昨天提到如何算出評估模型的各種驗證指標,今天就要利用驗證指標中的兩個指標,這兩個指標都是針對預測為陽性 ( 1 ) 時的情況下做比率的計算,一個是召回率 ( Recall ),也叫作真陽率 ( True Positive Rate , TPR ),就是實際為陽性預測也為陽性 ( 1 ) 的比率,另個指標是假陽率 ( False Positive Rate , FPR ),就是實際為陰性預測卻是陽性 ( 1 ) 的比率,用這兩個指標我們要來把能夠評估模型效能的曲線圖畫出來,就是今天的主角 - ROC 曲線,並且求出 ROC 曲線下的面積 - AUC 面積。
在二元分類問題中評估模型的效能,就會用到 ROC 曲線,也稱接收者操作特性曲線,曲線的 x 軸是假陽率 ( FPR ),y 軸是真陽率 ( TPR ),總體來說,ROC 曲線就是描繪出模型的預測結果在不同閥值 ( Threshold ) 下真陽率與假陽率的表現,曲線上的每一點都是在不同的閥值下所對應的真陽率與假陽率所構成。
我們知道真陽率是陽性被預測出陽性的比率,假陽率是陰性被預測出陽性的比率,這邊我們先帶入閥值的觀念,所謂閥值,用在這邊就是被預測陽性的門檻,假設我現在模型預測為陽性的機率為 0.6,此時閥值設為 0.5,代表的就是只要預測值大於等於 0.5,預測值就為陽性 ( 1 ),而預測為陽性的機率 0.3,因為 0.3 小於閥值 0.5,所以預測值會變成陰性 ( 0 )。
閥值越高,代表要被預測為陽性的門檻愈高,實際為陽性就越不容易被預測為陽性,實際為陰性也越不容易被預測為陽性,因此閥值越高就預測為陽性的比例就越低,閥值越低,預測為陽性的門檻較低,就越容易把實際的預測為陽性,實際為陽性就越容易被預測為陽性,實際為陰性的也是如此,此外我們會把預測值本身當作閥值來使用,而二元分類中,模型的預測值會經過激勵函數最後輸出 0 到 1 之間的機率,所以 ROC 曲線的閥值通常也會在 0 到 1 之間。
接下來就要開始繪製 ROC 曲線啦,下表是一個模型 ( 分類器 ) 的預測資料和真實資料範例,讓我們能夠算出真陽率與假陽率,樣本數為 6,這邊我們稱真實值為 1 的都為正例,真實值為 0 的都為反例:
