
Leonardo.Ai 除了文字提示產生圖片,也提供「圖片產生圖片 Image to Image」的功能,只要上傳範例圖片,Leonardo.Ai 就會參考設定生成圖片,這篇教學會介紹 Image to Image 和 Image Prompt 這兩個圖片產生圖片的功能,以及 ControlNet 的三種模式。
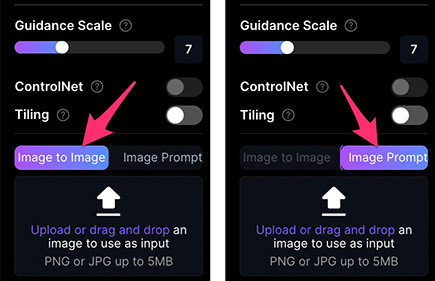
Leonardo.Ai 提供兩種圖片產生圖片的功能,分別是「Image to Image」和「Image Prompt」,兩種功能的說明如下:
- Image to Image:提供「單張」圖片,搭配提示詞和設定產生相似的圖片,功能類似 Midjourney 的 Remix。
- Image Prompt:提供「多張」圖片,搭配提示詞,將圖片內容作為提示的一部分,類似 Midjourney 的 Blend 功能。
「Image to Image」功能可以提供「單張」圖片,搭配提示詞和設定產生相似的圖片,功能類似 Midjourney 的 Remix,使用「Image to Image」功能時不能使用「Prompt Magic」和「PhotoReal」功能,相關設定說明如下:
