之前玩了好幾天的文字生成影像服務~但這些熱門服務是如何達到那麼好的影像生成效果呢?今天的文章就是要簡單介紹這些服務背後的 AI 模型架構。
Stable Diffusion、DALL·E 系列和 Imagen 這三種模型都有發表 paper,基本上這些模型都由三個部分組成:
以上三個部分會分開訓練再組合起來。
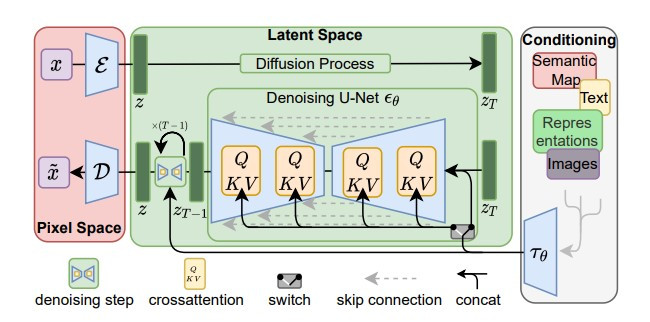
(圖片來源:High-Resolution Image Synthesis with Latent Diffusion Models)
Stable Diffusion 如前面概述所提到的,也可以分為三個部分。
最右邊 "Conditioning" 的部分可以將條件壓縮為 latent representation,而且依照架構圖,它不只能處理文字條件的輸入,也能處理影像、表徵等其他條件。
中間 "Latent Space" 呈現的是利用 diffusion model 產生影像的 latent representation(也就是前面提到的壓縮向量),而條件的 latent representation 會在每一個 step 也一起輸入到 denoise 模組中,引導影像 latent representation 的生成。而由於這個 diffusion model 生成的是影像的 latent representation,因此被稱為 latent diffusion model。
最左邊的 "Pixel Space" 呈現的則是將影像的 latent representation 重建/解碼為影像的過程,通過這個步驟我們就可以獲得精美的影像了~~
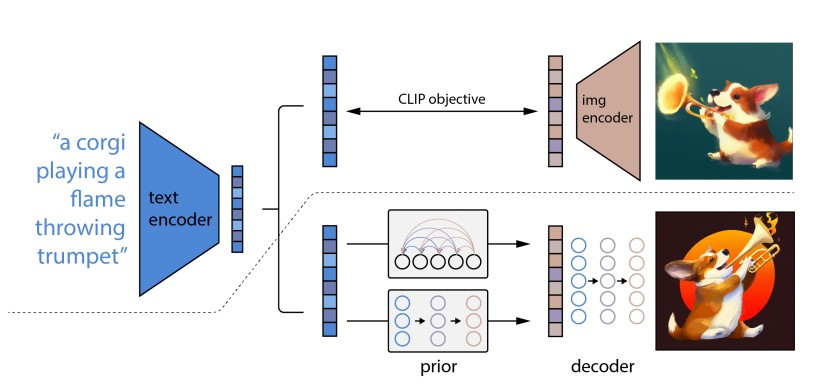
(圖片來源:Hierarchical Text-Conditional Image Generation with CLIP Latents)
DALL·E 系列基本上也是一樣的道理。上圖的虛線以上呈現的是模型的訓練過程,虛線以下則是實際生成影像的過程。
如同先前描述的,DALL·E 首先有一個 text encoder 來處理文字條件/prompt,得到壓縮的語意向量,接著通過 diffusion model 或 autoregressive model 得到和文字對應的影像 latent representation。最後,影像 latent representation 輸入到 decoder 就可以得到完整的影像了!而 DALL·E 使用的 decoder 其實也是 diffusion model。
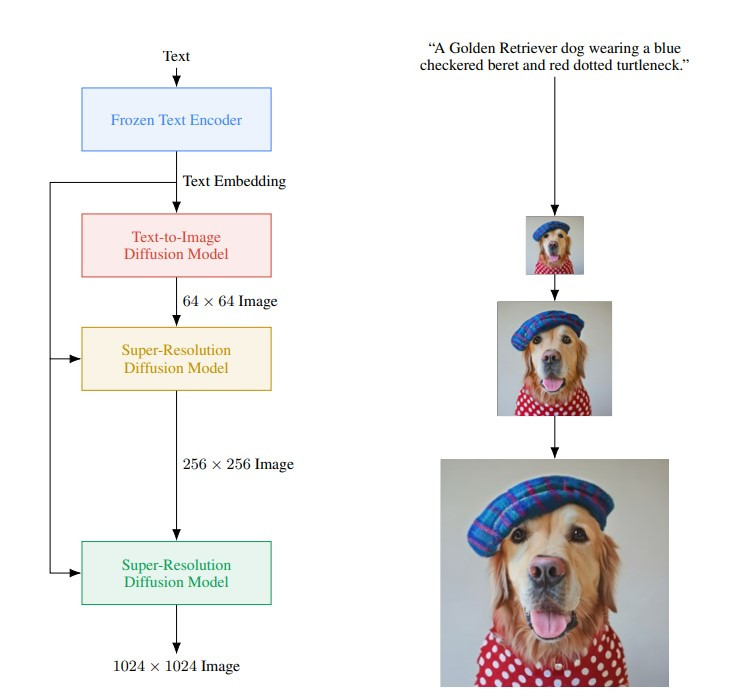
(圖片來源:Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding)
Imagen 生成影像的流程圖其實蠻清楚的,一樣是用 text encoder 來將文字 prompt 壓縮成 text embedding(也就是先前提到的壓縮向量或 latent representation),接著用 diffusion model 得到和文字對應的 64x64 的小圖。和前面模型不同的是,Imagen 的生成模型產生出來的東西是人看得懂的影像,只是解析度較低。最後會再用兩個 diffusion models 將生成的小圖逐漸放大,就可以得到我們期望的高解析度影像了!

