在2022年,Grafana Tempo 正式推出了其 v1.0 版本。儘管與 Grafana Loki 相比,它相對年輕,但 Tempo 不僅吸取了 Prometheus 和 Grafana Loki 的成熟架構和經驗,更在這穩固的基礎上不斷創新與進步。至今,Grafana 團隊尚未給出明確的最佳預設值建議,官方對此解釋表示:「由於Grafana Tempo 的效能日益優化,定下一具體數值可能很快就會變得不再適用。」
然而,在進行任何優化或調校之前,我們必須深入了解其特性與運作方式。只有充分理解,我們才能在生產環境中完全發揮 Grafana Tempo 的強大潛力。這也是我們一開始選擇採用最細緻的微服務模式的原因。

在 Grafana Tempo 中因為架構或生態體系相似,我們也會遇到許多在 Grafana Loki 中遇到的問題,但又不完全一樣,就讓我們再次了解如何慢慢化解這些問題。
當我們在 Grafana 介面中處理大範圍查詢時,大多數的超時問題都來自請求發送之後經過的組件或服務中,仔細探討後,我們可以注意到這些服務都如以下這些種類:
在實際生產環境中,每個地方的架構有簡單有複雜情況不一,所以在處理這類問題時,我們需要依照實際情況去每道處理請求的關卡中實際調整,才能達到根治問題的效果。
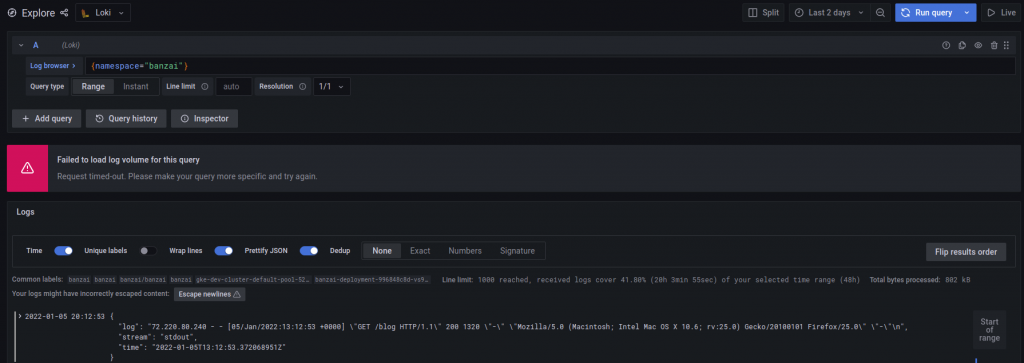
在我們可視化介面 Grafana 的第一道關卡就是一個典型的網頁服務,在此 Grafana 對 data source 的預設超時設定為 30 秒,所以我們很容易得到 Timeout 的錯誤,以下我們有兩種方式調整這項 dataproxy 的超時時間。
# grafana
grafana.ini:
...
dataproxy:
logging: true
timeout: 600 # default 30s
...
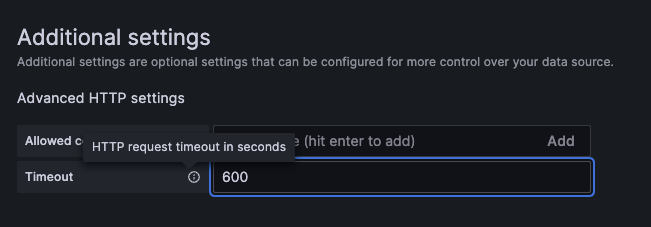
如果有再額外使用 nginx-ingress controller 作為進入 Tempo 第一道關卡的同學,很容易忽略的一個問題,就是 nginx-ingress 本身也是一個代理服務器,也有其超時設定,所以有可能需要依實際情況在 Ingress 設定檔中的 annotations 調整相關設定。
...
annotations:
nginx.ingress.kubernetes.io/proxy-connect-timeout: "600"
nginx.ingress.kubernetes.io/proxy-read-timeout: "600"
nginx.ingress.kubernetes.io/proxy-send-timeout: "600"
...
別忘了我們使用 loki-gateway 組件本身的也是個 nginx 服務,也需要對其做出調整。
# values.yaml(helm)
gateway:
nginxConfig:
file: |
//...
http {
//...
proxy_read_timeout 600s;
//...