- Guidance Scale:文字提示的比重,範圍 1~20 ( 官方建議 7~9 )。
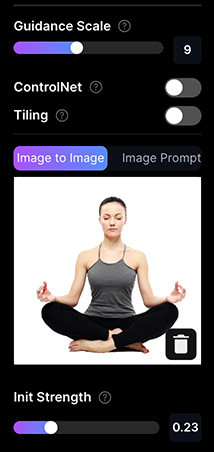
- Init Strength:表示參考圖片比重,範圍 0~0.9,數值越高參考的程度越高。
- ControlNet:控制網格,使用 ControlNet 時不能使用「Alchemy」功能,有些產圖模型不支援 ControlNet。
- Tiling:產生無接縫連續貼圖。
特別注意!使用 Image to Image 功能時,產生的圖片與參考圖片需要「長寬比例相同或接近」,如果兩者差異太大,就可能產出無法控制的詭異的圖片。
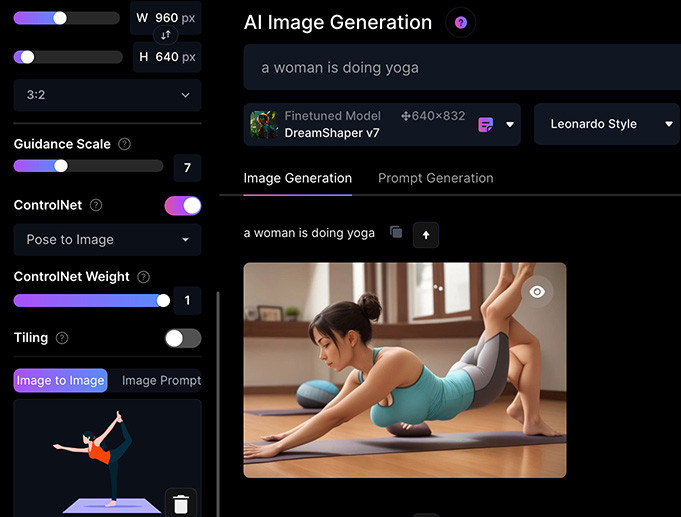
點擊 Upload or drag and drop 按鈕或將圖片拖拉到該區域,就能上傳圖片,下方的範例上傳了一張正在瑜珈運動的女生。
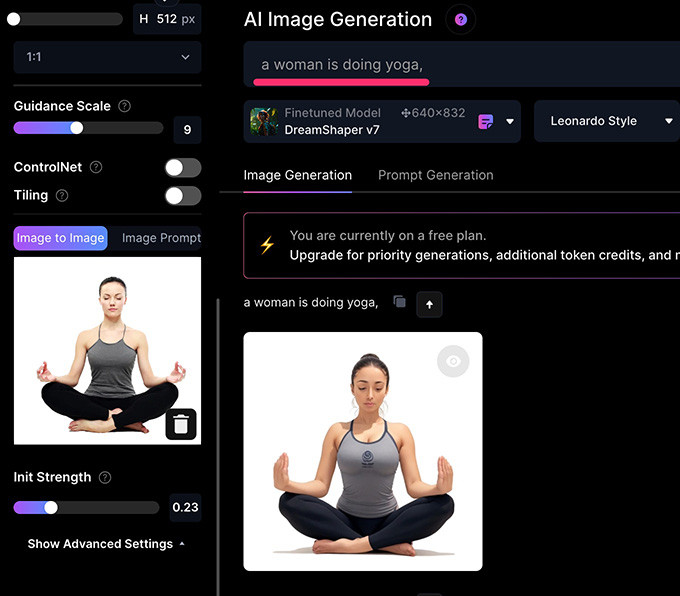
在不使用 ControlNet 的狀態下,輸入文字提示「a woman is doing yoga」,Leonardo.Ai 就會在原本的圖片中進行加工,由於圖片權重 Init Strength 只設定 0.3,所以除了姿勢以外都有些變化。
