接續昨天部分,以學習記錄方式繼續進行。
ID = id
CLASS_NAME = class_name
NAME = name #似乎很少被使用,暫時略過,不一定每個標籤都會有name屬性
LINK_TEXT = link_text
PARTIAL_LINK_TEXT = partial_link_text
TAG_NAME = tag_name
XPATH = xpath
CSS_SELECTOR = css_selector
首先起手式,前面都提到爛掉的,只要導入套件以及最方便抓定位的組合起來使用
導入 Selenium,才能使用 Selenium 的功能
from selenium import webdriver
from selenium.webdriver.common.by import By
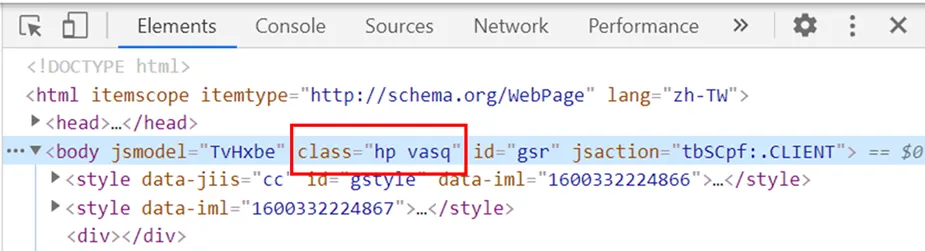
來抓看看這個 ID ,下圖的綠色框框
這裡嘗試兩種寫法 ,來我還是只能透過 import By,才能成功 XD
( 無法像網上大大兩種都可以自由來去,下片面噴錯誤訊息的事 這種寫法 driver.find_element_by_id("APjFqb") )
不過我無法像網上大大文章一樣在縮小範圍了,他舉例的有兩層,
我舉例的部分,往上往下層都沒有可以縮小了
來看看大大怎麼說吧!下圖來自:動態網頁爬蟲第二道鎖,綠色框框是我圈的
可以清楚看到紅色框框 ID 位置往下一層 還有綠色框框的 ID 可以再縮小範圍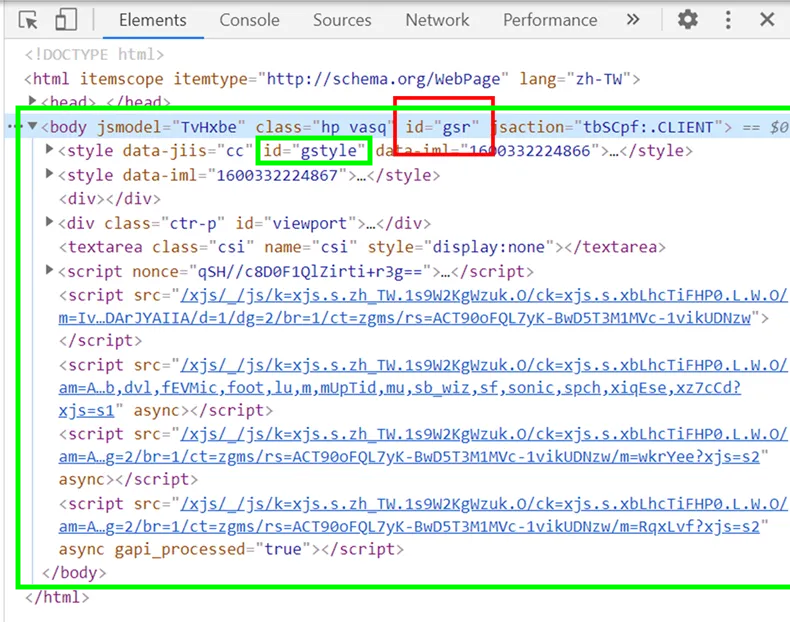

使用 classname 選擇器來抓取網頁元素。
就來跟前面抓一樣的地方吧~
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
#打開網頁:使用get方法打開你要爬取的網頁。
driver.get("https://www.google.com/")
driver.find_element(By.CLASS_NAME, "gLFyf")
driver.quit()
💥特別需要筆記的部分,下圖來自:動態網頁爬蟲第二道鎖
字串內有空格的話要改為「 . 」:「 hp vasq 」改為「 hp.vasq 」
driver.find_element(By.CLASS_NAME, "hp.vasq")
老天 還有 TAG_NAME 、 XPATH 、 CSS_SELECTORPARTIAL_LINK_TEXT 、 LINK_TEXT
亂七八糟熬到寫到第 18 天,今天沒能找到例子來示範、操作不太滿意,只能依賴網上大大文章,總之今天進修課程開課了,之後學習的 python 是在 spyder 中操作,默默解鎖🔓 跨出 vscode
動態網頁爬蟲第二道鎖 — Selenium教學:如何使用find_element(s)取得任何網頁上能看到的內容(附Python 程式碼)