現在我們即將進入 Grafana Loki 實戰演練環節。在這一章節中,我們會在本地的 Kubernetes 叢集中搭建 Loki 分佈式日誌系統。藉由之前章節所學的知識,我們將逐步完善其設定,使其達到適用於生產環境的標準。在這個過程中,我們不僅會探討實際操作的技巧,還會搶先使用不存在預設設定中的 Loki 最新功能,確保 Loki 的效能與穩定性都能達到頂尖水準。

擁抱開源社群的專案是美好的,套用在我們正要準備安裝 Grafana Loki 是再貼切不過了。因為社群上依照部署的複雜程度,分別提供了從最簡單的單體模式到顆粒最細微的微服務模式,讓我們有了這個甜蜜的煩惱,就來看看這些部署模式架構上的差異吧。
Grafana Loki 的部署模式概念上可以分為單體和微服務模式。
單體模式是 Grafana Loki 中最簡單的操作設定,開箱及用,對第一次體驗的人非常友善。單體模式可以讓我們在單一進程、一個二進制檔、一個 Docker Image 中,運作起包含所有微服務組件。
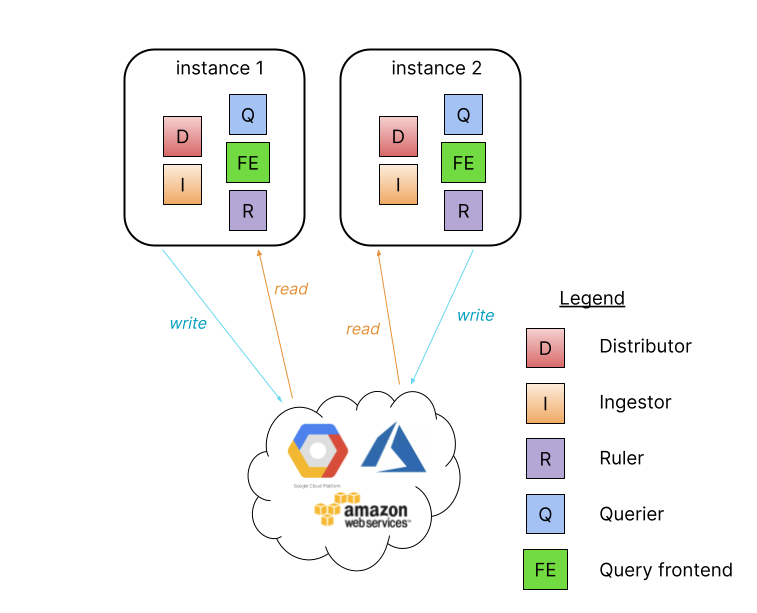
當我們無法使用單體模式滿足需求或者需要讀寫分離時,Grafana Loki 提供了簡單的讀寫可擴展模式,可以單獨分別為讀服務和寫服務,按需求提升效能與可用性。
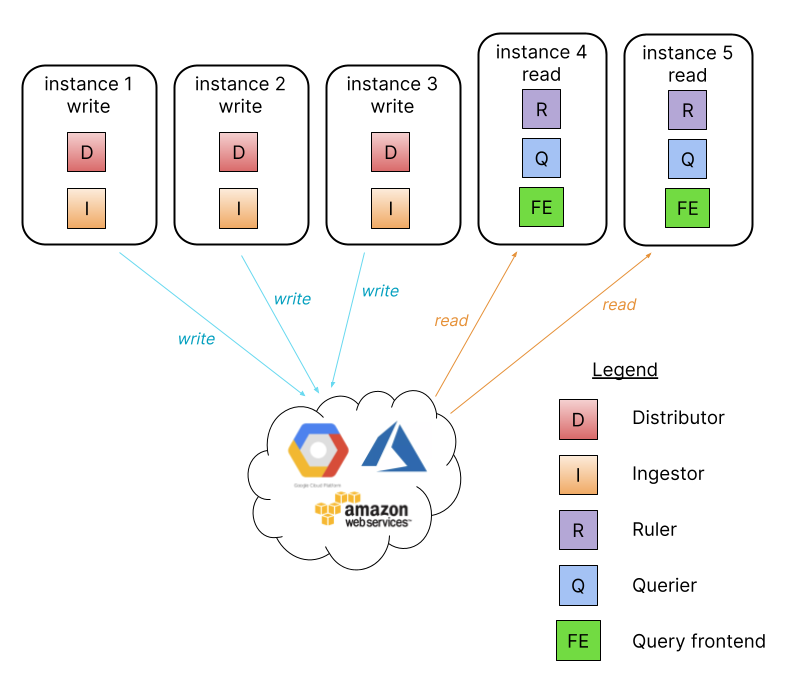
微服務模式將 Grafana Loki 的組件實例化成不同個別服務,提供最細的顆粒調整。此模式可以單獨以每個最小組件為擴展單位,是所有模式中最有效率的選擇,但它同時也是設定與維護門檻最高的。
Installed components:
helm search repo loki | grep grafana/loki
------
NAME CHART VERSION APP VERSION DESCRIPTION
grafana/loki 5.22.0 2.9.1 Helm chart for Grafana Loki in simple, scalable...