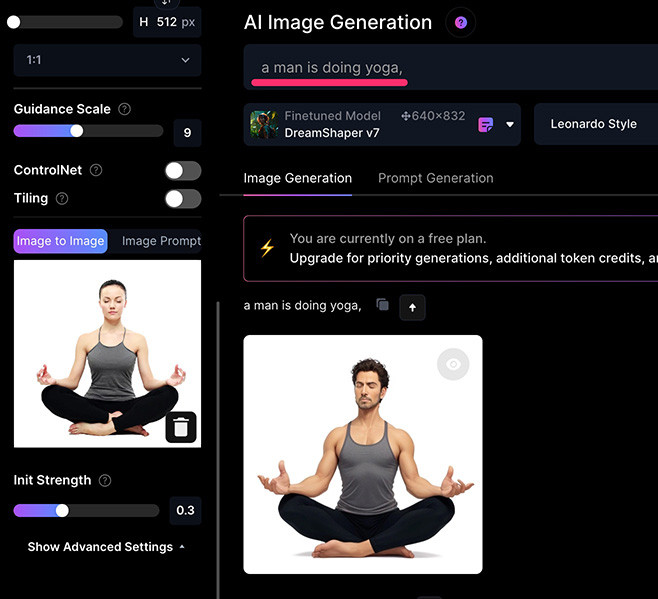
同理如果改成「a man is doing yoga」,參考圖片就會更換成一個正在做瑜珈的男性。
雖然單純使用「Image to Image」好像有點方便,但實際上許多文字提示無法正確發揮作用 ( 例如瑜珈的參考圖,因為背景全白,幾乎無法後過提示詞加入背景 ),因此常要搭配「ControlNet 控制網格」使用。
ControlNet 表示會考圖片的結構,根據結構搭配文字,產生一張類似的影像,使用後會用 ControlNet Weight 取代 Init Strength,ControlNet 提供四種模式,分別是「Pose to image 姿勢」、「Edge to image 輪廓」、「Depth to image 深度」和「Pattern to image 圖案」。
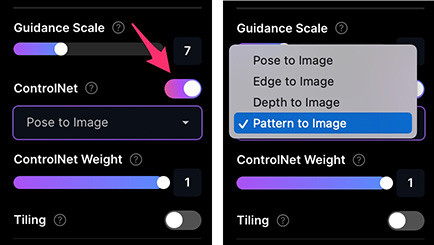
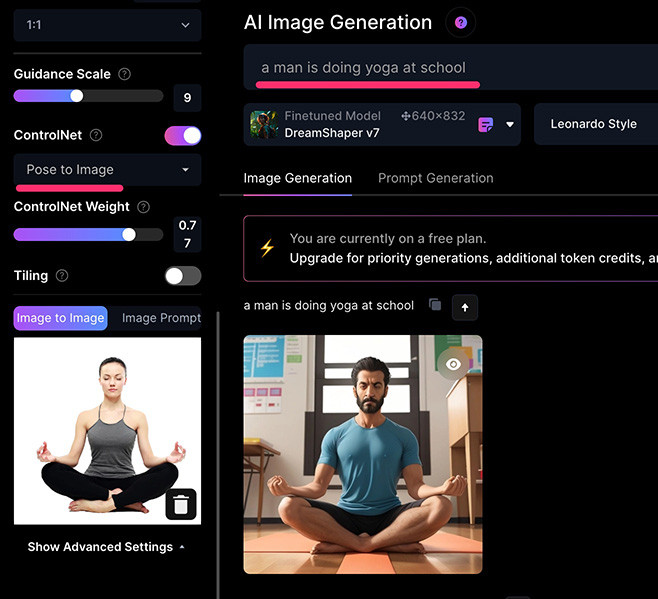
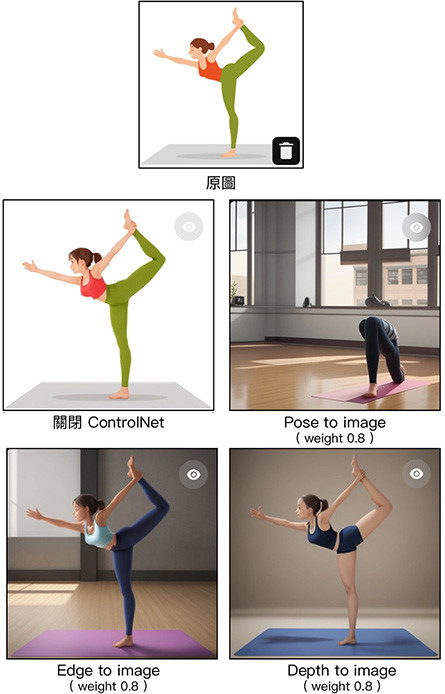
Pose to image 姿勢模式會擷取參考圖片中主體的「姿勢」,再將文字提示詞套用這個姿勢,擷取的姿勢類似下圖:

