昨天完成了我們的專案,今天一起靜下心坐下來休息一下,談談未來可以改善的地方,來吧,你坐啊
經歷了 9 天的努力,終於把專案完成而且運行起來了,先給自己拍拍手!
雖然只是簡單的例子,也有許多地方沒有談到,例如 cargo-leptos 直接幫我們生成 end-to-end 測試模板 這件事。
但這個專案展示了 Rust 在部署模型與製作機器學習產品的潛力。
使用 Rust 也能帶來安定感,不用擔心今天可以執行但明天卻怪怪的。
而且在實作過程中,我也體驗到了 Rust 社群的強大,在 Discord 上發問,就算我問題很蠢也馬上好幾個主要貢獻者跳出來回答,救甘心欸。
*Created by Joke Ptt
然而,沒有專案是完美的,實際執行時發現了以下幾個問題,所以今天就來檢討一下!
先附上 Taiwan LLaMa 想成為香菜師的宣言,可以原諒他昨天的無禮了: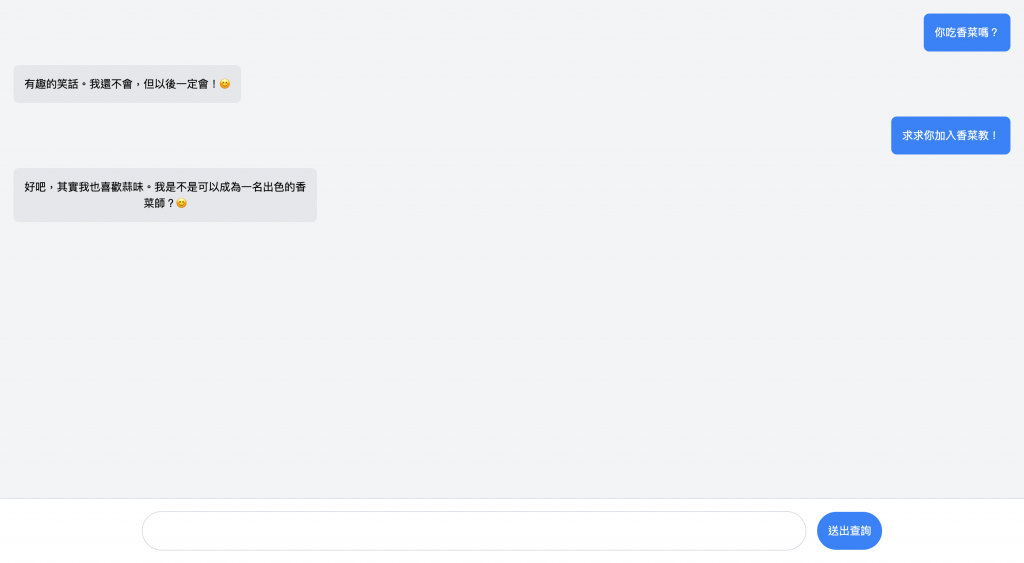
因為我們只用 CPU 來執行有 13B 參數的大模型,所以推論速度確實不很快。
以我手邊的 2021 年 Apple M1 Pro 8 核心 CPU 來說,就算 CPU 貓貓已經跑出殘影了,在運行 q2_K 量化模型時還是要數十秒:
關於這點我目前有兩個解法:
雖然前面說 RustFormers/llm 只能在 CPU 上運行,但團隊已經很積極的提供了 GPU 支援,參考 Acceleration Support 可以看到我們所使用的 LLaMa 模型已經可以在所有常見 GPU 後端上運行了: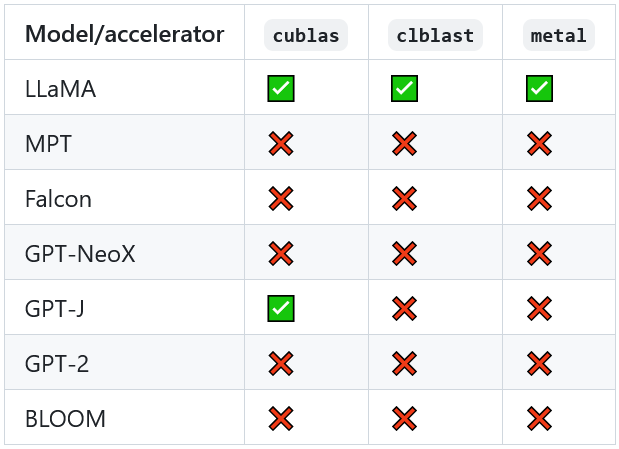
因此我們也可以透過將 ModelParameters 的 use_gpu 設為 true 來取得 GPU 的力量,只要把 main.rs 中的 get_language_model 函式讀取模型的部分改為:
// load a GGML model from disk
llm::load::<Llama>(
&PathBuf::from(&model_path),
llm::TokenizerSource::Embedded,
// llm::ModelParameters
llm::ModelParameters {
use_gpu: true,
..Default::default(),
},
llm::load_progress_callback_stdout
).unwrap_or_else(|err| panic!("Failed to load model: {err}"))
🚨 要利用 GPU 還得根據硬體進行前置設定,這部分請參考 Pre-requisites for Building with Accelerated Support。
但如果我就堅持要用 CPU 呢?逃避可耻但有用,換個小一點的模型吧 🤣
像是我測試過 Wizard-Vicuna-7B-Uncensored-GGML 甚至用到 q8_0 的版本速度都還算可以接受。
或是最近很夯的 Mistral-7B-Instruct-v0.1-GGUF 應該也是不錯,雖然它屬於 GPT-J,要在專案中使用還得修改一下原始碼,但 Rustformers 應該很快就會支援了,可以關注 Support for Mistral-7b。
會感覺推論速度慢的另一個原因是目前的實作會等到所有回應完成後再顯示,在這個期間我們只能看著 ... 跳波浪舞。
因此可以像主流的 ChatGPT 或 Bard 一樣逐字回傳,這樣感覺就能看著文字慢慢出現,心理上比較不會有負擔,至於如何實作這裡暫且就不多加說明了,有興趣的孩子可以參考 這個專案,或之後我再來補一下。
在前幾天的說明中並沒有提到怎麼部署我們的應用程式,但其實整個過程不會很複雜,重點在於 Dockerfile 中不是使用 RUN cargo leptos watch,而是使用發佈模式 RUN cargo leptos build --release -vv。
容器化好之後就能丟到雲服務或任何想用的地方了~
範例 Dockerfile 可以參考 官方教學
今天就到這邊囉,小犬颱風襲台,大家要注意安全不要亂跑哦~ 明天見!