grafana/loki-canary 0.13.1 2.8.4 Helm chart for Grafana Loki Canary
grafana/loki-distributed 0.74.2 2.9.1 Helm chart for Grafana Loki in microservices mode
grafana/loki-simple-scalable 1.8.11 2.6.1 Helm chart for Grafana Loki in simple, scalable...
grafana/loki-stack 2.9.11 v2.6.1 Loki: like Prometheus, but for logs.
Grafana Loki 在我們的安裝管理套件 Helm 中的選擇,也擁有了眼花撩亂的甜蜜煩惱,但經過我們對其的認識後,我們現在也能夠一一拆解並了解其中的差異,選擇出最適合自己的專屬 Helm Chart:
雖然 Grafana 團對在 2022 年底,對外宣佈了日後將專注於維護 grafana/loki 這個 Helm Chart,但 grafana/loki-distributed 的 Helm Chart 依然深受社群喜愛、擁簇,或許也有很大部分的人們跟我們一樣,對那些被包裝過的組件中的魔法充滿好奇,想要盡可能一探究竟,接下來就讓我們使用 grafana/loki-distributed 來一一深入已經初步認識的組件吧。
在接下來的實戰中,我們將利用先前建立好的 Kube-Prometheus-Stack 及其相關設定來當作 Grafana Loki 的可視化介面,其中詳細安裝過程可以回頭複習一下「Kube-Prometheus-Stack 實戰系列」。
現在我們要使用 values.yaml、config.yaml 兩個參數檔,進行對 Grafana Loki 的設定。
# values.yaml
fullnameOverride: loki
customParams:
authEnabled: true
serviceMonitor:
enabled: true
prometheusRule:
enabled: true
ingester:
kind: StatefulSet
replicas: 1
autoscaling:
enabled: false
resources: {}
distributor:
replicas: 1
autoscaling:
enabled: false
resources: {}
querier:
replicas: 1
autoscaling:
enabled: false
resources: {}
queryFrontend:
replicas: 1
autoscaling:
enabled: false
resources: {}
queryScheduler:
enabled: true
replicas: 2
affinity: ''
resources: {}
gateway:
enabled: true
replicas: 1
autoscaling:
enabled: false
resources: {}
basicAuth:
enabled: true
username: log-user
password: log-password
compactor:
enabled: true
resources: {}
values.yaml 主要針對所有組件在 Kubernetes 叢集中的相關資源設定。
# configmap.yaml
loki:
config: |
auth_enabled: {{ .Values.customParams.authEnabled }}
server:
{{- toYaml .Values.loki.server | nindent 6 }}
common:
compactor_address: http://{{ include "loki.compactorFullname" . }}:3100
distributor:
ring:
kvstore:
store: memberlist
memberlist:
join_members:
- {{ include "loki.fullname" . }}-memberlist
ingester_client:
grpc_client_config:
grpc_compression: gzip
ingester:
lifecycler:
ring:
kvstore:
store: memberlist
replication_factor: 1
chunk_idle_period: 30m
chunk_block_size: 262144
chunk_encoding: snappy
chunk_retain_period: 1m
max_transfer_retries: 0
wal:
dir: /var/loki/wal
limits_config:
enforce_metric_name: false
reject_old_samples: true
reject_old_samples_max_age: 168h
max_cache_freshness_per_query: 10m
split_queries_by_interval: 15m
{{- if .Values.loki.schemaConfig}}
schema_config:
{{- toYaml .Values.loki.schemaConfig | nindent 2}}
{{- end}}
{{- if .Values.loki.storageConfig}}
storage_config:
{{- if .Values.indexGateway.enabled}}
{{- $indexGatewayClient := dict "server_address" (printf "dns:///%s:9095" (include "loki.indexGatewayFullname" .)) }}
{{- $_ := set .Values.loki.storageConfig.boltdb_shipper "index_gateway_client" $indexGatewayClient }}
{{- end}}
{{- toYaml .Values.loki.storageConfig | nindent 2}}
{{- if .Values.memcachedIndexQueries.enabled }}