| 真實值 | 1 | 1 | 1 | 0 | 0 | 0 |
|---|---|---|---|---|---|---|
| 預測值 | 0.9 | 0.8 | 0.7 | 0.4 | 0.2 | 0.1 |
我們首先先看到預測值欄位,我們要去遍歷這個欄位中的每個值,並把當前遍歷到的這個值當作閥值來計算真陽性率 ( TPR ) 與假陽性率 ( FPR ),遍歷的過程如下:
經過上面的步驟我們可以得到下表,並把每筆資料都當作座標點 ( 下圖紅點 ) 畫到圖上:
| FPR | 0 | 0 | 0 | 1/3 | 2/3 | 1 |
|---|---|---|---|---|---|---|
| TPR | 1/3 | 2/3 | 1 | 1 | 1 | 1 |
每筆資料畫到圖上的結果,此 ROC 曲線代表的是一個最理想的模型預測狀況 :
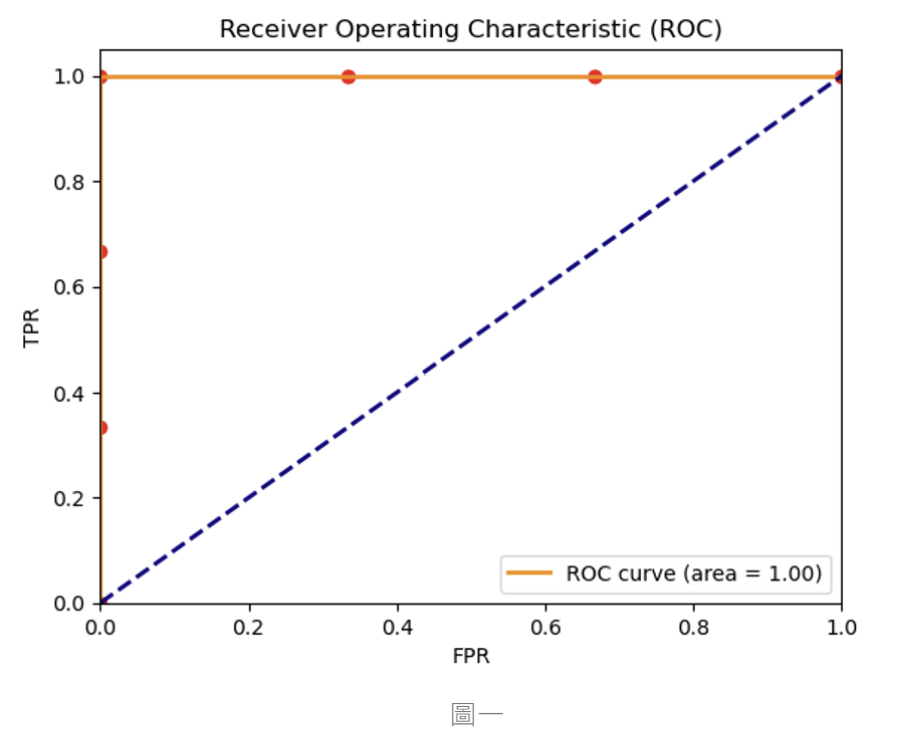
AUC ( Area Under the Curve ) 是 ROC 曲線下的面積大小,AUC 的大小表示了模型在不同閥值下對正例和反例預測的能力,因為 X、Y 軸的最大上限值為 1,所以 AUC 的面積的大小通常會介在 0 和 1 之間:
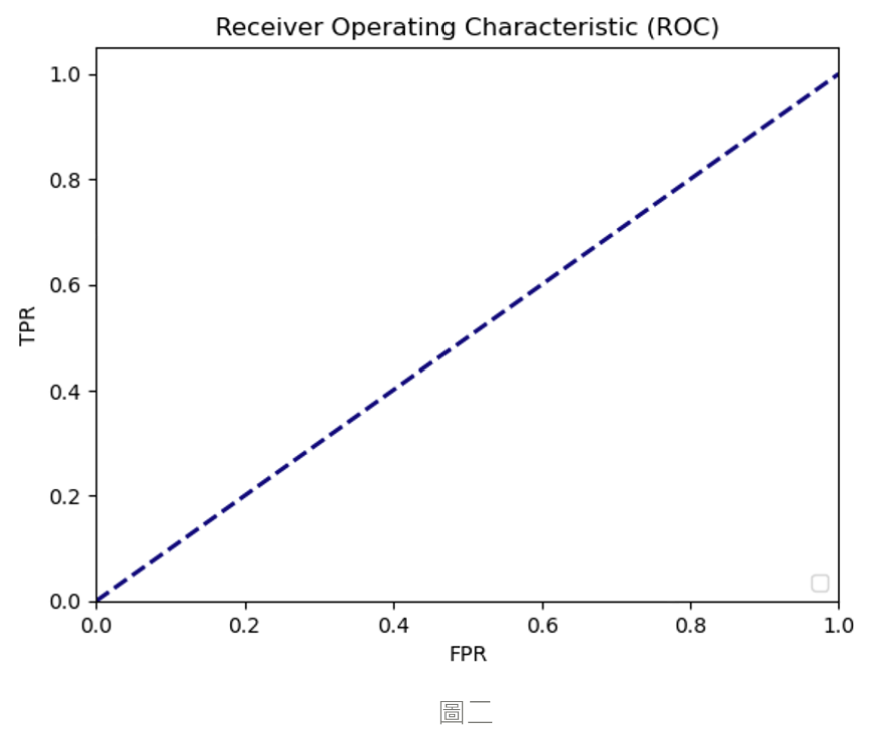
當 ROC 曲線下的面積 AUC > 0.5 時,代表模型的效能優於隨機預測 ( AUC = 0.5 ),能夠正確預測大多數的正反例,在一開始時,反例的預測值就乖乖的在閥值之下而不被預測為陽性,正例預測值就會隨著閥值變小而越容易被預測為陽性,這就會讓最後的 ROC 曲線靠近圖的左上角,越靠近左上的曲線 AUC 大小就會越接近 1,意味著模型越能夠準確的預測正反例。而當 AUC 面積為 1 時,為最理想 ROC 曲線 ( 如圖一 ),模型就能夠完美地正確預測出所有的正反例,而下圖中 A、B、C ROC 曲線的 AUC 都大於 0.5,但同樣都在 0.5 之上,模型的效能也會依據 AUC 大小而有差異,效能表現: A > B > C。
