上一篇提到我們的模型出來的 CER 並不是非常理想,因此為了讓模型轉錄出來的結果更好,我們需要對模型進行 Fine-tuning,也就是微調我們的模型
在那之前我們可以先知道一個 AI 論壇 —— Huggingface
Huggingface 其實就是一個大家可以在上面討論各種 AI 相關問題,同時也可以把自己做好的模型上架到網站,開放給所有人使用下載
進去上面的 Model 會看到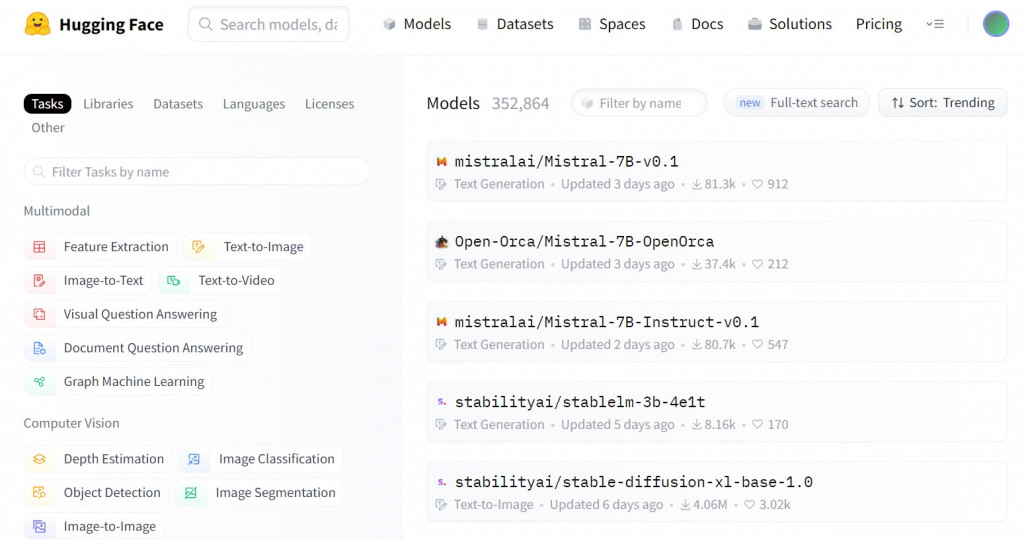
左邊可以選擇你現在想處理的功能或任務(tasks),像我現在處理 ASR 的話就會看比較下面的 Audio 那一區,然後選擇 ASR
右邊就會出現能夠處理 ASR 的 model
看到有興趣的就能把它抓下來使用
處理機器學習相關的模型時,資料集絕對是一個非常非常重要的事,所幸 huggingface 也有提供許多 Datasets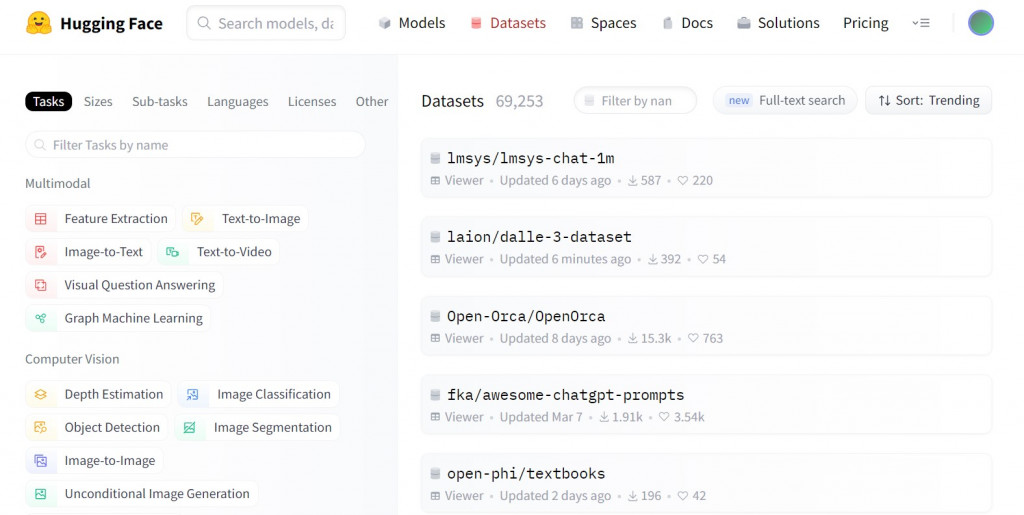