舉例來說,原本參考圖使用的瑜珈女性,根據提示「a man is doing yoga at school」產生圖片後,就變成一個男人用同樣的姿勢坐在學校裡。
使用 Pose to image 需要注意,Leonardo.Ai 判讀姿勢以「真人」為主,如果是插圖、動物...等非人的姿勢,在判讀上就會有差異,舉例來說,如果使用了插圖的瑜珈女生,產生的影像就會很詭異。
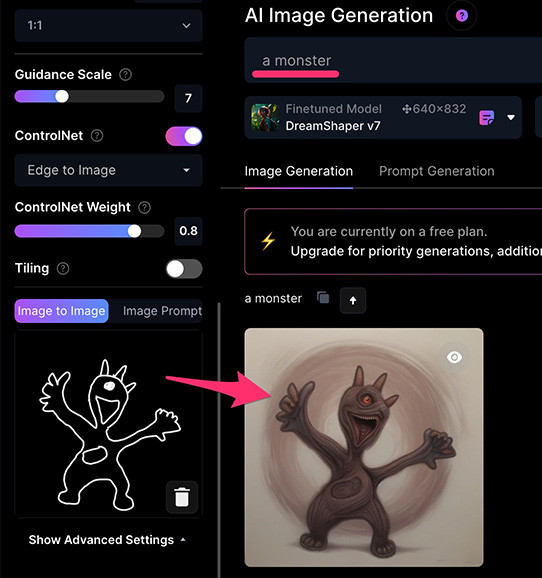
Edge to image 邊緣模式會擷取參考圖中主體的「邊緣」,再將文字提示套用這個邊緣,擷取的邊緣類似下圖:

下面的範例上傳了一張用小畫家隨意畫出的圖,套用文字提示「a monster」後,就會使用怪獸的造型與顏色,填滿白色邊緣。
如果使用插圖的瑜珈女性作為參考圖片,根據提示「a woman is doing yoga at school, realistic, photography」,就變成在學校裡做瑜珈的真人女生。
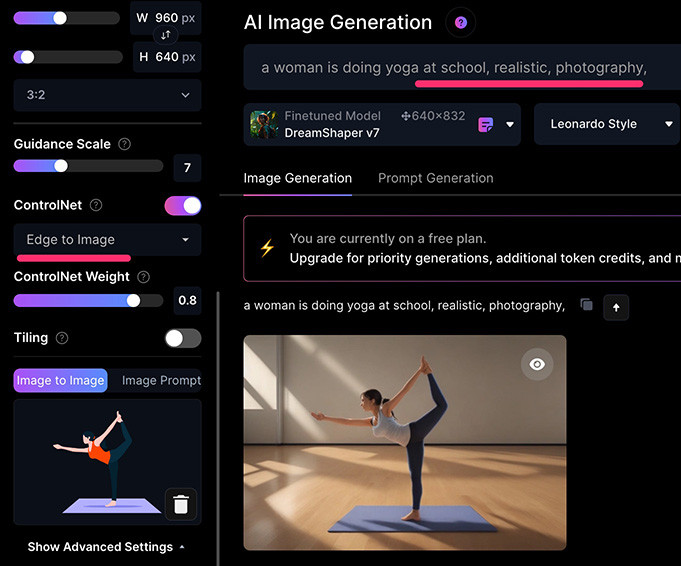
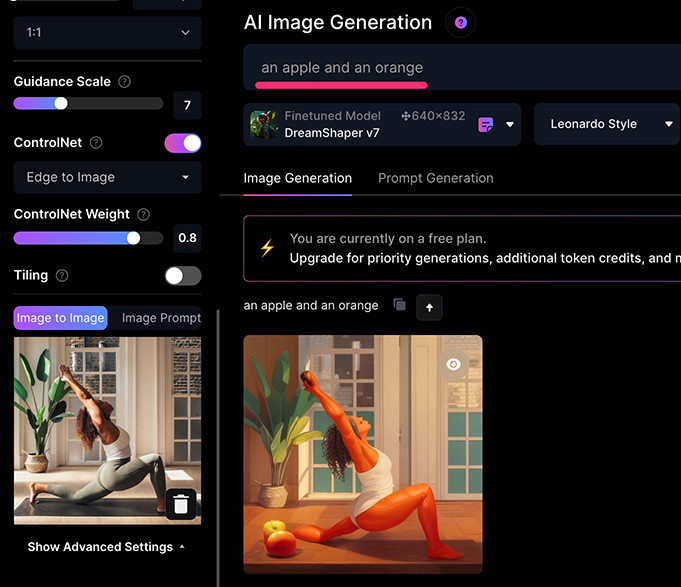
