Hello 大家好!歡迎回來!昨天剛剛分享完機器人強化學習 (Reinforcement Learning in Robotics),那今天我打算跟大家分享深度強化學習 (Deep Reinforcement Learning)。事不宜遲,現在開始!
深度強化學習是結合深度學習和強化學習的前沿領域,通過利用深度神經網絡,訓練能夠在複雜環境中做出智能決策的代理。這種方法允許代理從原始感知輸入中進行學習,從而能夠在各個領域中解決具有挑戰性的問題,並實現人類水平的性能。
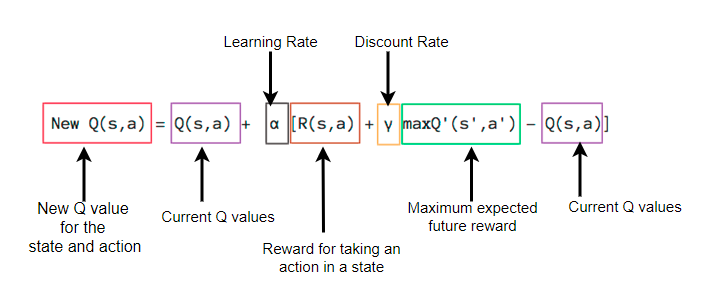 [1]
[1]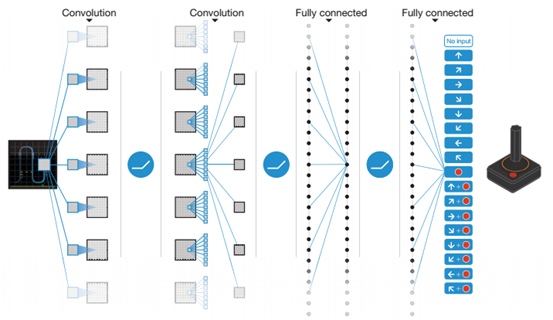 [2]
[2]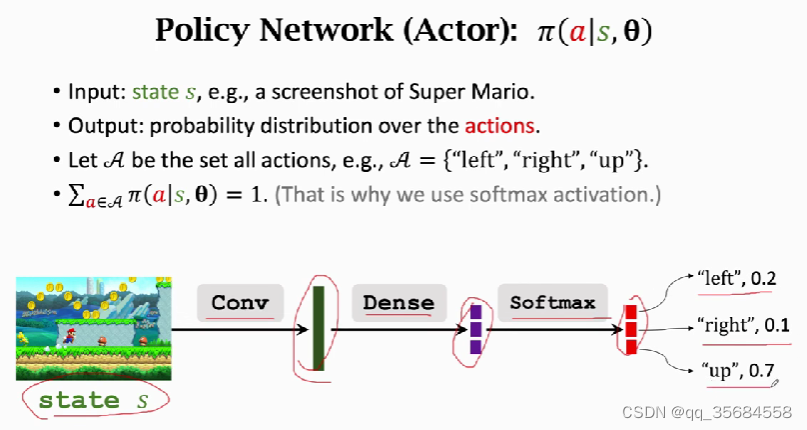 [3]
[3]我是 Mr. cobble,明天見!