index_queries_cache_config:
memcached_client:
addresses: dnssrv+_memcached-client._tcp.{{ include "loki.memcachedIndexQueriesFullname" . }}.{{ .Release.Namespace }}.svc.{{ .Values.global.clusterDomain }}
consistent_hash: true
{{- end}}
{{- end}}
runtime_config:
file: /var/{{ include "loki.name" . }}-runtime/runtime.yaml
chunk_store_config:
max_look_back_period: 0s
{{- if .Values.memcachedChunks.enabled }}
chunk_cache_config:
embedded_cache:
enabled: false
memcached_client:
consistent_hash: true
addresses: dnssrv+_memcached-client._tcp.{{ include "loki.memcachedChunksFullname" . }}.{{ .Release.Namespace }}.svc.{{ .Values.global.clusterDomain }}
{{- end }}
{{- if .Values.memcachedIndexWrites.enabled }}
write_dedupe_cache_config:
memcached_client:
consistent_hash: true
addresses: dnssrv+_memcached-client._tcp.{{ include "loki.memcachedIndexWritesFullname" . }}.{{ .Release.Namespace }}.svc.{{ .Values.global.clusterDomain }}
{{- end }}
table_manager:
retention_deletes_enabled: false
retention_period: 0s
query_range:
align_queries_with_step: true
max_retries: 5
cache_results: true
results_cache:
cache:
{{- if .Values.memcachedFrontend.enabled }}
memcached_client:
addresses: dnssrv+_memcached-client._tcp.{{ include "loki.memcachedFrontendFullname" . }}.{{ .Release.Namespace }}.svc.{{ .Values.global.clusterDomain }}
consistent_hash: true
{{- else }}
embedded_cache:
enabled: true
ttl: 24h
{{- end }}
frontend_worker:
{{- if .Values.queryScheduler.enabled }}
scheduler_address: {{ include "loki.querySchedulerFullname" . }}:9095
{{- else }}
frontend_address: {{ include "loki.queryFrontendFullname" . }}-headless:9095
{{- end }}
frontend:
log_queries_longer_than: 5s
compress_responses: true
{{- if .Values.queryScheduler.enabled }}
scheduler_address: {{ include "loki.querySchedulerFullname" . }}:9095
{{- end }}
tail_proxy_url: http://{{ include "loki.querierFullname" . }}:3100
compactor:
shared_store: filesystem
ruler:
storage:
type: local
local:
directory: /etc/loki/rules
ring:
kvstore:
store: memberlist
rule_path: /tmp/loki/scratch
alertmanager_url: https://alertmanager.xx
external_url: https://alertmanager.xx
### Custom Configs ###
query_scheduler:
max_outstanding_requests_per_tenant: 32768 # default 100
querier:
max_concurrent: 16 # default 10
schemaConfig:
configs:
- from: "2023-01-05"
store: tsdb
object_store: filesystem
schema: v11
index:
period: 24h
prefix: loki_index_
storageConfig:
tsdb_shipper:
active_index_directory: /var/loki/tsdb-index
cache_location: /var/loki/tsdb-cache
shared_store: filesystem
filesystem:
directory: /var/loki/chunks
config.yaml 提供了 Grafana Loki 中每個組件的設定參數調教以及相關儲存設定。
helm upgrade --install loki grafana/loki-distributed -f values.yaml -f config.yaml -n logging --version 0.74.2
------
Release "loki" does not exist. Installing it now.