使用 Edge to image 需要注意,Leonardo.Ai 判讀後會「套用邊緣」,因此如果是和邊緣差異很多的文字提示,產生的結果就會很奇怪,例如參考圖使用女性瑜珈照片,提示詞卻是「an apple and an orange」,就會產生很奇怪的結果。
Depth to image 深度模式會擷取參考圖片中的「景深」,將文字提示套用在「清楚的景深」裡,擷取出來的景深類似下圖,會先產生黑白的影像,然後將文字提示套用在白色的部分,顏色越白套用越多。

下面的範例上傳了一張用小畫家隨意畫出的圖,套用文字提示後,就會發現女生的臉都產生在白色的區域。
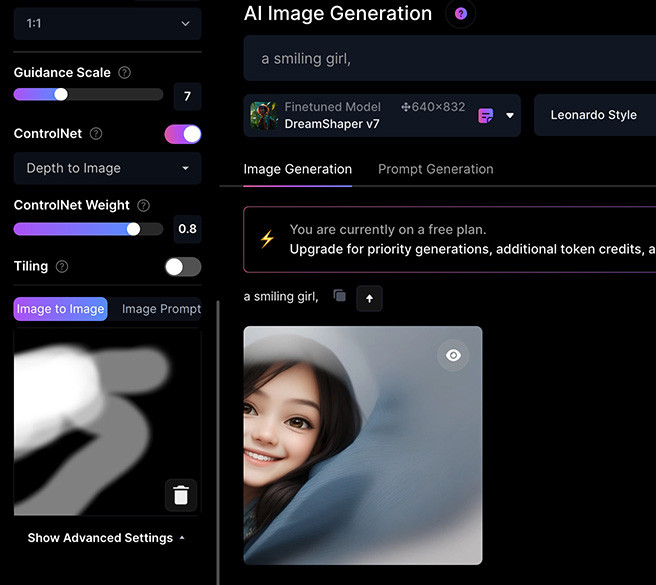
使用 Depth to image 需要注意,因為擷取景深的背後處理就是黑白模式,所以許多主體的細節會被忽略,而採用文字提示或由 Leonardo.Ai 自由發揮,例如下圖,產生影像中的女生就失去笑容 ( 因為提示沒有寫 )。
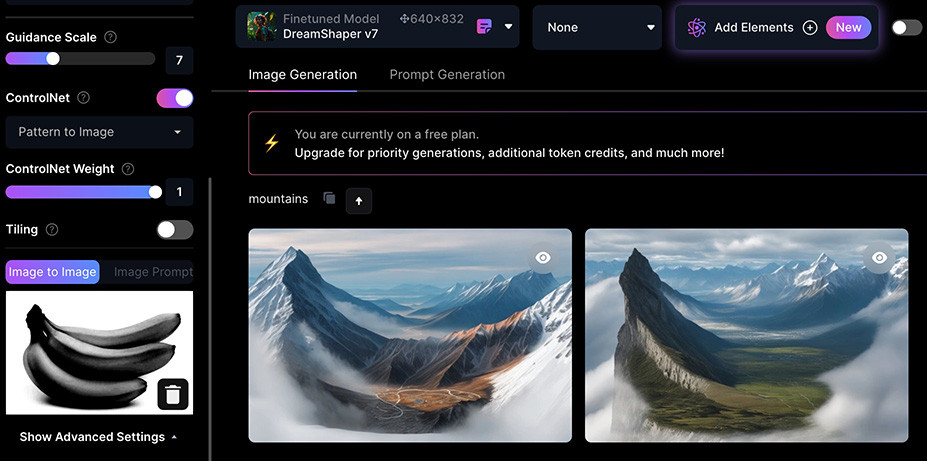
Pattern to image 圖案模式會擷取參考圖片中的「圖案與花紋」,將文字提示套用在「圖案與花紋」裡,換句話說會使用文字提示中的內容,產生出來類似圖案和花色的東西,舉例來說如果提供蘋果的圖片,但是提示為山脈,則產生的山脈會按照蘋果的圖案進行排列,變成由山脈組成的蘋果。
