NLP
NLP的重要性
- 了解知識的重要性
- 知識主要儲存在文字中
- 互相溝通的重要性
- 資訊爆炸時代的必須性
NLP的主要架構
接下來將以「由上而下的階層式架構」來分析NLP面對的語法(Synatactic)與語意(Semantic)的問題,以及其相對應的處理方法,並介紹NLP演進的三大階段,包括:基於法則的NLP、基於傳統機器學習的NLP,以及基於深度學習的NLP。
NLP的階層分析架構
1.語法分析:(Syntactic Analysis):指利用語法的法則去了解句子內,詞與詞之間應該有的正確順序、組合,與其一定程度遵守的文法。例如:在英文中句子順序為主詞、動詞、名詞,不太可能出現主詞、名詞、動詞。
2.語意分析:(Semantic Analysis):指了解一個句子內詞與詞彼此的關係,以及句子所欲表達的意涵。
3.由上而下的階層或架構
- 斷詞(Token):要分析文本共有幾個詞(Words),這是斷詞的議題。
- 停用詞(Stop Words):文本中有哪些詞式重要、值得分析的,哪些是可以忽視的,例如: the、of等等。
- 詞性標註(POS):句子內的詞,其屬性為何(形容詞、動詞、名詞)。
- 詞向量(Word Vectors):分析每個詞自身的特徵為何。
- 句法剖析(Parsing):了解這個句子的結構為何?詞與詞之間的關係為何?哪個是主詞?哪個是受詞?
- 命名實體識別(Named Entity Retrieval, NER):這句子裡有那些專以名詞。
- 分析句子主要的意涵與意圖(Semantic):這就是所謂的文本分類、摘要抽取、意圖分析。
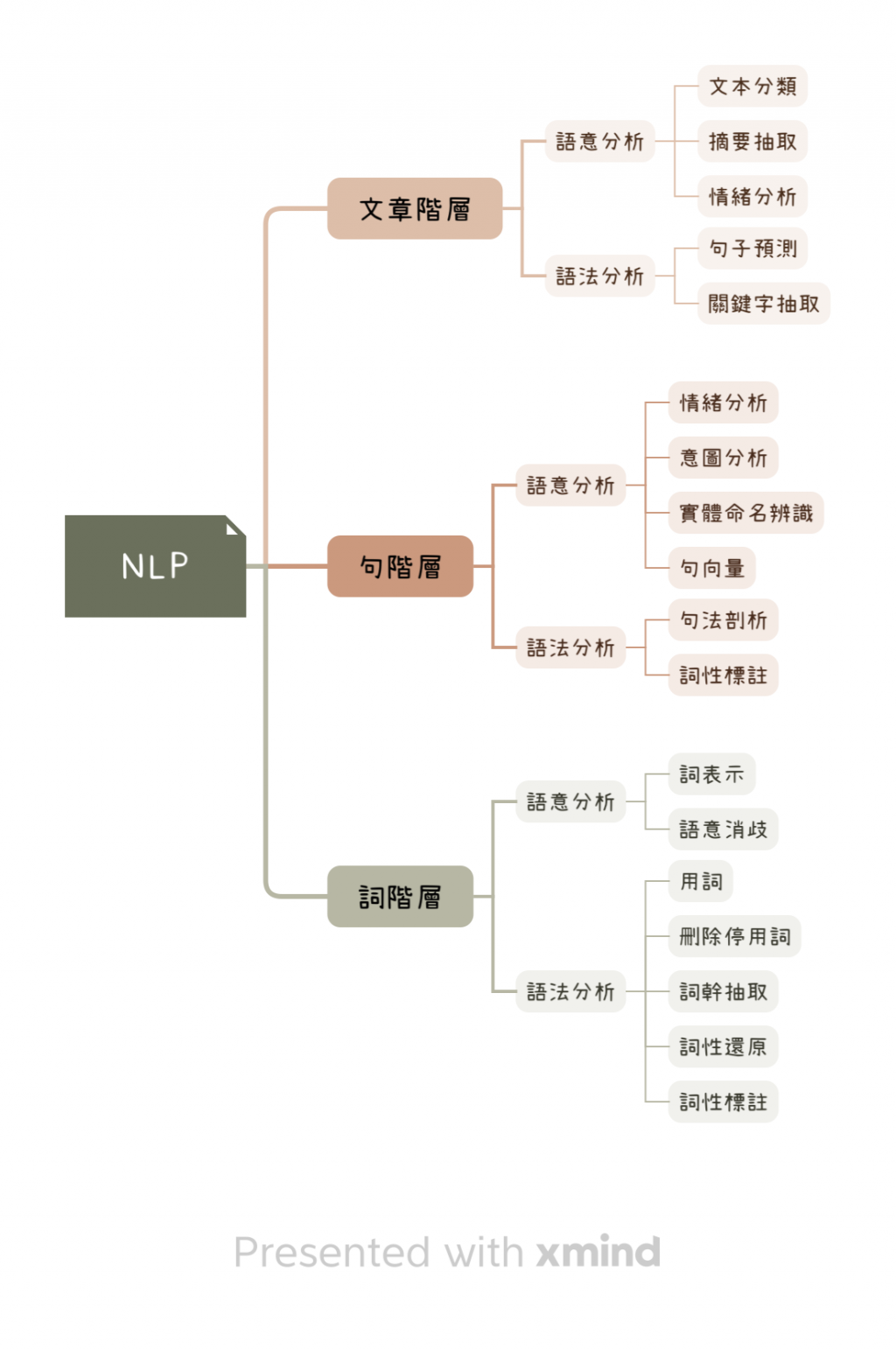
在圖中,除了最上層的文本階層外,其餘字、詞、句子的語法與語意之分析處理,都稱為NLP的預處理階段,指在達成NLP的最終任務之前,對於輸入的數據庫、文本都要先作詞、句分析的預處理,以助於後續任務更快速有效率完成。
NLP開發架構
1.基於法則的NLP(Rule-Based NLP)開發架構
為1980年代專家系統時期的主要方法,NLP的處理要靠if、then、else的法則來處理,例如:在問答系統中的NLP任務中,if Q=台北到台中多遠 them A=164公里。這是一種硬式的法則,必須完全一致才可啟動法則,如果問法與資料庫內的問法不同,則系統會無法回答。而這種架構也只能適用在領域範圍較小、句法簡單、關鍵字少而明確的小型QA系統。