這邊稍微提一下,如果想找台灣專門使用的 Datasets,我會推薦去找 mozilla/common_voice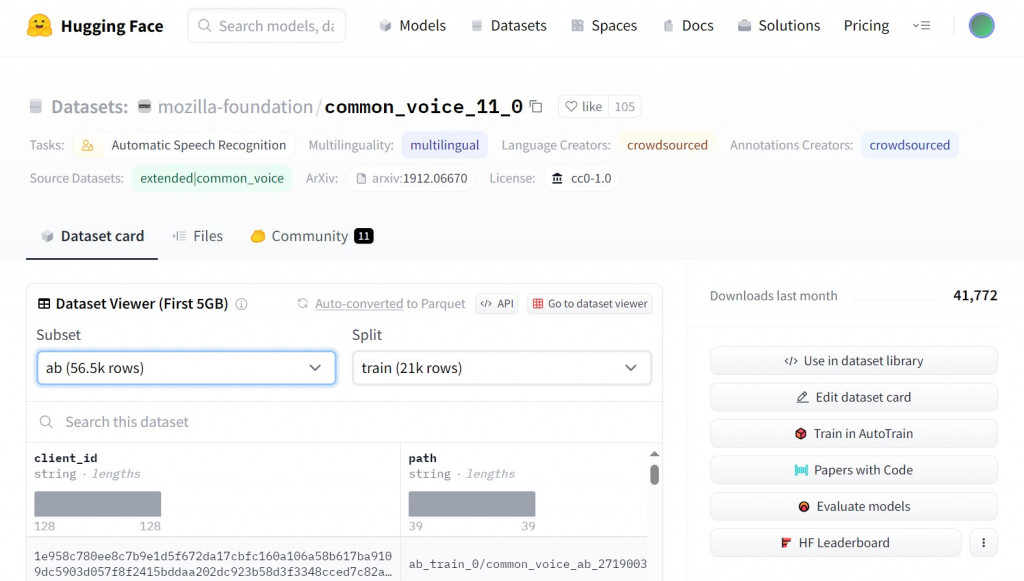
我們可以在 Subset 的地方滑到最底下選擇 zh-TW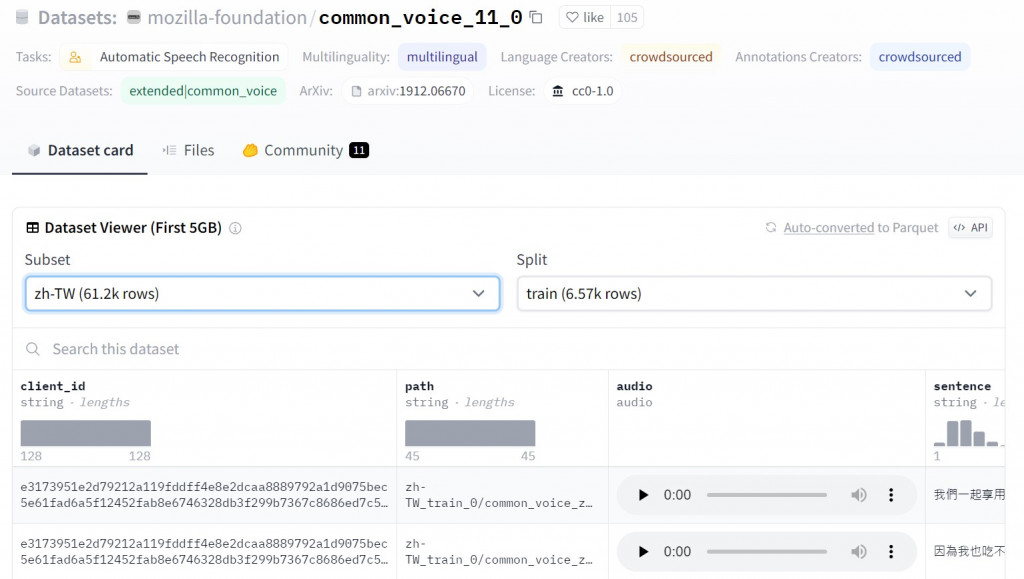
下方可以看到每筆資料的資訊,也能夠撥放聲音出來聽聽
我記得 common voice 應該是開放性的,如果你有興趣也可以去他們的網站提供自己的聲音作為 Datasets 的一部分
或是檢測別人的音檔,看是否有說錯的地方,增加這個開源的資料庫
無聊就能上去玩一下,模型訓練的資料真的很難取得QQ
簡單介紹了 huggingface 可以幹嘛,接下來就會玩玩看上面的東西了!
國慶太可怕了,會帶人進入怠惰的深淵,一次要補兩篇...