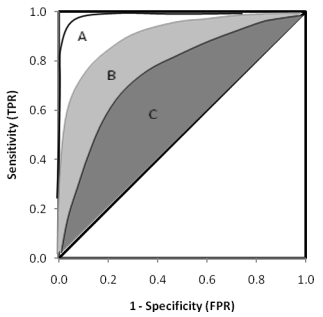
當 ROC 曲線下的面積 AUC = 0.5 時,曲線就為圖二中的斜率為 1 的藍色虛線,代表著正例和反例被預測為陽性的機率在所有的閥值下都相同 ( FPR = TPR ),就像是是擲硬幣時,正反兩面出現的機率,也就是對於正反例預測為陽性的機率都相同,並沒有偏向哪一邊比較容易被預測出陽性,所以模型的預測結果就好像是在擲硬幣一樣隨機猜測,那這個模型的預測結果就會沒有參考的價值,畫出來的 ROC 曲線就會如圖二。
當 ROC 曲線下的面積 AUC < 0.5 時,曲線就會如下圖三,表示預測的結果比隨機猜測還差,會得到下面的 ROC 曲線圖,最差的分類情況為 AUC = 0,我們就可以稱這個模型的預測為反指標,表示所有的正例都被預測為陰性,反例都被預測為陽性 ( 如圖三 ),但此時如果將預測取相反的話就會變成所有正例都被預測為陽性,反例被預測為陰性,此時模型的預測結果就會比隨機預測 ( 藍色虛線 ) 還來得好。
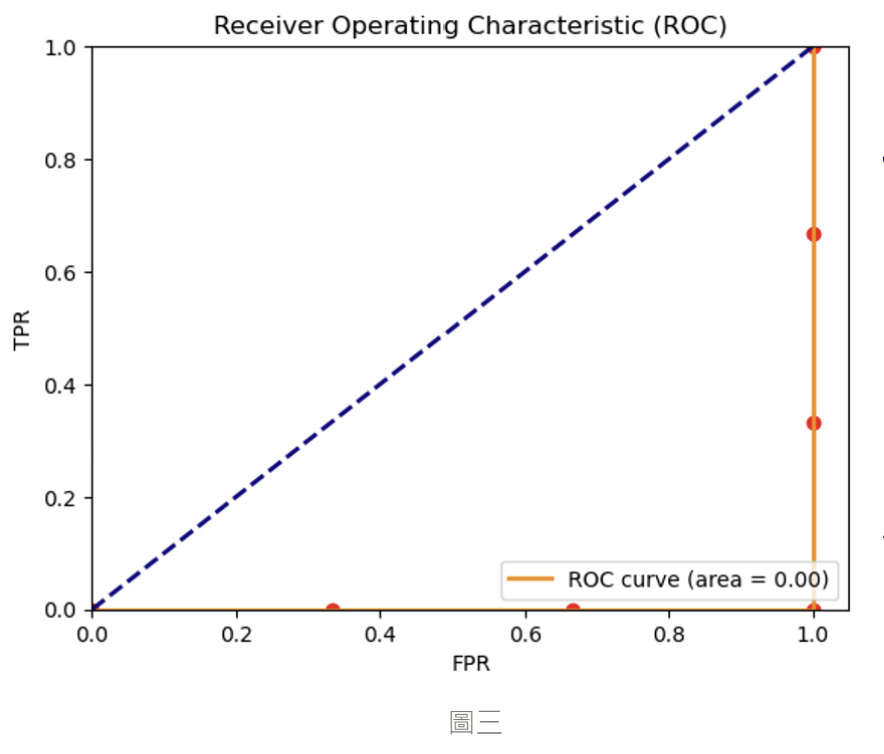
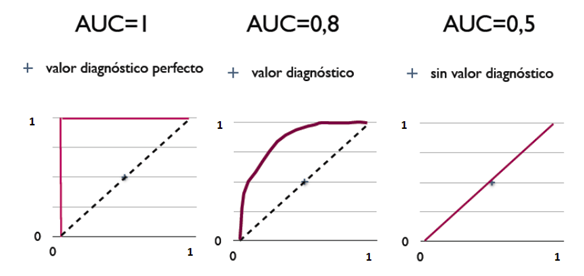
如上圖,通常一個模型有較高的 AUC 面積代表其預測的能力越佳,有更好的分類能例,因此 ROC / AUC 曲線才會被拿來當作評估模型的性能指標之一。
今天我們學到如何用 ROC / AUC 特性曲線來評估模型的效能,明天我們就要來介紹模型在最後效能表現上所反映出的問題,也就是欠缺擬和 ( Underfitting ) 與過度擬和 ( Overfitting ) 的問題,那我們下篇文章見 ~
https://segmentfault.com/a/1190000016735657
https://www.plob.org/article/12476.html


 iThome鐵人賽
iThome鐵人賽