前言
再昨天的文章中,我們簡單介紹了協同過濾推薦,並用 DayaFrame APIs 來進行實做,大家可以先看看這篇文章再回來:Day19 - PySpark (3):協同過濾推薦
程式碼
這次參賽的程式碼都會放在 Big-Data-Framework-30-days,建議大家直接把整個 repo clone下來,然後參考 README 進行基本設置,接著直接 cd 到今天的資料夾內。
不知道大家昨天實作協同過濾推薦的感覺怎麼樣,撇除我的程式寫太爛的因素,大家是否會覺得跑起來有點慢呢?
其實協同過濾推薦有多種實現方式,昨天用的方法屬於Memory-based Algorithms,會使用所有資料去計算相似度、生成推薦,因此會耗費大量計算資源;而另一種類型則是 Model-based Algorithms,是以矩陣分解或深度學習的方式來去求解,透過模型訓練來找出近似的推薦。
Model-based Algorithms 的缺點是比較複雜,不過沒關係 Mllib 已經將 Model-based 協同過濾打包好了,我們可以直接使用。
Spark RDD 的設計很適合一些需要迭代的任務,因此機器學習可說是 Spark 的重要戰場,而 MLlib 就是 Spark 的機器學習函式庫,讓使用者能在 MLlib 上利用分散式處理的方式來完成機器學習的訓練任務,加快訓練效率。
MLlib 實現了包多種主流的機器學習方法,包含了 SVM、PCA、回歸分析等,以及協同過濾推薦算法 - ALS。
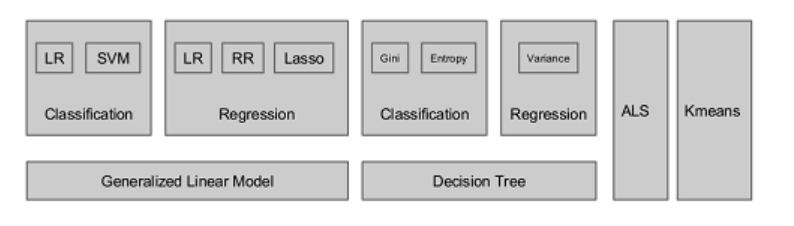
(圖片來源:Spark MLlib介绍)
交替最小二乘(Alternating Least Squares),又稱 User-Item CF,是一個混合型的算法,它同時考慮了 User 與 Item 兩個面向,目標是學習 User 與 Item 之間的潛在特徵,以最小化實際評分和預測評分之間的誤差。
由於 MLlib 已經把模型打包好了,所以完全不知道原理也可以直接使用,因此這邊不多廢話,有興趣的人就自己去研究吧 🥸🥸🥸
我們直接沿用昨天的資料表 (ratings) 來練習,或是任何包含至少 userCol、itemCol、ratingCol 三種欄位的資料表都可以拿來使用。
collaborative_filtering_als.py
from pyspark.sql import SparkSession
from pyspark.ml.recommendation import ALS
from pyspark.ml.evaluation import RegressionEvaluator
spark = SparkSession.builder.appName("Collaborative-Filtering: Spark MLlib").enableHiveSupport().getOrCreate()
# read tables
data = spark.table('ratings')
data.show(5)
# init model
als = ALS(maxIter=5, regParam=0.01, userCol="userId",
itemCol="movieId", ratingCol="rating",
coldStartStrategy="drop")
# train test split
(train_data, test_data) = data.randomSplit([0.8, 0.2])
# train model
model = als.fit(train_data)
# test model
predictions = model.transform(test_data)
# evaulate model
evaluator = RegressionEvaluator(metricName="rmse", labelCol="rating",
predictionCol="prediction")
rmse = evaluator.evaluate(predictions)
print(f"Root Mean Squared Error (RMSE) = {rmse}")
# show results
userResults = model.recommendForAllUsers(10)
userResults.show(5)
itemResults = model.recommendForAllItems(10)
itemResults.show(5)
# close connection
spark.stop()
基於 user 的推薦結果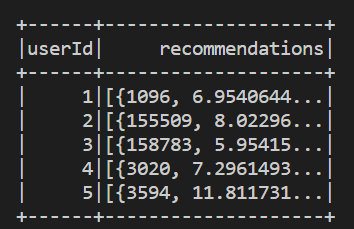
基於 item 的推薦結果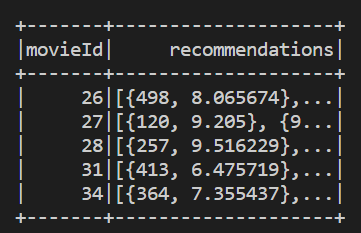
協同過濾終於到此告一段落,不曉得大家會不會覺得有點偏離主題呢?😅😅😅
放心,明天正式拉回主題!將要進入最後一個技術框架 Flink 的介紹。
Collaborative Filtering - Spark 2.2.0 Documentation


 iThome鐵人賽
iThome鐵人賽