前言
這篇文章會介紹 PySpark (Spark in Python),因此要先安裝好 Python 與 Spark,還沒安裝好 Spark 的人可以先去看看昨天的文章:Day 16 - Spark 安裝與配置
程式碼
這次參賽的程式碼都會放在 Big-Data-Framework-30-days,建議大家直接把整個 repo clone下來,然後參考 Readme 進行基本設置,接著直接 cd 到當天的資料夾內。
前幾天有提到 Spark 支援多種高階程式語言 API,包括:
尤其 Scala 和 Python 是最多人使用的,前者是 Spark 的核心開發語言,擁有最完整的 API 支援,後者則是擁有豐富的外部函式庫,可以應用在多元的開發需求中,我們來簡單分析一下使用兩者的優缺點:
| Scala | Python | |
|---|---|---|
| 優點 | 1. 完整的 API 支援2. 平行化效率佳 | 1. 豐富的外部函式庫2. 適用於多種開發情境3. 容易學習 |
| 缺點 | 1. 較難學習 | 1. 平行化效率較差 |
雖然 Scala 的效能比較好,但實際上兩種語言都是透過 Catalyst Optimizer 來優化 RDD 的查詢運算 ,所以 Spark 本身的效率差異真的不大,大家在選擇時還是以自己熟悉的語言以及團隊開發需求為主要考量。
$ pip install pyspark
$ pip install pandas
$ pyspark --version
SparkSession 是 Spark 2.0 後才出現的概念,是所有 Spark 編程的入口點,使用者透過 Spark Seesion 來使用 DataFrame、DataSet 等 API。
在 Spark 1.X 之前,Spark 的入口點是 SparkContext,簡單分的話,SparkContext 對應到的是 RDD API,SparkSession 則是對應 DataFrame & DataSet API:
入口點 API 類型 | SparkContext | RDD APIs |
| SparkSession | DataFrame & DataSet APIs |
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
start-connect-server.sh,記得把{{}} 替換為正確的 spark version,server 預設是 listen 15002 port。
$ $SPARK_HOME/sbin/start-connect-server.sh --packages org.apache.spark:spark-connect_2.12:{{spark_version}}
$ $SPARK_HOME/sbin/stop-connect-server.sh
{{}} 替換為正確的連線位置from pyspark.sql import SparkSession
spark = SparkSession.builder.remote("sc://{{host:port"}}).getOrCreate()
其實用法跟 pandas 是大同小異啦,如果有用過 pandas 的人應該很快就上手了,邏輯很簡單我就不細講,大家直接看註解就行。
hadoop spark hadoop
spark hadoop spark
# create SparkSession
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("WordCount").getOrCreate()
# read text file as dataframe
text_df = spark.read.text("test.txt")
# word count program
from pyspark.sql.functions import split, explode, count
## split: split each line into list of words
## explode: expand list into single column
## alias: give the column a name "word"
words_df = text_df.select(explode(split(text_df.value, " ")).alias("word"))
## count grouped words
word_counts = words_df.groupBy("word").count()
# show results
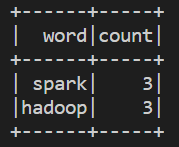
word_counts.show()
# close SparkSession
spark.stop()
雖然 DataFrame、DataSet 是現在的主流,但 RDD API 還是可以用的,所以這邊補充一個基於 RDD 的作法。
test.txt
hadoop spark hadoop
spark hadoop spark
wordCount_rdd.py
# Create SparkContext
from pyspark import SparkContext
sc = SparkContext("local", "WordCountExample")
# Create SparkSession from SparkContext
from pyspark.sql import SparkSession
spark = SparkSession(sc)
# read as rdd
text_file = sc.textFile("test.txt")
# Map Reduce
word_counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
# print results
result = word_counts.collect()
for (word, count) in result:
print(f"{word}: {count}")
# close SparkContext
sc.stop()
明天會介紹 Spark with Hive、SQL Syntax。
Spark 語言選擇: Scala vs. python
PySpark Official Documents
SparkSession vs SparkContext - Spark By {Examples}


 iThome鐵人賽
iThome鐵人賽