
前言
昨天介紹了 PySpark 的基礎,還沒看過的可以先去看一下:Day17 - PySpark (1):Basis
程式碼
這次參賽的程式碼都會放在 Big-Data-Framework-30-days,建議大家直接把整個 repo clone下來,然後參考 README 進行基本設置,接著直接 cd 到今天的資料夾內。
今天我們更深入地講一下 Spark SQL,前幾天有提到過 Spark 與 Hive 可以集成,忘記的可以看這邊:Spark with Hive vs. Hive on Spark,今天的目標是先簡單講一下 Spark with Hive 並介紹一些基本的 SQL Query,接著講 PySpark 的 DataFrame 與 Pandas API。
如果有人是跟著之前的文章一路做下來的話,那恭喜你,因為 Spark 會自動讀入 classpath,你不用多做什麼額外的配置就可以使用 Spark with Hive 了!大家可以用下面指令確認一下是不是有沒有前幾天用 Hive 創建的資料。
$ spark-sql -e 'SHOW TABLES'
如果沒有的話,那可能是之前的配置不完整,請檢查hive-site.xml,hdfs-site.xml,core-site.xml 都有被正確的配置,並將它們放到 /conf 中。
回到 PySpark,想要使用 Spark with Hive 的話,我們只要在 SparkSession 中加上 enableHiveSupport() 就行了。
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("sparkWithHive") \
.enableHiveSupport() \ # 加這行
.getOrCreate()
Spark SQL 的語法其實跟 Hive SQL 大同小異,這邊就簡單示範一些就好,詳細 SQL 語法請參考 SQL Syntax - Spark 3.4.1 Documentation。
這邊特別講一下 Create,Spark SQl 的 Create 有分兩種,分別是:
CREATE [ EXTERNAL ] TABLE [ IF NOT EXISTS ] table_identifier
[ ( col_name1[:] col_type1 [ COMMENT col_comment1 ], ... ) ]
[ COMMENT table_comment ]
[ PARTITIONED BY ( col_name2[:] col_type2 [ COMMENT col_comment2 ], ... )
| ( col_name1, col_name2, ... ) ]
[ CLUSTERED BY ( col_name1, col_name2, ...)
[ SORTED BY ( col_name1 [ ASC | DESC ], col_name2 [ ASC | DESC ], ... ) ]
INTO num_buckets BUCKETS ]
[ ROW FORMAT row_format ]
[ STORED AS file_format ]
[ LOCATION path ]
[ TBLPROPERTIES ( key1=val1, key2=val2, ... ) ]
[ AS select_statement ]
CREATE TABLE [ IF NOT EXISTS ] table_identifier
[ ( col_name1 col_type1 [ COMMENT col_comment1 ], ... ) ]
USING data_source
[ OPTIONS ( key1=val1, key2=val2, ... ) ]
[ PARTITIONED BY ( col_name1, col_name2, ... ) ]
[ CLUSTERED BY ( col_name3, col_name4, ... )
[ SORTED BY ( col_name [ ASC | DESC ], ... ) ]
INTO num_buckets BUCKETS ]
[ LOCATION path ]
[ COMMENT table_comment ]
[ TBLPROPERTIES ( key1=val1, key2=val2, ... ) ]
[ AS select_statement ]
兩種方式的 SQL Syntax 不太一樣,大家使用時要注意一下!
由於前面我們已經集成 Spark with Hive 了,所以我們就以 HiveFormat Table 為主,另外補充一下,就算是使用 DataSource Table,只要其格式與 Hive 兼容,則一樣可以使用 Hive 格式存儲喔。
在 PySpark 中,我們可以用下面的方法來執行 SQL Query。
spark = SparkSession...
spark.sql("sql_query")
基本操作,會使用到 pyspark_sql.py 與 users.txt:
spark.sql("DROP TABLE IF EXISTS users")
spark.sql("DROP TABLE IF EXISTS jobs")
spark.sql("CREATE TABLE users (id int, name string)")
spark.sql("CREATE TABLE jobs (id int, salary int)")
# 寫入資料
query = """
INSERT INTO jobs VALUES
(1, 110000), (2, 50000), (3, 60000),
(7, 90000), (8, 30000), (9, 100000)
"""
spark.sql(query)
# 從本地檔案讀入資料
df = spark.read.csv("users.txt", header=False, inferSchema=True) # inferSchema: 自動識別 data type
df.createOrReplaceTempView("temp_table")
spark.sql("INSERT INTO TABLE your_hive_table SELECT * FROM temp_table")
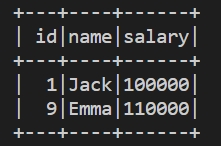
query = """
SELECT users.id, users.name, jobs.salary
FROM users
LEFT JOIN jobs
ON users.id=jobs.id
WHERE jobs.salary >= 100000
"""
df = spark.sql(query)
df.show()
明天是 Spark 的練習,要用 Spark 來實作協同過濾推薦。
Hive Tables - Spark 3.4.1 Documentation

 iThome鐵人賽
iThome鐵人賽