為了收集 IoT 設備 的 Log,這些設備大多使用 Embedded Linux 且硬體資源很少,因此資料收集器必須要盡可能的輕量化,使其能夠在資源有限的設備上運行。到了 2020 年,Eduardo 創立了 Calyptia,以提供與 Fluent Bit 相關的顧問與 SaaS 服務。
Fluent Bit 將每一筆收到的 Log、Metric 或 Trace 視為一個 Event,例如收到以下的 Log:
Jan 18 12:52:16 flb systemd[2222]: Starting GNOME Terminal Server
Jan 18 12:52:16 flb dbus-daemon[2243]: [session uid=1000 pid=2243] Successfully activated service 'org.gnome.Terminal'
Jan 18 12:52:16 flb systemd[2222]: Started GNOME Terminal Server.
Jan 18 12:52:16 flb gsd-media-keys[2640]: # watch_fast: "/org/gnome/terminal/legacy/" (establishing: 0, active: 0)
這四筆 Log 會被視為四個 Event,每個 Event 都會包含以下三個欄位:
在 2.1.0 版之後,Event 的資料格式表達為 [[TIMESTAMP, METADATA], MESSAGE],而在此版本之前則為 [TIMESTAMP, MESSAGE]。雖然兩者格式略有不同,但 2.1.0 版後的 Fluent Bit 仍然可以解析 2.1.0 之前的資料格式。
Fluent Bit 的 Config File 支援兩種格式:基於 INI 設計的格式與 YAML,以下為一個簡單的 Config File 範例:
[INPUT] # 中括號定義 Section
Name dummy # Key 與 Value 以空格分隔
Tag dummy
Dummy {"message": "hello world"}
其 YAML 格式如下:
input:
name: dummy
tag: dummy
dummy: '{"message": "hello world"}'
在 Fluent Bit,資料會經過一連串的處理流程,稱為 Pipeline。主要元件包括:
Fluent Bit 官網提供了 SandBox 教學,可以在虛擬環境中學習如何使用 Fluent Bit。
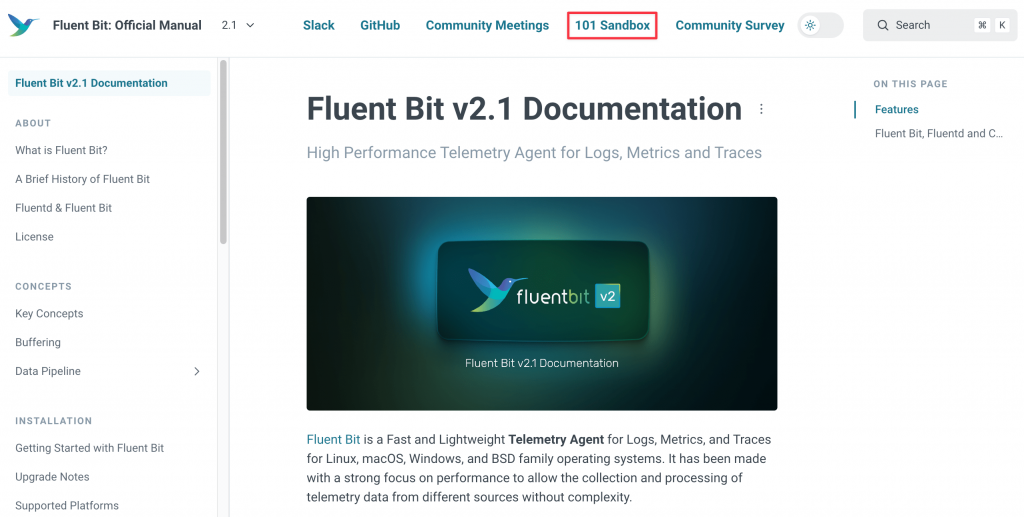
在 Pipeline 中,Tag 用於 Input 識別資料來源,而 Match 則用於指定哪些資料需要經過特定的 Filter 或 Output 處理。了解 Tag 與 Match 對於理解 Fluent Bit 的運作非常重要,否則就會發現資料沒有按照你預想的 Pipeline 被處理。
Tag 設定於 Input,作為識別該資料來源的標籤,供後續 Pipeline 配對使用。如果沒有設定 Tag,預設會使用 Input 的名稱加上 . 與流水號作為後綴,例如:dummy.0、tail.1、systemd.2 等。
Match 設定於 Filter 與 Output,作為篩選資料的條件,若有符合條件的就會被 Filter 與 Output 處理。相反的,如果沒有設定 Match,Filter 或 Output 就會不會處理任何資料。
以下面這組 INPUT 為例,其中的 Tag 為 my_first_dummy:
[INPUT]
Name dummy
Tag my_first_dummy
Dummy {"message": "hello world"}
如果希望 Output 只處理 Tag 為 my_first_dummy 的資料,可以在 Output 中設定 Match:
[OUTPUT]
Name stdout
Match my_first_dummy
或者在 Output 中設定 Match 為萬用字元 *,表示所有資料都會被處理:
[OUTPUT]
Name stdout
Match *
如果想要讓 Output 只處理 Tag 為 my_ 開頭的資料,Match 可以設定為 my_*:
[OUTPUT]
Name stdout
Match my_*
每個 Input 都有各自對應的參數,例如 Tail Input 可以指定要讀取的檔案路徑、多行 Log 的 Parser 等,例如:
[INPUT]
name tail
path /var/log/python/*.log
multiline.parser python
Parser 負責將 Input 的資料轉為結構化資料。支援多種不同的方式,如:
Parser 有一些通用的 Config 參數,如:
json、logfmt、regex 等以使用 JSON Parser 為例,若原始 Input 取得的 Log 如下:
{"key1": 12345, "key2": "abc", "time": "2006-07-28T13:22:04Z"}
Parser 的設定方式為:
# 獨立設定於 parsers.conf 中
[PARSER]
Name my_json_parser # 自訂的 Parser 名稱
