今天來説說DAG吧,這也是一個通常會被放在開頭就會跟大家解釋的spark架構之一,不過一樣的,對我來說,在我的學習歷程裡,被放到很後面才真正理解,所以我想,經過了一連串的操作之後,是時候一起來瞭解了!
來舉個比較生活化的例子相信大家都會了解何謂DAG了
先來説説我們的daily routine
起床
離開床
關掉鬧鐘
刷牙洗臉
吃早餐
換衣服
出門,進公司(搭捷運/走路)
如果我要將這些步驟用有順序性的架構下表現,會像是這樣起床→ 離開床→ 關掉鬧鐘→ 刷牙洗臉→ 吃早餐→ 換衣服→ 出門,進公司(搭捷運/走路)
上面的這個步驟就是一個最簡單的DAG(Directed Acyclic Graph)[有向無環圖]
每個事件的順序可以跟動作的不同階段相關,也就是說每個步驟都會導向「出門,進公司」
在理想的狀況下,每個步驟都會depends on 前一個階段的狀態
而且在這個單向的階段序列中不存在循環。(你不會一直陷入起床關掉鬧鐘的死循環中,所以他是單向的)
那讓我們來看一下實際執行Pyspark中的中的DAG吧
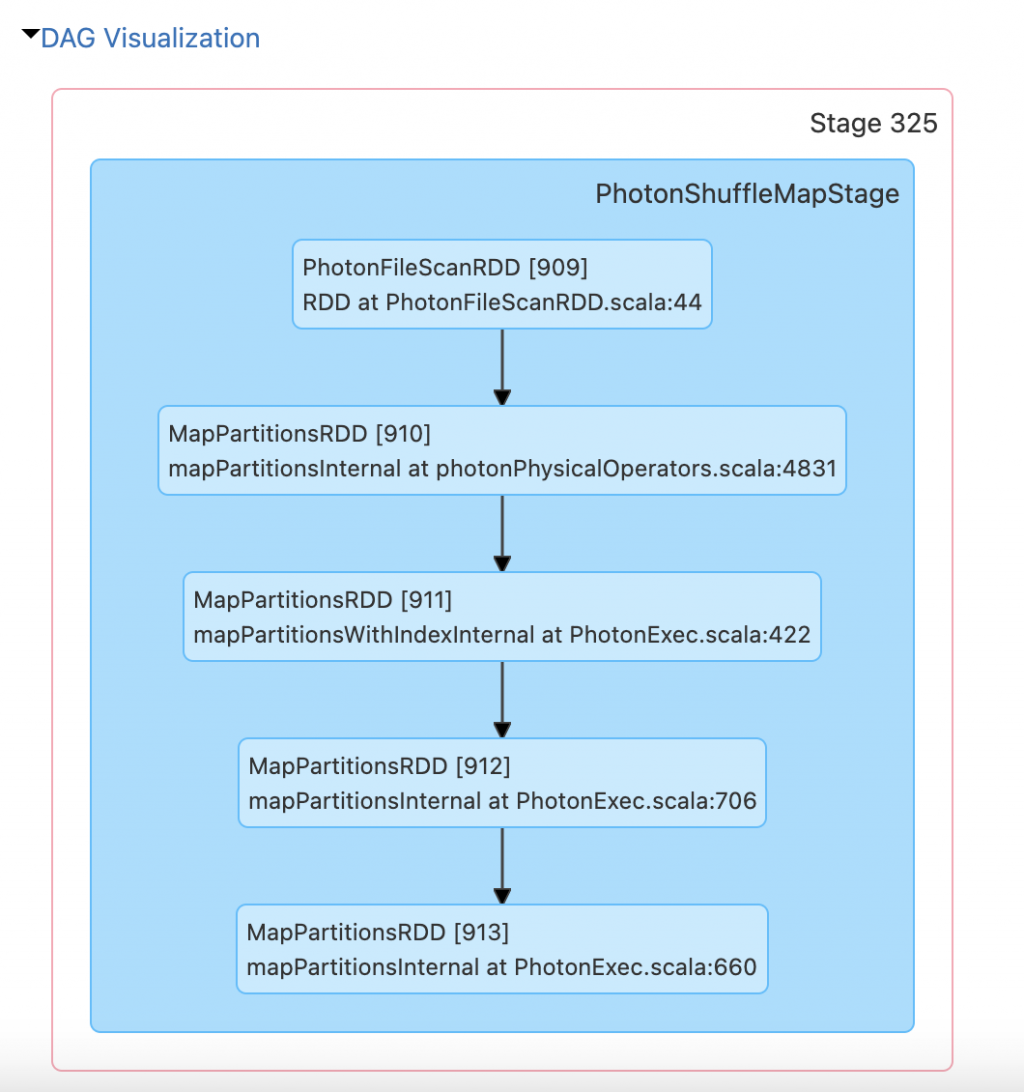
在Spark 中,DAG就是一個Spark引擎的基本概念,也用來優化整個data process的執行
要真的了解DAG 在pyspark的概念,讓我們來好好舉的例子吧!
待補
如果有任何不理解、錯誤或其他方法想分享的話,歡迎留言給我!喜歡的話,也歡迎按讚訂閱!
我是 Vivi,一位在雲端掙扎的資料工程師!我們下一篇文章見!Bye Bye~
【本篇文章將同步更新於個人的 Medium,期待與您的相遇!】