}
}
在 Tempo 設定中可以針對每個組件的 HTTP 端口調整超時設定。
# tempo-config
server:
http_server_read_timeout: 600s # dafault 30s
http_server_write_timeout: 600s # dafault 30s
http_server_idle_timeout: 600s # dafault 2m
在 Tempo 查詢的過程中,會不斷的傳遞資料,最終才能組合出我們預期的完整結果出來,而其中的溝通過程涉及大量資料傳遞。Tempo 預設為我們設定每個訊息最大不能超過 4 Mb 的限制來保護記憶體過度使用,並且發出對應錯誤。
但有時我們仍然有儲存及查詢龐大使用需求,所以我們可以調整一下參數:
# tempo-config
server:
grpc_server_max_recv_msg_size: 104857600 # default 4 Mb
grpc_server_max_send_msg_size: 104857600 # default 4 Mb
# values.yaml(helm)
querier:
max_concurrent_queries: 20
增加查詢量 max_concurrent_queries 是提升查詢器吞吐量的好方法,但隨之帶來的是 OOM 或資源飽和的風險提高。
# values.yaml(helm)
query_frontend:
max_outstanding_per_tenant: 2000 # default 2000
max_batch_size: 3 # default 5
search:
concurrent_jobs: 2000 # default 1000
target_bytes_per_job: 50_000_000 # default 104857600 byte
Tempo 中的緩存主要用於透過儲存每次查詢時存取的所有後端區塊的布隆過濾器來提高查詢效能。
# values.yaml(helm)
memcached:
enabled: true
replicas: 1
resources: {}
memcachedExporter:
enabled: true
resources: {}
# tempo-config
storage:
cache_min_compaction_level: 2 # dafault 0 disabla
cache_max_block_age: 48h # default '' disable
這兩個參數都是為了提高查詢效率,讓系統能更聰明地決定哪些bloom filter最有價值並應該被放入緩存中。
# values.yaml(helm)
ingester:
config:
replication_factor: 3
trace_idle_period: null
flush_check_period: null
max_block_bytes: null
max_block_duration: null
complete_block_timeout: null
flush_all_on_shutdown: false
以下是影響 Ingester 效能的參數及其簡單的條列介紹:
經網友實測調整 max_block_bytes 的實測表示出,較小的數值可以換取更低的 Ingester 資源使用率,但不確定是否影響到查詢效能。
| (Ingester) CPU usage | (Ingester) Memory usage | (Compactor) CPU usage | (Compactor) Memory usage | |
|---|---|---|---|---|
| Case 1) max_block_bytes: 1gb | 0.3 ~ 1.8 | 4gb ~ 8.5gb | 0 ~ 0.9 | 0.1gb ~ 2.5gb |
| Case 2) max_block_bytes: 512mb | 0.3 ~ 1.6 | 3gb ~ 5.5gb | 0 ~ 0.9 | 0.3gb ~ 4gb |
| Case 3) max_block_bytes: 256mb | 0.5 ~ 1.0 | 2gb ~ 3.5gb | 0 ~ 0.9 | 0.3gb ~ 3.5gb |