Format json
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S %z
# 設定於 fluent-bit.conf
[INPUT]
Name tail
Path /var/log/docker/*.log
Parser my_json_parser # 指定要使用的 Parser
解析出來的資料會變成:
[1154103724, {"key1"=>12345, "key2"=>"abc"}]
Filter 可以對資料進行過濾、增加或刪除資訊等,可以說是 Fluent Bit 最重要的功能,支援多種不同的方式,如:
{"a": {"b": 1}} 轉換為 {"a.b": 1}
順序為 Config File 中 Filter 的順序,例如:
[FILTER]
Name grep
Match * # 所有 INPUT 都會被處理
Regex msg ^error
[FILTER]
Name Modify
Match * # 所有 INPUT 都會被處理
Add custom_key custom_value
會依序執行 Grep 與 Modify Filter,先保留資料 msg 欄位以 error 開頭的資料,再將 custom_key: custom_value 加入到資料中。
例如原始資料為:
{"msg": "error: something wrong"}
{"msg": "debug: pass"}
{"msg": "info: just info"}
處理後的資料會變成:
{"msg": "error: something wrong", "custom_key": "custom_value"}
例如,將資料送至 Loki 的設定如下:
[OUTPUT]
Name loki
Match docker # 只有 Tag 為 docker 的 INPUT 才會使用此 OUTPUT
Host loki # 不用加入 Path loki/api/v1/push
Port 3100 # 預設為 3100
Labels job=fluent-bit # Loki 儲存 Log 時使用的 Label
以下是一個綜合範例,展示 Input、Parser、Filter 和 Output 的設定。
[INPUT]
Name dummy
Tag my_first_dummy
Dummy {"msg": "error: got error"}
[FILTER]
Name grep
Match my_first_dummy
Regex msg error
[OUTPUT]
Name stdout
Match my_first_dummy
這個配置檔會從 Dummy Input 讀取資料,使用 Grep Filter 過濾出包含 "error" 的訊息,最後將這些資料輸出到 Console。
有時候在設定的範例會看到有一個 SERVICE section,它是 Fluent Bit 的一個特殊 section,用於設定 Fluent Bit 本身的參數,例如:Flush、Daemon、Log_Level 等,這些參數會影響到 Fluent Bit 的行為,而不是資料的處理流程。
[SERVICE]
Flush 5
Daemon off
Log_Level debug
範例程式碼:16-fluentbit
啟動所有服務
docker-compose up -d
檢視 fluent-bit Container log
docker logs -f fluent-bit
關閉所有服務
docker-compose down
啟動所有服務
docker-compose -f docker-compose.loki.yaml up -d
檢視服務
admin/admin
點擊左上 Menu > Explore,左上 Data Source 選擇 Loki,在 Label Filter 中 Label 選擇 app,Value 選擇 nginx,即可看到 nginx Container 的 Log
若要生成更多 Log 也可以使用 k6 發送更多 Request
k6 run --vus 1 --duration 300s k6-script.js
關閉所有服務
docker-compose down
啟動所有服務
docker-compose -f docker-compose.vivo.yaml up -d
檢視服務
關閉所有服務
docker-compose -f docker-compose.vivo.yaml down
Fluent Bit,作為資料收集器 Fluentd 的簡化版本,擁有完整的 Plugin 生態系。不僅可以從多樣的資料來源中進行資料收集,而且能將資料推送至不同的目的地。同時,它還能與 Fluentd 無縫整合,延續既有的 Plugin 生態。類似於 Grafana,Fluent Bit 的目標是建立一個開放、多元的生態系,讓使用者能夠自由地將其整合進自己的系統之中。
隨著 Observability 領域的迅速發展,Fluent Bit 的創始人 Eduardo 所領導的公司 Calyptia 也推出了全新的開源專案 Vivo。這個專案專注於展示 Fluent Bit 所收集到的各類 Telemetry Data,並且能與 Fluent Bit 進行深度整合。