2.基於機器學習方法的NLP開發架構(ML Based NLP)
機器學派與法則學派不同之處有以下幾點
- 利用直觀實用的知識取代法則:例如:實際練習如何描述、如何騎腳踏車來取代了解說話的文法結構,以及分析腳踏車如何用力、平衡、 施力的角度等理性的結構知識。
- 由上而下(Bottom up)取代由上而下(Top Down):機器學習是由下面的實力網上自然瞭解語言的法則,而法則學派則是由上面的法則指導下面的語言產出,必須以大量且完全正確的法則來指導,沒有彈性。
- 由模仿取代理解:機器學派由大量與廖地模仿人類真正說話方式,來取代語言學家由法則的角度來了解、分析語言的結構。
- 特徵工程取代法則:在機器學派,對於語言文字的理解必須先由人類的專家來篩選該文本句有的特徵;然而在深度學習中,機器就可以自行發現重要特徵。
- 不同任務不同的Model:每個不同的任務,各自有不同的特徵工程;每個不同的任務,有不同的演算法。
- 預處理的重視:傳統機器學習方法及演算法的NLP,非常重視文字的預處理,包括詞與詞句階段的所有語法分析工具與語意分析工具,例如:斷詞、句法剖析等等。
3.基於深度學習的NLP開發架構(DL Based NLP)
深度學習開發架構有以下特性
- 特徵工程:基於深度學習的NLP少了人為的特徵工程階段,因為深度學習會自己學習與執行文字特徵的抽取與篩選。
- 資料預處理方面:由於其猶大數據來學習,因此在自我學習中,深度學習的語言模型都已經學會並執行斷詞、停用詞等等,所以不需再執行預處理階段。
- 詞向量方面:深度學習NLP最主要的核心工具就是所謂的詞向量,深度學習利用詞向量來處理所有任務,取代了傳統的法則與機器學習所重視的計算詞出現頻率的特徵工程。但深度學習在NLP上最大的問題便是需要非常大量的訓練資料,所以也需要非常大量的運算立及訓練成本。
4.混合型的NLP開發架構(Mixed NLP Framework)
由於以上學派的Model皆各有優缺點,因此未來的趨勢會是三種開發架構之結合的混合型NLP模式,來提升整體效率。
參考資料
人工智慧-概念應用與管理 林東清 著


 iThome鐵人賽
iThome鐵人賽