NAME: loki
LAST DEPLOYED: Tue Sep 19 23:15:17 2023
NAMESPACE: logging
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
***********************************************************************
Welcome to Grafana Loki
Chart version: 0.74.2
Loki version: 2.9.1
***********************************************************************
Installed components:
* gateway
* ingester
* distributor
* querier
* query-frontend
* query-scheduler
* compactor
接下來我們就可以在 Kubernetes 叢集中看到熟悉各種 Loki 組件:
kubectl get pods -n logging
------
NAME READY STATUS RESTARTS AGE
loki-compactor-57d64f4f9d-lndcw 1/1 Running 0 115m
loki-distributor-6c7d7ff64c-6jx8x 1/1 Running 0 115m
loki-gateway-6c79cb7b45-4qmh5 1/1 Running 0 23h
loki-ingester-0 1/1 Running 0 115m
loki-querier-0 1/1 Running 0 115m
loki-query-frontend-67f5489cf9-67xj4 1/1 Running 0 115m
loki-query-scheduler-7b59cf7768-d4q6m 1/1 Running 0 115m
loki-query-scheduler-7b59cf7768-s4p5v 1/1 Running 0 114m
現在我們已經成功運作起來完整的微服務模式 Grafana Loki,但如果我們只空有日誌服務卻沒有人來幫忙推送日誌過來是不行的,所以我們需要一位可靠的 Log Agent 擔任對 Grafana Loki 發送日誌的角色。
Promtail 是 Grafana Loki 自家開發的 Log Agent,可以從 Grafana 官方文件找到非常豐富的設定範例。當然我們也可以使用先前提到的 Grafana Agent,但由於 Grafana Agent 太過於強大,非常適合額外介紹,這裡我們就使用更簡易的 Promtail。
# values.yaml
fullnameOverride: promtail
daemonset:
enabled: true
config:
clients:
- url: http://loki-gateway.logging/loki/api/v1/push
tenant_id: log-user
external_labels:
cluster: docker-desktop
basic_auth:
username: log-user
password: log-password
可以看到 Promtail 對於在 Kubernetes 環境下的 Grafana Loki 設定開箱及用,不需要額外設定即可快速收集到每個資源的日誌,基本上我們只要把指向 clients 到我們剛建立的 Grafana Loki 即可。
helm upgrade --install promtail grafana/promtail -f values.yaml -n logging --create-namespace
------
Release "promtail" does not exist. Installing it now.
NAME: promtail
LAST DEPLOYED: Wed Sep 20 00:45:11 2023
NAMESPACE: logging
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
***********************************************************************
Welcome to Grafana Promtail
Chart version: 6.15.1
Promtail version: 2.8.4
***********************************************************************
Verify the application is working by running these commands:
* kubectl --namespace logging port-forward daemonset/promtail 3101
* curl http://127.0.0.1:3101/metrics
現在 Promtail 將會以 Daemonset 資源存在 Kubernetes 中為我們收集所有 Pod 的日誌了。
kubectl get daemonset -n logging
------
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
promtail 1 1 1 1 1 <none> 23h
以下將詳細拆解我們使用到的參數設定檔,幫助大家了解實際設定。
serviceMonitor:
enabled: true
prometheusRule:
enabled: true
幫助我們預先建立 Grafana loki 的 serviceMonitor 以及 prometheus Rule,提供開箱及用的 Prometheus 指標設定和告警。
querier:
replicas: 1
autoscaling:
enabled: false
resources: {}
queryFrontend:
replicas: 1
autoscaling:
enabled: false
resources: {}
...others
在上面提供的設定檔中,各個組件使用的資源設定以及 autoscaling 的 HPA 都可以在 Helm Values 中特別設定,為了方便示範這邊沒有特別設定參數,請注意在生產環境中,依照自己的需求調整。
ingester:
kind: StatefulSet
replicas: 1
autoscaling:
enabled: false
resources: {}
在微服務模式中的 Ingester 組件可以指定為 StatefulSet | Deployment 其中一種資源類型,Deployment 代表著無狀態模式,可能會面臨資料遺失的問題,而 StatefulSet 提供 Volume 設定作為持久化儲存,大大降低遺失資料的風險。
queryScheduler:
enabled: true
replicas: 2
affinity: ''
resources: {}
QueryScheduler 如果開啟則代表著原本在 QueryFrontend 中作為給 Querier 消耗的隊列,將會以單獨組件的形式抽離 QueryFrontend。而 replicas 2 的數量為官方推薦最舒適的值。而 affinity 為空值的部分,是為了清空 QueryScheduler 預設只能在一個節點中存在一個 QueryScheduler Pod 的反親和設定,因為我們本機上 Docker Desktop 內的 Kubernetes 叢集正常情況下只會有一個節點 。
gateway:
enabled: true
replicas: 1
autoscaling:
enabled: false
resources: {}
basicAuth:
enabled: true
username: log-user
password: log-password
Gateway 是一個以 Nginx 服務在 Grafana Loki 組件最前方替我們負載均衡所有讀寫請求的守門人,並且提供基本的驗證,可以大大降低我們將 Loki 端點公開的風險。
compactor:
enabled: true
resources: {}
Compactor 可以替我們將多個塊合併並且去重,達到更高的儲存效率,而 Compactor 同時也可以實現相關 retention 策略與刪除塊等操作:
compactor:
working_directory: /var/lib/loki/retention
shared_store: filesystem
compaction_interval: 10m
retention_enabled: true
retention_delete_delay: 2h
retention_delete_worker_count: 150
limits_config:
retention_period: 90d
在 loki.config 內可以調整 Compactor 對 retention 的相關設定。
注意:啟用 retention 設定時需要非常的小心,建議先在非生產環境中經過完整測試。
customParams:
authEnabled: true
loki:
config: |
auth_enabled: {{ .Values.customParams.authEnabled }}
....
