之前的文章中提到了各種監控系統,但警報不會天天響, P0 事件也不會天天發生,因此筆者日常的工作,大多反而是與維運相關的事務。因此,接下來將進入日常維運系列,也會是這次鐵人賽中最大的一個主題,向各位分享筆者在日常維運中的工作。
這系列的第一個主題會圍繞在棒球賽中,因為我們是一個服務客群主要是日本人的線上影音串流平台,而隨著日本棒球季開賽後,熱門的棒球賽開打的當下都會擁入大量的使用者,從而影響到我們伺服器的穩定度,因此針對這些賽事要有一些相對應的措施。雖然從筆者的角度來說是棒球賽,但讀者也可以自行想像為是各種大型活動,比如電商的話可能會有促銷活動等等。
會有這個維運工作,其實是從一個嚴重的 P0 事件開始的。某一天的下午即將下班的時候,我們突然收到了大量的 P0 警報, 同時也收到了 Pingdom DOWN ,也就是平台無法存取的警報。 與此同時,我們專門確認網站正常性的團隊也回報網站的存取速度變得異常緩慢,甚至根本無法存取。
值班工程師在當下則是確認到了系統正在接收到大量的請求,而因為短時間內的請求飆升,導致系統無法負荷而出現了延遲或甚至無法回應的狀況。 因此當下的緊急應對措施,就是直接將伺服器的數量提升為兩倍(也就在 AWS 中 EC2 的 desired capacity),過了大約半小時之後,緊急加開的伺服器都陸續上線後,網站回歸正常的使用。
提個外話,這邊也可以感受到使用雲端供應商的好處,如果是地端的伺服器,恐怕沒有辦法這麼有彈性地在短時間內加開伺服器來因應衝進來的流量。
事後我們整理到了以下的圖表,確認的確是在短時間內請求大量飆升而導致的狀況。
參考下圖,這是我們整個網站的使用者數量與時間的圖表,可以看到在紅色框框裡面有出現使用者大量湧入的狀況:
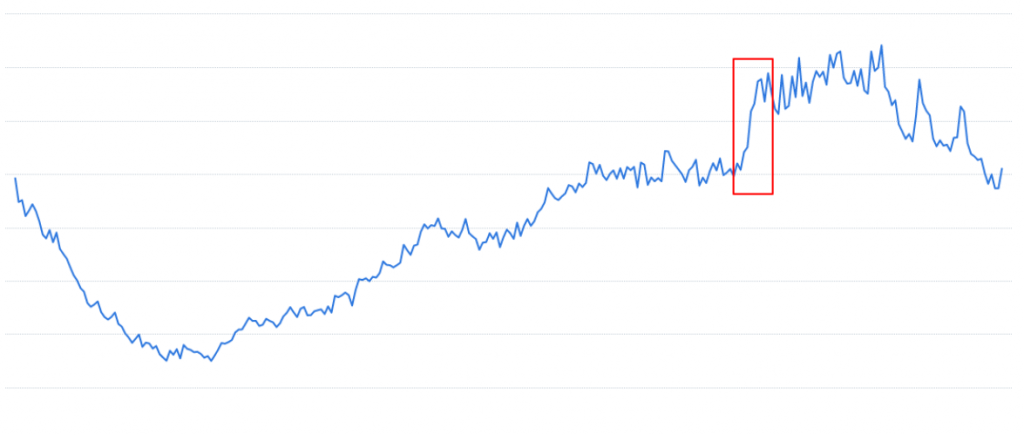
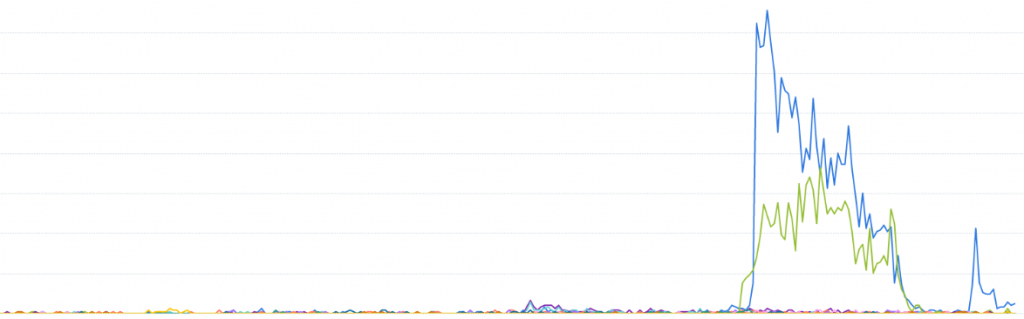
上一張圖是整個網站,而下一張圖是針對棒球賽相關服務的使用者,從這張圖應該會更有使用者數量暴增的感覺:
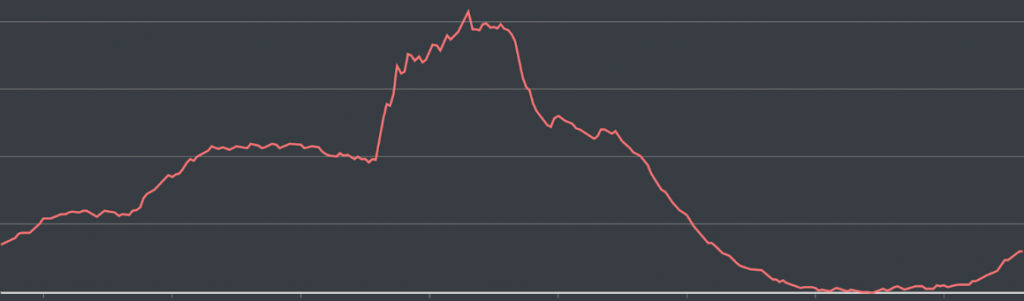
然後是我們後端伺服器接收到的請求數量隨時間增長的示意圖, 可以看到中間出現了一個陡峭的上升曲線:
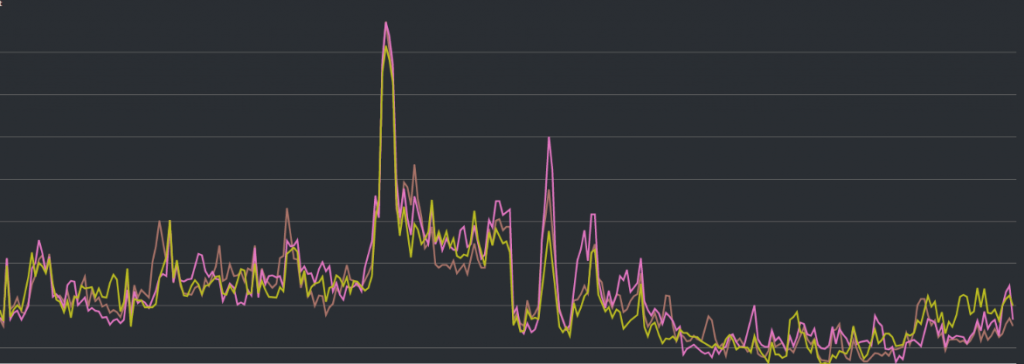
最後則是我們資料庫的 CPU 使用狀況, 一樣可以看到中間有一段飆升的曲線。 而事實上它最後沒有再衝更高的原因,只是單純因為已經衝到 100% 了:
有了這些資訊,我們就可以開始來調查更細致的事件成因,以及具體應該如何解決。


 iThome鐵人賽
iThome鐵人賽