安安!大家週五好!明天要放國慶連假了!今天來看什麼是莎士比亞搜索內的 Job 跟 Data!這裡是今天讀的原文出處:The Production Environment at Google, from the Viewpoint of an SRE,那我們就開始吧!
今天直接把書中內容畫成圖!
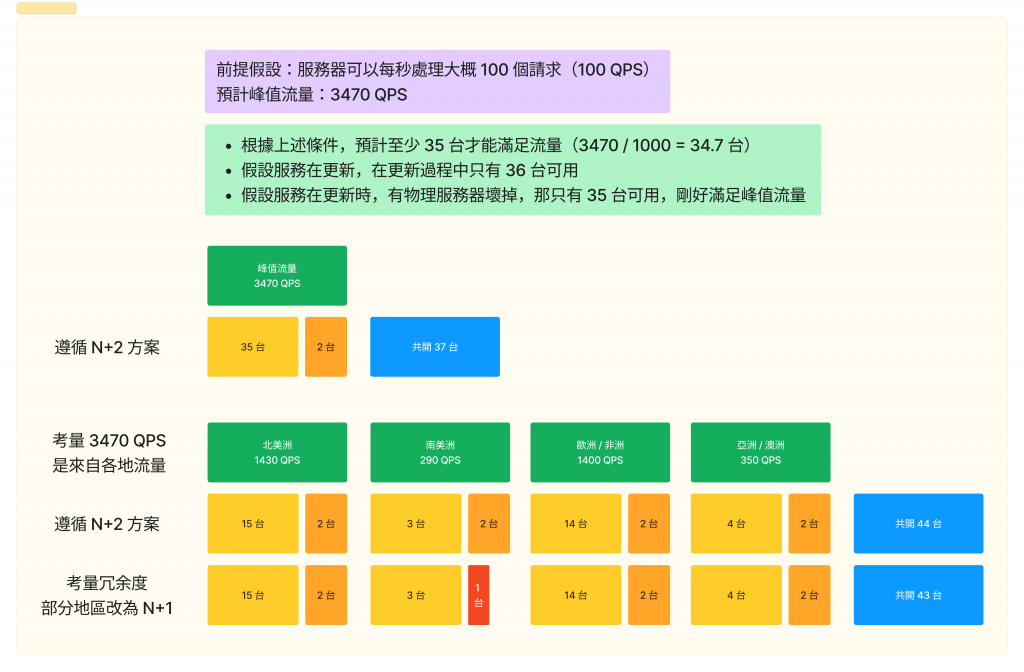
書中提到怎麼估算所需要配置的服務器台數,已知條件是服務總峰值流量的數值,以及一台服務器平均能處理的流量數值。
假設總流量峰值是 3470 QPS,且每個服務器能處理 100 QPS 的請求,那所需的服務器是 3470(QPS) / 100 (QPS) = 34.7 (台),因此至少需要 35 台服務器才夠用。
再加上可能遇到毀損或更新,因此採用 N+2 方案,也就是共 37 台服務器的配置。
另外也考量到總流量其實是由各地的流量集合而成,因此可以考慮異地配置。
延續上述的例子:
上述總流量為 3470 QPS(我加過了大家放心 XD)
因此根據 N+2 方案的話,配置圖會長這樣:
上述台數總共是 44 台。
不過由於考量到即使在極端情況下,GSLB 仍可以替我們將流量導至其他地方(服務不會中斷,但可能延遲狀況比較嚴重),因此為了降低冗余度,可以將南美洲的台數減少,以達成減少成本的目的。
因此最終的台數應為 43 台。
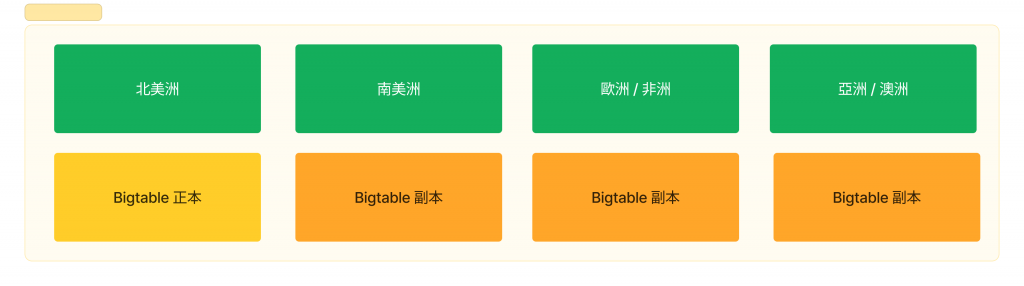
根據上述服務器的配置說明,服務器是放置在全球各地,如果讓亞洲的服務器連線至北美洲,肯定會在數據傳輸上,遇到延遲的問題。為了解決這個問題,Google 在各地都會配置 Bigtable 副本,以確保加速取得數據;另一方面,這也同時確保了可靠性,當 Bigtable 中斷服務時,可以透過各地的副本維持原有服務,直到 Bigtable 恢復服務。
此外,由於「莎士比亞搜索」這個服務的數據更新並不頻繁,因此在數據一致性上也不是優先度高的需求。
今天心血來潮做了個圖片,不知道對於內容消化有沒有更有幫助呢(?)至少對我來說消化的很快!碎碎念到這裡第二章就結束了!(歡呼!!!)偷瞄了一下第三章好像是在講跟風險有關的內容,那就明天見拉!掰噗!大家國慶假期愉快~


 iThome鐵人賽
iThome鐵人賽