前一天的文章介紹了目前最前端的幾個文字生成影像模型,但大家是否有個疑惑:明明 diffusion model 就可以依據文字產生品質不錯的影像了,為什麼這些新的方法要組合三個模型,而且讓 diffusion model 產生影像的 latent representation 而非影像呢?
今天的文章要帶大家快速瀏覽 Stable Diffusion 的 paper High-Resolution Image Synthesis with Latent Diffusion Models,簡單介紹 Stable Diffusion 的原理、訓練方法與優點~
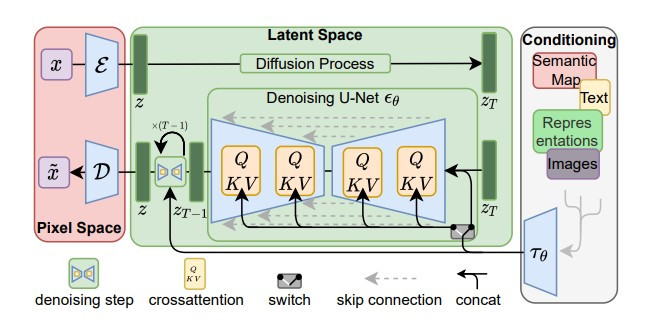
(圖片來源:High-Resolution Image Synthesis with Latent Diffusion Models)
先回顧一下昨天的內容,Stable Diffusion 模型可以拆解為三個部分:
那麼,使用 latent diffusion model 的好處是什麼呢?一個最大的優點就是節省計算資源
讓 diffusion model 直接產生一張影像,包含它的每個 pixel 的 RGB 數值,是非常耗費計算資源的。根據 paper 提供的資訊,要訓練一個功能強大的 diffusion model 約需要 150 到 1000 個 V100 days,意思就是要使用一張 V100 GPU 訓練 150 到 1000 天。而在訓練好之後,讓模型運作在一張 A100 GPU 上,約需要五天才能產生 5 萬張影像,5 萬張影像聽起來很多,但要成為大眾能廣泛使用的影像生成服務是遠遠不足的,這樣的高計算資源消耗也會局限模型能應用的情況。
而 latent diffusion model 可以明確的改善這個問題,因為產生的是影像壓縮的向量。壓縮的比例如果調整得當,能在盡可能避免影像品質損失的情況下,更有效率的生成影像~
至於如何訓練 Stable Diffusion 呢?訓練會分為兩個階段:
首先,利用大量無標註影像訓練一個 auto-encoder,這個 auto-encoder 會學到影像資料和 latent representation 的轉換關係,如此一來 diffusion model 才能學習生成有影像意義的 latent representation。而 decoder 的部分之後就可以用來將 diffusion model 產生的影像 latent representation 解碼重建成影像~
這個 auto-encoder 的 latent space 可以用一些 regularization 的方法做限制,如果引入 KL divergence 作為 regularization,就是我們之前介紹的 VAE(variational auto-encoder),此外 paper 中也有使用 vector quantization 的方法進行 regularization。
而訓練的第二階段,就是用影像的 latent representation,先經過加 noise 的 forward process,再用來訓練 latent diffusion model 的 denoise 模組了。和之前介紹 diffusion model 相似的是,step 和控制條件也會輸入到每一步的 denoise 模組,而 Stable Diffusion 為了更好的處理控制條件,使用 cross-attention layer 進一步處理條件的 representation。
這樣的流程也使得進行 diffusion model 的實驗更加容易。由於 latent diffusion model 的計算成本也比 pixel space 的 diffusion model 低不少,我們只需要訓練一次 auto-encoder,就可以嘗試用不同的 latent diffusion model 進行更多的實驗~

