早安安!
這部分會稍微大概的提及語音前端的處理方式,接著之間進入到最後的實作,再次申明,真的真的想理解更深入的邦友,可以直接去看看這本書書了喔!
在語音辨識中,雜訊、干擾、殘響無處不在,在麥克風擷取的語音中,這些都會降低語音辨識的辨識率,雜訊的東東可以參考下圖,我們之間進入前端的概述講解吧!
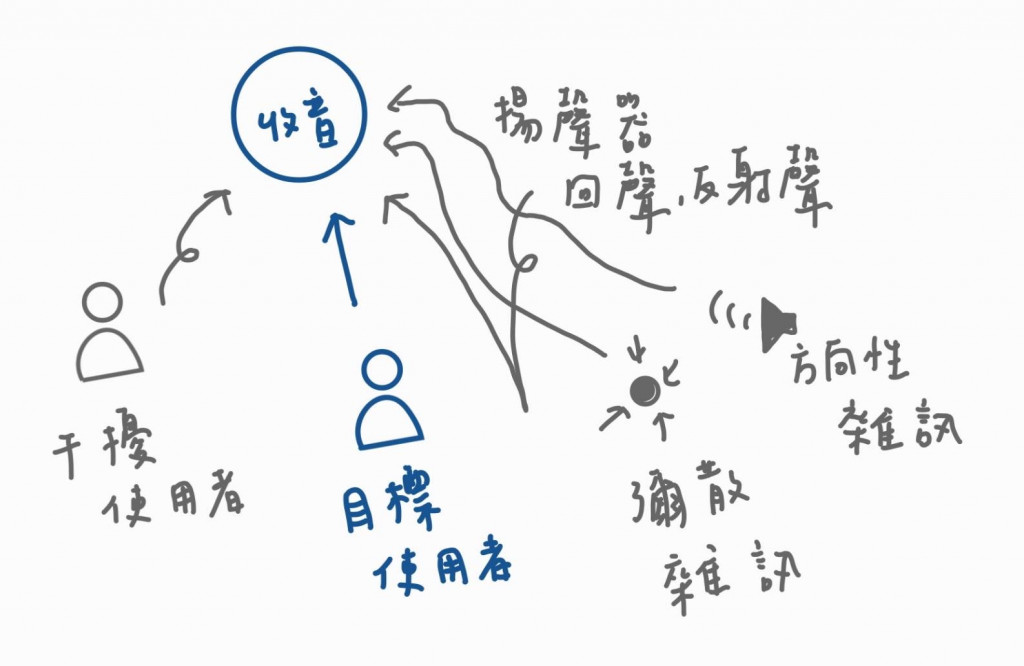
傳統的語音前端演算法是VAD、降噪及AEC,下圖是他們的一個框架。
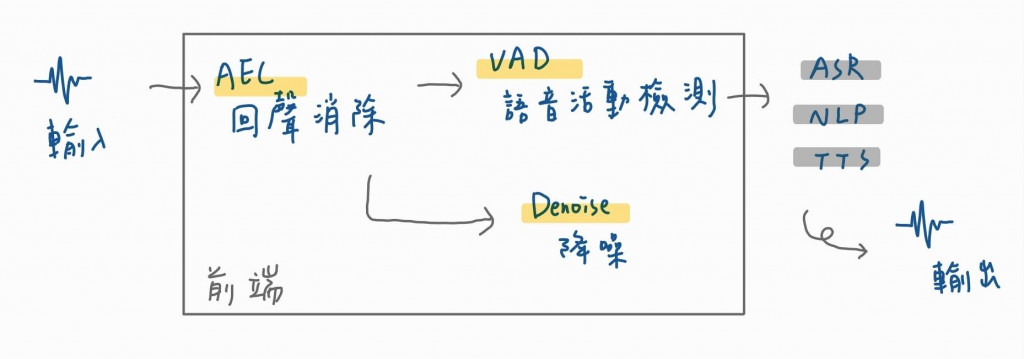
其中VAD的作用是檢測這段有雜訊的音訊中,是否有語音,聽起來很簡單,但這個演算法在語音互動系統中有著非常重要的作用,其可以加入有Always-on的系統中,在這邊,這種演算法會被作為一級演算法,會在機器後台一直運行,在檢測到語音後直接喚醒後面的語音喚醒或聲紋辨識。由於行動裝置對功耗都有要求,因此一直在後台運行就會有困難,而VAD演算法還有一個重要功能是找到一段語音的起點及終點,並以此對資料進行切割,除此之外,VAD演算法是許多演算法的基礎,如降噪及AEC中,都可根據VAD的結果使用不同的處理策略。
參考書籍:Hey Siri及Ok Google原理:AI語音辨識專案真應用開發
參考網站:今日無
學習對象:ChatGPT