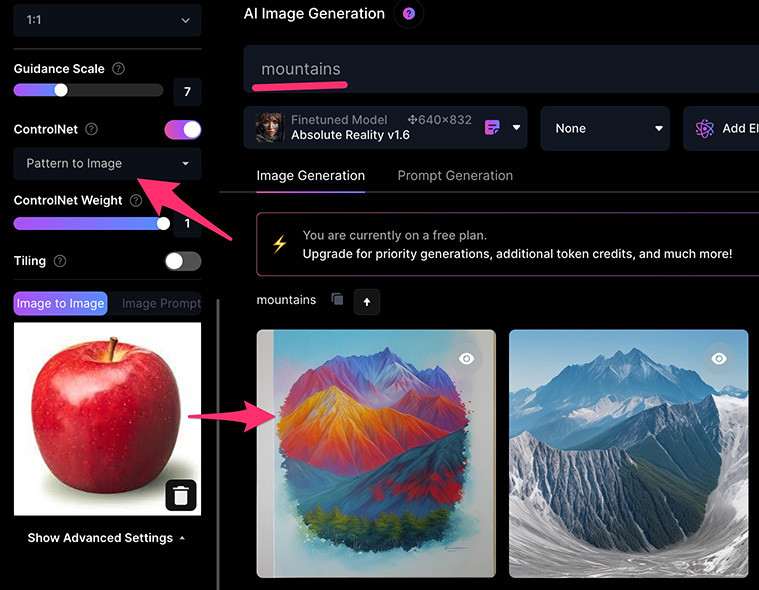
這個做法的原理其實會先將圖片進行「二值化」為黑白影像,再根據黑白影像繪製對應的內容,如果圖片的顏色對比不夠明顯,產生的黑白影像就會不夠清楚,得到的結果也就不盡理想,所以要使用 Pattern to Image,盡可能要讓「主體與背景的顏色對比明顯」,甚至可以直接使用其他繪圖軟體產生黑白影像,效果就會更好,舉例來說,下圖黃色香蕉白色背景,因為黃色白色太接近,二值化的效果不好,產生的香蕉圖案就不明顯。
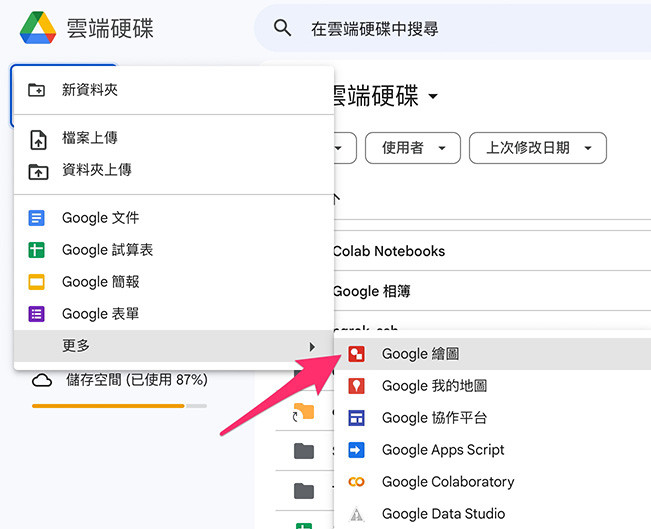
為了讓 Pattern to image 的效果更好,可以使用一些繪圖軟體增加圖片對比度,舉例來說可以使用 Google 雲端硬碟內建的「Google 繪圖」工具。
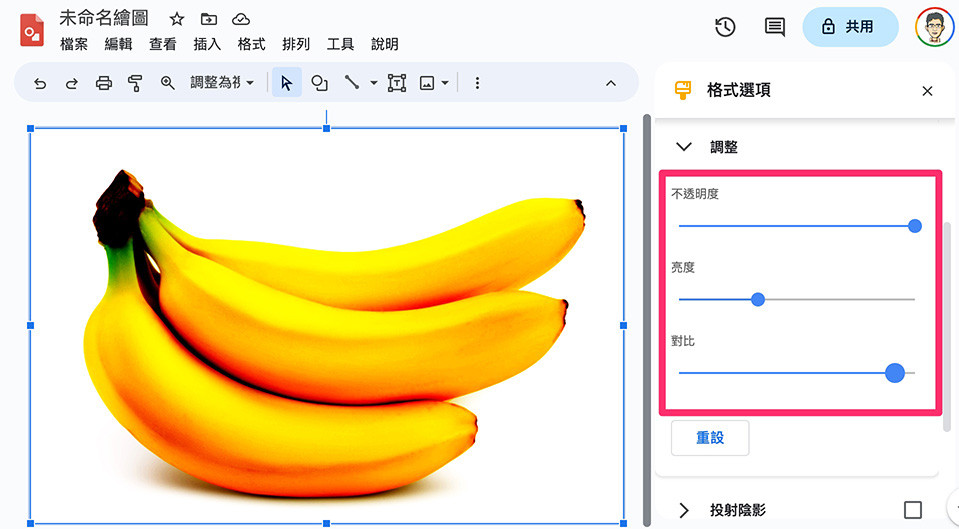
使用 Google 繪圖工具開啟香蕉圖片,調整香蕉的亮度和對比度,使其主體和背景的差異較為明顯 ( 也可調整顏色為灰階,效果更好 )。
完成後下載為 jpg 檔案。
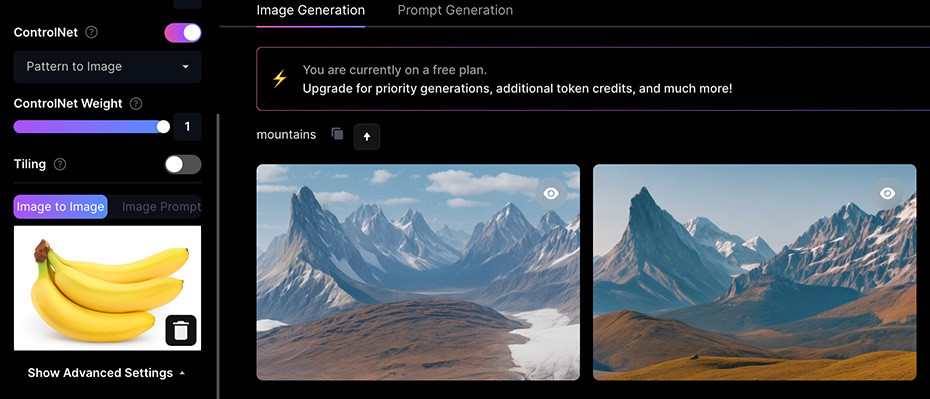