當我們開啟了 auth_enabled 參數時,代表著 Grafana Loki 將以多租戶模式運作,所有對 Loki 的寫入和讀取都需要使用帶有 X-Scope-OrgID 的 Header用來區分不同租戶。
loki:
config: |
....
### Custom Configs ###
query_scheduler:
max_outstanding_requests_per_tenant: 32768 # default 100
querier:
max_concurrent: 16 # default 10
....
整個 loki.config 內容將會被我們提供的所有參數組合成最終的 loki config,供每個組件使用,大部分時候我們可以直接使用預設模板,也可以依照自己的需求對每個組件做內部參數調整,就像是下半部分提供的客製設定。
loki:
config: |
....
### Custom Configs ###
query_scheduler:
max_outstanding_requests_per_tenant: 32768 # default 100
querier:
max_concurrent: 16 # default 10
schemaConfig:
configs:
- from: "2023-01-05"
store: tsdb
object_store: filesystem
schema: v11
index:
period: 24h
prefix: loki_index_
storageConfig:
tsdb_shipper:
active_index_directory: /var/loki/tsdb-index
cache_location: /var/loki/tsdb-cache
shared_store: filesystem
filesystem:
directory: /var/loki/chunks
TSDB 時序儲存絕對是 Grafana Loki 2.X 中的一大亮點,它擁有比前一代索引模式 boltdb 更好的機制以及更有效率的查找模式,有幸我們可以在 Loki 2.8 後成為穩定功能後搶先體驗,甚至連 Grafana Loki Distributed Helm Chart 在當前版本都沒有還沒有提供預設參數,但我們基於實踐精神說什麼都要使用上,所以在這裡奉上相關設定。
由於 TSDB 擁有時序資料庫的特性,擅長於更多更小的查詢,所以官方推薦我們在使用 TSDB 可以加大他的併發相關設定。
首先讓我們將 Grafana 端點導出來:
