原來昨天說的那些有點雜,經過網上大大的文章後,
我又更知道我到底在做些什麼了。
手感上就像是,之前我們在靜態網頁處理類似的
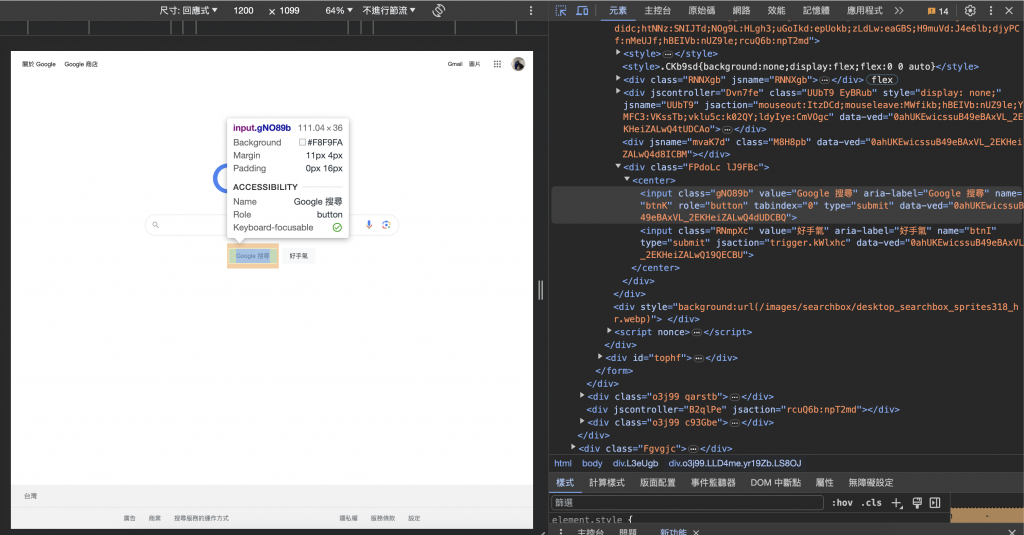
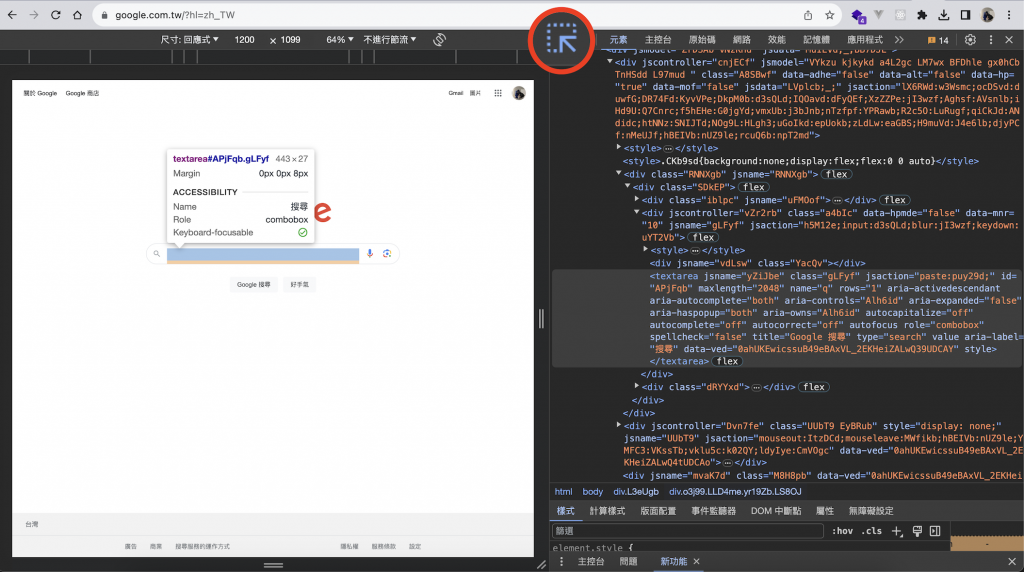
但在這裡我們可以選擇用更有互動效果的“檢視”,下面三張圖可以參考
其中圖三,有個箭頭可以點選,啟動後,可以直接在網頁上點擊想了解的部分,
就會同步顯示出點擊處的程式碼、網頁元素,也可以快速定位原始碼。

find_element 跟 find_elements
前者用於查找"第一個"匹配條件的元素,而 find_elements 用於查找"所有"匹配條件的元素。
find_element:抓取符合條件的第一個項目,可搭配 By 方法。
用於查找頁面上符合指定條件的第一個元素。
返回值是一個 WebElement 對象,表示找到的元素,可以對該元素執行各種操作。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com")
element = driver.find_element(By.ID, "element_id")
print(element.text)
driver.quit()
find_elements:抓取所有符合條件的項目,並回傳成 list。
用於查找頁面上符合指定條件的所有元素,並將它們返回為一個 WebElement 對象的列表。
如果沒有找到符合條件的元素,將返回一個空的列表。可以遍歷這個列表來訪問每個匹配的元素。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com")
# 查找所有 class 為 "element_class" 的元素
elements = driver.find_elements(By.CLASS_NAME, "element_class")
for element in elements:
print(element.text)
driver.quit()
昨天提到五種, 完整來說有八種如下
(看來我需要分個兩篇消化消化)
WebDriver 提供的內建選擇器類型
ID = id
CLASS_NAME = class_name
NAME = name
LINK_TEXT = link_text
PARTIAL_LINK_TEXT = partial_link_text
TAG_NAME = tag_name
XPATH = xpath
CSS_SELECTOR = css_selector
明天再來體驗每種的使用方式
動態網頁爬蟲第二道鎖 — Selenium教學:如何使用find_element(s)取得任何網頁上能看到的內容(附Python 程式碼)