回到 Leonardo.Ai,使用調整後的香蕉產生影像,就能得到更為漂亮的隱藏香蕉影像了。
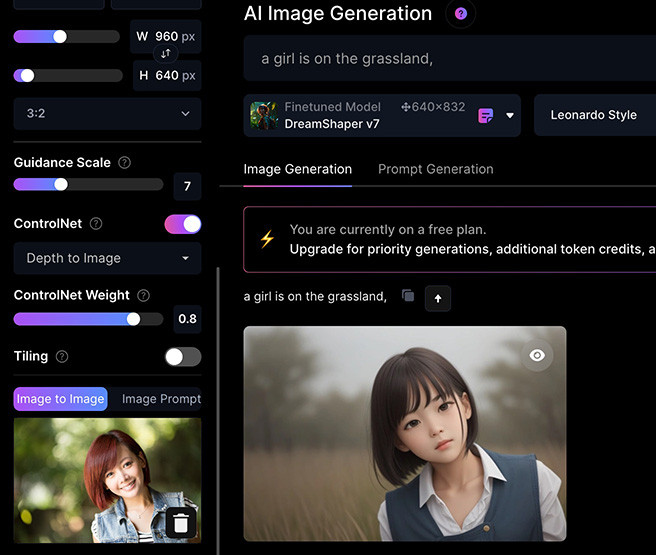
下圖呈現 Image to Image 不同模式下的差異,都使用同樣的提示詞「a girl is on the grassland」( 參考圖來源 ):

下圖呈現 Image to Image 不同模式下的差異,都使用同樣的提示詞「a girl is doing yoga at school, photography, realistic」:
「Image Prompt」功能可以提供「多張」圖片,並將圖片作為提示使用,功能類似 Midjourney 的 Blend,使用「Image Prompt」功能時會自動開啟「Prompt Magic」功能,不能和「PhotoReal」功能一起使用,相關設定說明如下:
- Guidance Scale:文字提示的比重,範圍 1~20 ( 官方建議 7~9 )。
- Image Weight:表示圖片提示比重,範圍 0.35~1,數值越高參考的程度越高。
- Tiling:產生無接縫連續貼圖。
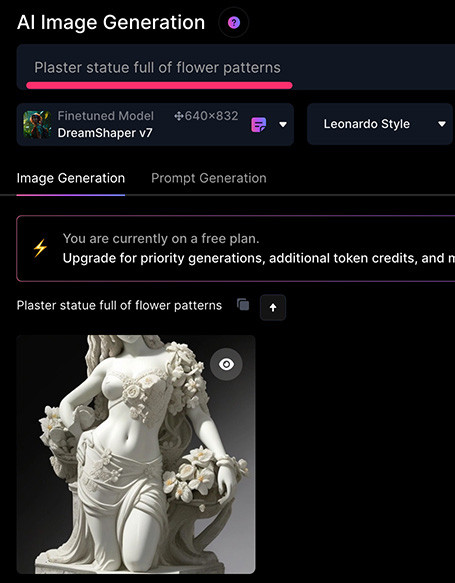