kubectl port-forward service/prometheus-stack-grafana 3000:80 -n prometheus
------
Forwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000
接著進入我們本機中的 localhost:3000 就能看到精美的 Grafana Login 頁面。
在其中我們需要應對我們的設定輸入對應的相關參數:
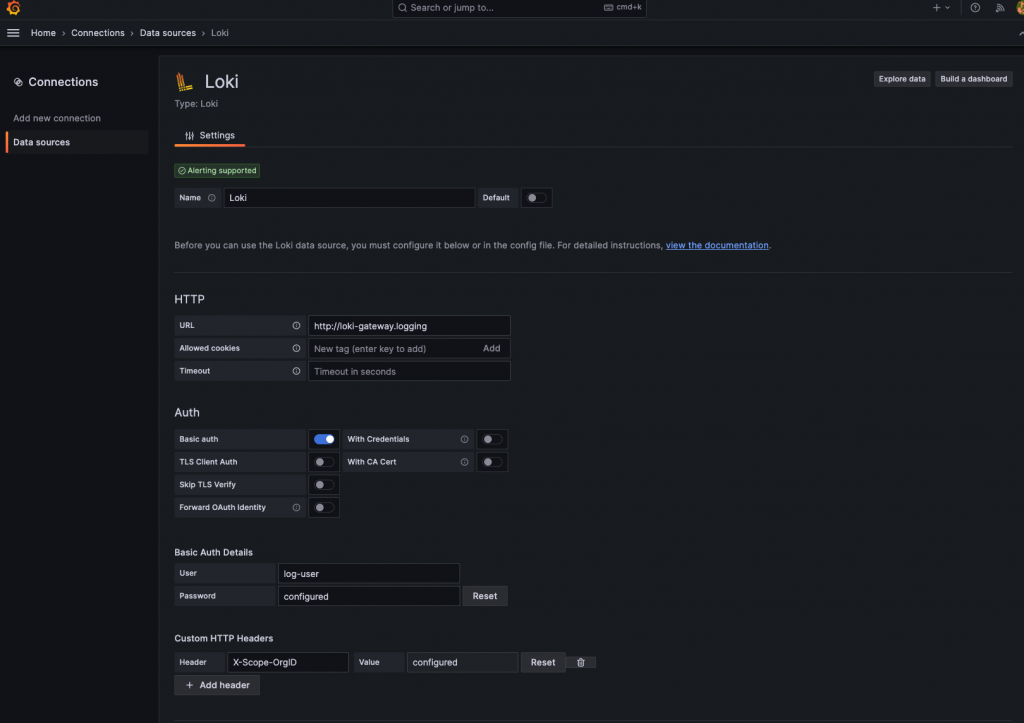
現在,我們可以成功地在 Grafana Loki 中看到所有來自 Kubernete 叢集的日誌了,並且還能看到我們額外設定的 cluster=docker-desktop 標籤,代表 Promtail 也如我們料想中的一樣,通過了 Basic Auth 驗證並且在每筆日誌中附帶指定標籤。
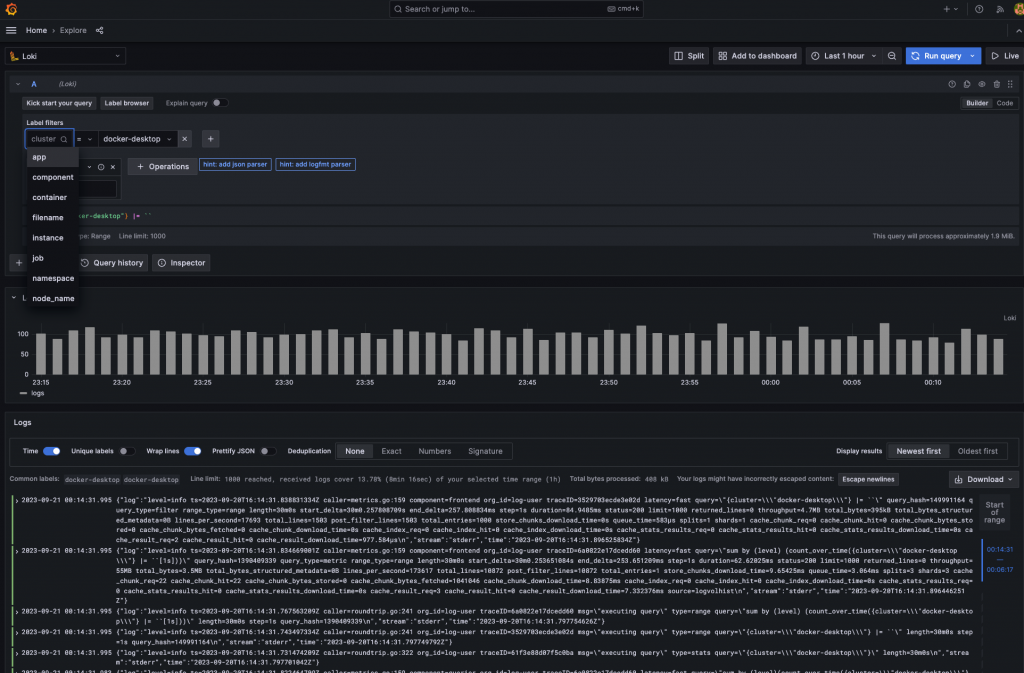
在實戰演練環節,我們成功了安裝 Grafana Loki 並且使用了 Promtail 當作 Log Agent,完成了足以應付生產環境的大部分設定,並且搶先體驗了最新一代的索引解決方案 TSDB,雖然還沒有大規模的資料量,但什麼都用最新的心裡就是很舒坦,最後我們使用了前面章節架設起的 Grafana 成功揭露 Grafana Loki 的神秘面紗。其中每個地方都可以說是細節滿滿,都很適合獨立寫一個章節介紹,不論是 Grafana 與 Loki 的高度整合或是單純比較 boltdb 與 TSDB 帶來的改變,都十分的令人著迷,或許往後的某天反應不錯還能再詳細介紹下去。接下來就讓我們進入效能調校的世界,看看如何打造更強大的 Grafana Loki 吧。
相關程式碼同步收錄在:
https://github.com/MikeHsu0618/grafana-stack-in-kubernetes/tree/main/day23
References
6 easy ways to improve your log dashboards with Grafana and Grafana Loki | Grafana Labs
The only Helm chart you need for Grafana Loki is here | Grafana Labs
Grafana Loki 2.7: TSDB index, Promtail enhancements, and more
Grafana Loki 2.8 release: TSDB, LogQL enhancements, and more

