前言
前幾天介紹了 PySpark 的基礎與 SQL 語法,還沒看過的可以先去看一下:
Day17 - PySpark (1):Basis
Day18 - PySpark (2):Spark with Hive、SQL Syntax
程式碼
這次參賽的程式碼都會放在 Big-Data-Framework-30-days,建議大家直接把整個 repo clone下來,然後參考 README 進行基本設置,接著直接 cd 到今天的資料夾內。
還記得之前用 PySpark 實作 WordCount 的時候我們的程式長什麼樣嗎?當時我們是以 DataFrame APIs 的方法來處理資料,如果你很熟悉 Pandas DataFrame 的話應該很快就能上手,因為兩個真的長得很像 🔍
我相信有用過 pandas 的人肯定不在少數,所以今天就直接來實戰練習,題目是鼎鼎大名的協同過濾推薦!
首先非常簡單地介紹一下什麼是協同過濾推薦,協同過濾是基於用戶對物品的行為,找出用戶或物品之間的相似性,進而做出推薦的演算法,基本的協同過濾可以分為兩類,分別是:
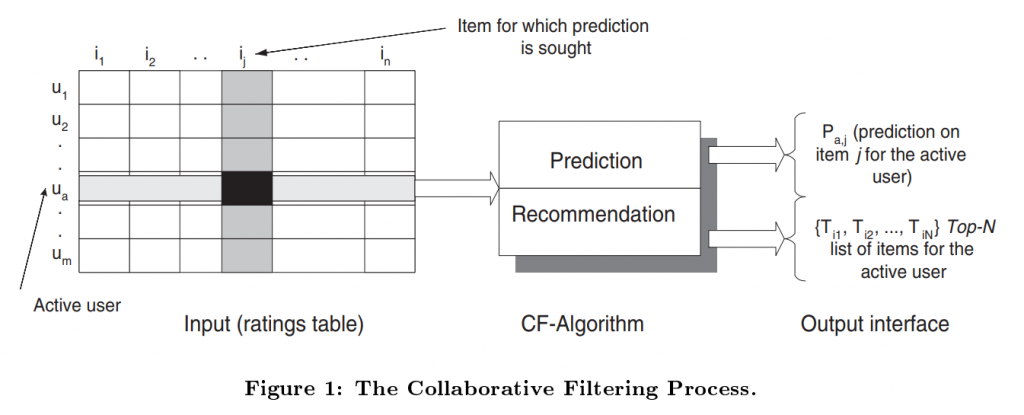
(圖片來源:Item-based collaborative filtering recommendation algorithms)
以 Item-based 協同過濾來說,其算法大致上可以拆為兩個步驟,分別是:
這次練習使用的資料是 MovieLens Dataset,請先下載並解壓縮到 repo 的 /data 資料夾內,或是透過下面指令操作。
$ cd data
$ wget https://files.grouplens.org/datasets/movielens/ml-latest-small.zip
$ unzip ml-latest-small.zip
$ rm ml-latest-small.zip
今天要練習的是 Item-based CF,使用的程式碼是 collaborative_filtering.ipynb。
(ps. Hadoop 記得開 😓)
讀入資料
將檔案讀為 DataFrame 並存為 Hive Table,要注意檔案的路徑是否正確,userId、movieId、rating 是我們會用到的三個欄位,
ratings = spark.read.csv("../../data/ml-latest-small/ratings.csv", header=True, inferSchema=True)
ratings.write.saveAsTable("ratings")
ratings = spark.table("ratings")
ratings.show(5)
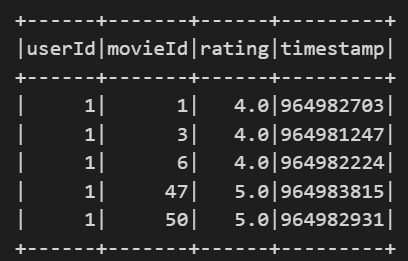
生成 user-item ratings
這邊用 self-join 的方式,將同個 user 評論過的 items 整理為 item pairs,最後會有 movieId1、movieId2、rating1、rating2 4 個欄位。
joined_df = ratings.alias("df1") \
.join(
ratings.alias("df2"),
col("df1.userId") == col("df2.userId"),
"inner"
).where(
col("df1.movieId") != col("df2.movieId")
).select(
