昨天簡單的介紹了 Stable Diffusion,它是目前最先進的條件式影像生成模型其中之一,而今天的文章則要介紹另一個也被認為是最先進的文字生成影像模型,也就是 OpenAI 所開發的 DALL·E 2。
DALL·E 2 paper:Hierarchical Text-Conditional Image Generation with CLIP Latents
在 DALL·E 2 paper 的一開始就呈現了他們產品層級的模型能達到什麼樣的影像生成效果,可說是想生成什麼就生成什麼,也包含各種的影像風格,使用者可以發揮各種創意

(圖片來源:Hierarchical Text-Conditional Image Generation with CLIP Latents)
仔細探究 DALL·E 2 的模型架構,其實和 Stable Diffusion 相差不大,但在 Stable Diffusion 強調的是利用 latent space 的 diffusion model 減低運算資源,而 DALL·E 2 則強調結合將文字和影像表徵對應起來的 CLIP(Contrastive Language-Image Pre-training)和 latent diffusion model。
首先來簡介一下 CLIP(Contrastive Language-Image Pre-training)這個技術,CLIP 是指用對比學習(constrastive learning)的方式將文字和影像的表徵(representation)對應起來的技術,它在提出之後逐漸成為熱門的模型預訓練方法,透過這種方式預訓練的模型可以用在影像分類、影像生成、文本分類等多種下游任務。
它的訓練方式如下圖,首先我們會準備大量成對的文字和影像,分別透過 text encoder 得到文字的 representation,image encoder 得到影像的 representation,然後要讓模型學習讓同一對的文字和影像 representation 越相近越好,而不同對的 representation 則要越不相像。
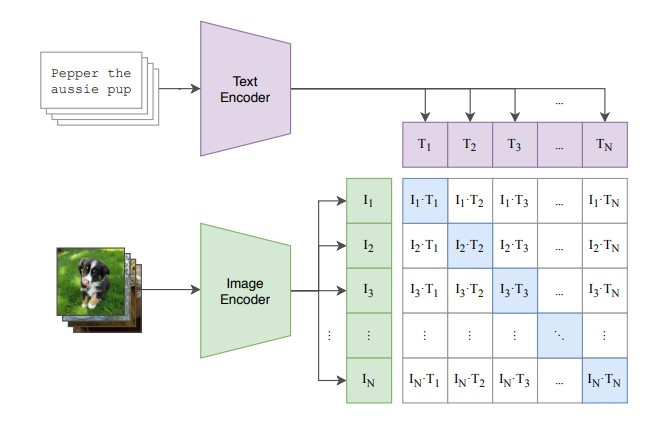
(圖片來源:Learning Transferable Visual Models From Natural Language Supervision)
如此一來我們就可以得到文字和影像意義共通的表徵空間了,它就非常適合用於利用文字條件引導影像生成的情況。
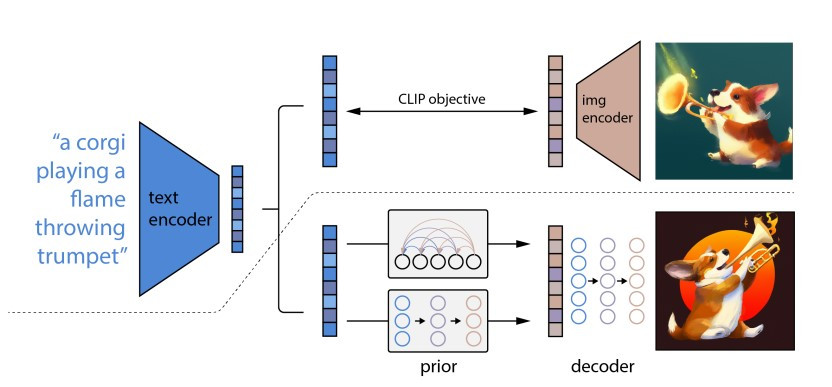
(圖片來源:Hierarchical Text-Conditional Image Generation with CLIP Latents)
在我們已經用 CLIP 讓影像和文字表徵對應在一起後,DALL·E 2 的訓練基本上可以分為兩個部分:
首先是訓練根據文字產生影像 latent representation 的生成模型,在這個研究中 OpenAI 分別實驗用 diffusion model 和 autoregressive model 作為生成模型。
Autoregressive model 在之前沒有介紹過,簡單來說,當我們要模型生成影像的 representation 的時候,它一次只會生成 representation 的一部分,然後再基於已經生成的部分再產生一部份的 representation,如此序列式的生成,直到完整產生出一組 representation。
由於 autoregressive model 計算量實在很大,因此這個研究在訓練模型時還要將 CLIP 得到的 representation 用 PCA 降維。
相對的,diffusion model 的生成過程就是一步到位,一次直接從模型產生完整的 representation。
Diffusion model 基本上和之前介紹得差不多,但比較不同的是,這個研究發現訓練模型直接預測降噪後的 representation,會比先預測 noise 再讓輸入減去 noise 的效果好。而實驗的結論是使用 diffusion model 有更高的效率而且生成影像的品質也比較好。
從 DALL·E 2 的 paper 看起來,其實有不只一個 decoder 將影像的 representation 轉換為最終生成的影像。
第一個 decoder 會將影像的 representation 轉換解析度較低的小圖,它背後的模型其實就是 diffusion model,因此也可以輸入文字條件引導影像的重建,而用文字條件引導對於影像的重建是有幫助的。
除了以上的 decoder 外,後續還有其他的 decoder 會將小圖一步一步放大為較高解析度的影像,這部分也是使用 diffusion model,不過經過實驗發現加入文字輸入的引導對於影像放大沒有幫助。
雖然 DALL·E 2 的 paper 實際上還有很多內容,不過今天的文章就先以 DALL·E 2 可以如何控制影像生成作結~
在這個研究中展示了我們可以用幾種方法控制 DALL·E 2 生成影像:
我們可以輸入一張影像,在生成模型保有隨機性的情況下,DALL·E 2 可以根據輸入影像產生內容與風格相近但細節不同的影像。
如下圖,最上面的兩張小圖是輸入到 DALL·E 2 的影像,而下面的數張小圖則是 DALL·E 2 產生的相似影像,可以發現 DALL·E 2 保留了時鐘與樹的意象、超現實的風格、交疊筆畫形式的 logo 和漸層的背景,但每一張影像都各有不同~

(圖片來源:Hierarchical Text-Conditional Image Generation with CLIP Latents)
我們也可以透過 image encoder 得到兩張不同影像的 representation,並透過內插的方式得到介於兩者之間的 representation,最後利用 decoder 重建出影像就可以得到結合兩張輸入影像特色的生成影像。
如下圖所示,最左和最右分別是兩張不同的輸入影像,而中間是依照不同的比例內插 representation 產生的影像。原本梵谷的星夜和柯基照片完全八竿子打不著關係,但結合他們的 representation 之後就可以得到有梵谷畫風的柯基在星夜中的影像

(圖片來源:Hierarchical Text-Conditional Image Generation with CLIP Latents)
最後,DALL·E 2 結合 CLIP 最大的優點就是,我們得到一個文字和影像共通的表徵空間,因此我們可以先計算兩段語意有些差異的文字 representation 的差距,並加到影像的 representation 上,以微調影像的生成。
例如下圖第一列,最左邊原本是照片風格的貓,但可以透過這樣的方式逐漸朝超級賽亞人(XD)的風格調整

(圖片來源:Hierarchical Text-Conditional Image Generation with CLIP Latents)