舉例來說,如果單純輸入「Plaster statue full of flower patterns」,會產生一個有花紋的石膏像,但石膏像的大小位置和花紋都無法精準控制。
如果上傳一張花朵的圖片作為 image prompt,產生的花紋就會接近圖片中的花朵。
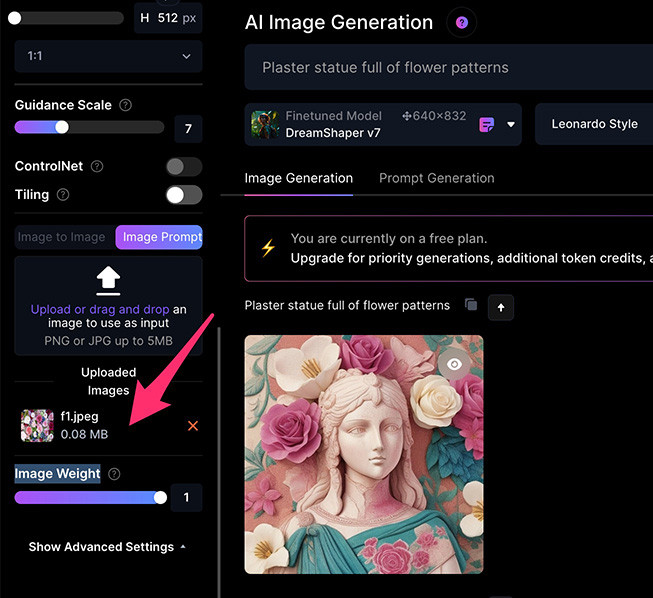
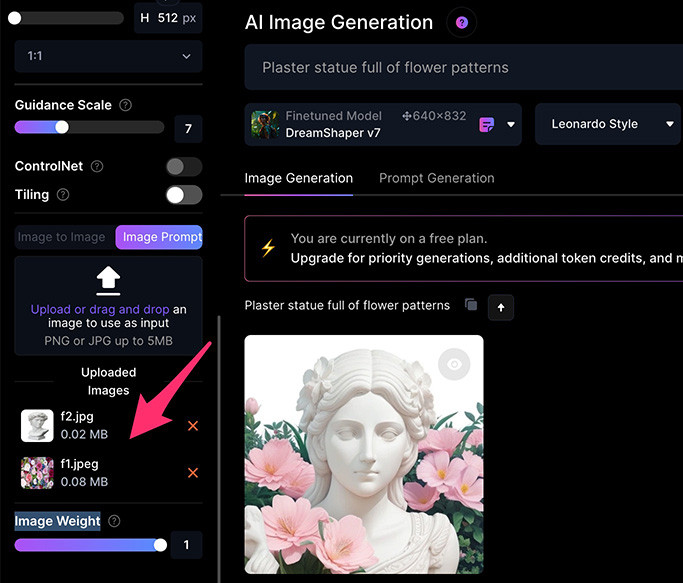
如果再上傳一張石膏像的圖片,則產生的石膏像就會更貼近這張圖片。
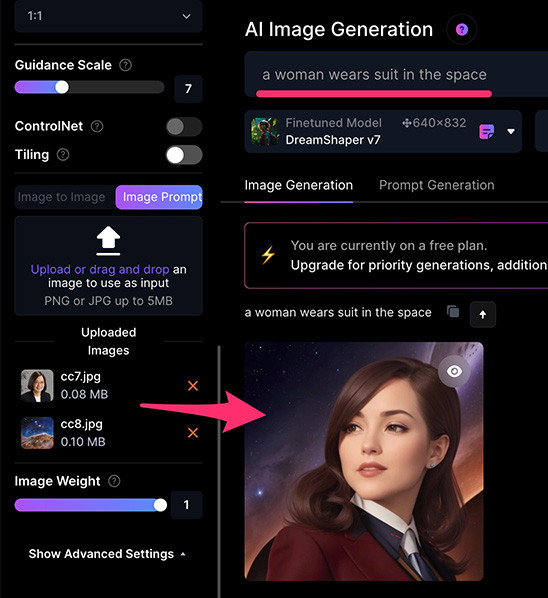
另外一個例子,使用穿西裝的女性和太空星雲的圖片,搭配「a woman wears suit in the space」提示詞,就可以產出穿襯衫女士在太空中的影像。
圖片產生圖片 ( Image to Image ) 是非常強大好用的功能,特別在於如果有看到喜歡的圖,但不知道文字提示該如何使用時,就能透過圖片來產生圖片,藉由圖片產生更多的創意。
大家好,我是 OXXO,是個即將邁入中年的斜槓青年,我有個超過一千篇教學的 STEAM 教育學習網,有興趣可以參考下方連結呦~ ^_^

 iThome鐵人賽
iThome鐵人賽