col("df1.movieId").alias("movieId1"),
col("df2.movieId").alias("movieId2"),
col("df1.rating").alias("rating1"),
col("df2.rating").alias("rating2"),
)
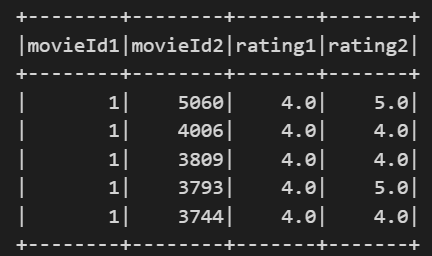
計算 item-item similiarity
使用 groupBy 計算 item pairs 之間的 cosine similarity,公式為
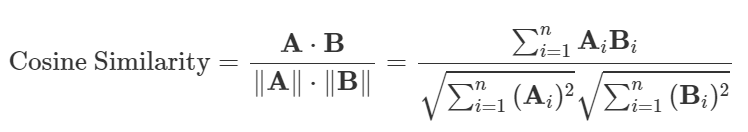
similarity_df = joined_df.groupBy("movieId1", "movieId2").agg(
(sum(col("rating1")*col("rating2")) / (sqrt(sum(pow("rating1", 2))) * sqrt(sum(pow("rating2", 2)))))
.alias("similarity")
)
# 存為 Hive Table
similarity_df.write.saveAsTable("similarity")
similarity_df = spark.table("similarity")
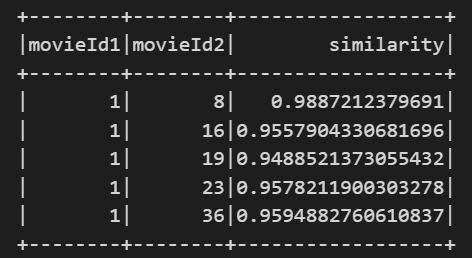
similarity_df.show(5)
因為我們把計算結果都存為 Hive Table 了,所以要推薦的時候直接讀取 Hive Table 就好,不用再去計算相似度。
要解釋的地方是,雖然說是要做相似性矩陣與使用者評分的矩陣乘法,但我們實際上是用 join + groupBy 的方式去完成,大家可以想想看為什麼可以這樣。
最後是我這邊偷懶沒有再去過濾掉使用者以評分的電影,大家可以自己加上去喔 ~
def recommender(userId):
# 讀取 Hive Table
similarity_df = spark.table("similarity")
user_df = spark.table("ratings").where(col('userId') == userId)
# 生成推薦
user_recommend_df = user_df \
.join(similarity_df, user_df.movieId == similarity_df.movieId1, "left") \
.withColumn("weighted_rating", col("similarity") * col("rating")) \
.groupBy("movieId2") \
.agg(sum("weighted_rating").alias('score')) \
.orderBy("score", ascending=False) \
.limit(10)
return user_recommend_df
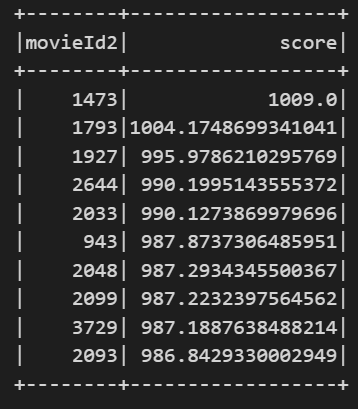
# 為 userId 1 做出推薦
recommends = recommender(1)
recommends.show()
協同過濾好麻煩喔,能不能不要自己寫協同過濾啊?Spark MLlib 早就聽到你的心聲了,明天會介紹 MLlib 以及用 MLlib 的套件來做協同過濾。
《猜心競賽:從實作了解推薦系統演算法》- 黃美靈


 iThome鐵人賽
iThome鐵人賽