| Case 4) max_block_bytes: 128mb | 0.5 ~ 1.0 | 2gb ~ 3gb | 0 ~ 0.9 | 0.1gb ~ 4gb |
Grafana Tempo 寫入是以 otlp 協議架構設計,擁有最佳的效能表現,所以在使用 Jaeger 等其他追蹤協議的話,轉移到 otlp 追蹤協議也能帶來效能上的提升。
# values.yaml(helm)
traces:
otlp:
http:
enabled: true
grpc:
enabled: true
# values.yaml(helm)
distributor:
config:
log_received_spans:
enabled: false
include_all_attributes: false
filter_by_status_error: false
開啟 Distributor 組件的 log_received_spans 將打印出所收到的相關追蹤信號,可以幫助我們對 Ingester 組件除錯,用這些日誌來驗證資料錯誤。
在存儲上,我們可以對於存儲策略、保留時間、以及對資料做出最適合自己的調整。
使用對象存儲是我們在生產環境首要選擇,也是 Grafana Tempo 比其他分佈式追蹤解決方案比較中,成本拉開差距的關鍵因素,也是最大賣點。
# values.yaml(helm)
storage:
trace:
backend: gcs
gcs:
bucket_name: sit-tempo-tracing-bucket
在上面的設定中我們需要先在 storage_config 設定 gcs 數值,並且在 object_store 中指定使用 gcs。
注意:我們需要在 Kubernetes 叢集對會直接讀寫 GCS Bucket 的組件,例如:Ingester、Querier、Compactor 等組件,設定對應足夠權限的 Service Account。
# values.yaml(helm)
compactor:
config:
compaction:
block_retention: 48h
compacted_block_retention: 1h
compaction_window: 1h
max_block_bytes: 107374182400
我們也可以使用 GCS 原生的 Lifecycle 來實現資料保留的操作:
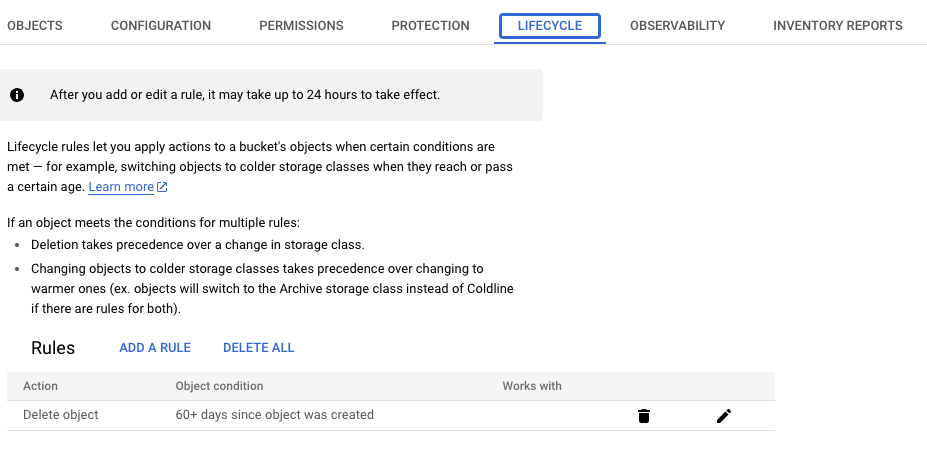
分佈式追蹤是一種監控和排錯技術,用於捕獲和分析分佈式系統中的交易或請求。然而,當系統的流量非常大時,記錄每一個追蹤事件可能導致大量的資料,增加存儲和處理的成本。這裡就是取樣率、取樣策略的概念發揮作用。
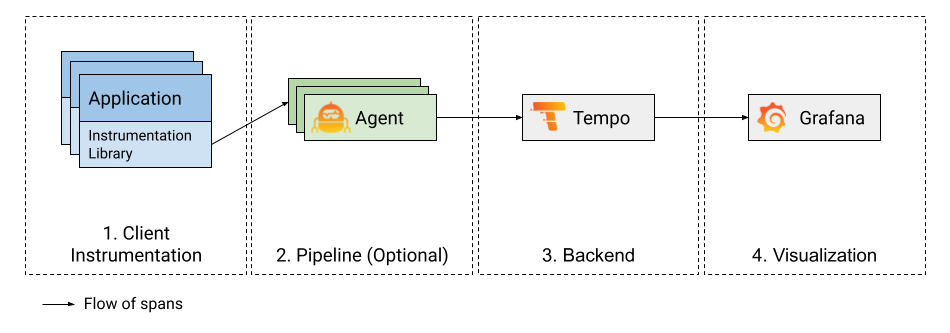
而這些都可以透過在追蹤管道中的解決掉,控制取樣的元件:
上圖使用 Grafana Agent 作為追蹤收集器的概念,其他選擇也可以為 otel collector、jaeger agent 等。
取樣率是一種策略,確定在分佈式追蹤中應該追踪和存儲哪些交易或請求。舉例來說,如果取樣率設定為1%(0.01),則只有每100個請求中的1個請求會被追蹤和存儲。這有助於從根本上減少存儲需求,同時仍能提供有代表性的追蹤數據來分析系統的行為。
簡單來說就是透過一層 grafana agent 或是 otel collector ,採取某種策略去過濾掉大部分不必要的 tracing 資料。
而一些流行的取樣政策是:
事實上,還有許多其他有用的取樣策略:
以下為 Grafana Agent 簡單地過濾出 ERROR 狀態的追蹤信號:
traces:
configs:
- name: default
...
tail_sampling:
policies:
- type: latency
latency:
threshold_ms: 100
- type: status_code
status_code:
status_codes:
- "ERROR"
基數是一個標籤的值的總數。在下圖中,標籤的status_code基數為 5,標籤environment的基數為 2,追蹤信號的總體基數server_responses為 10。
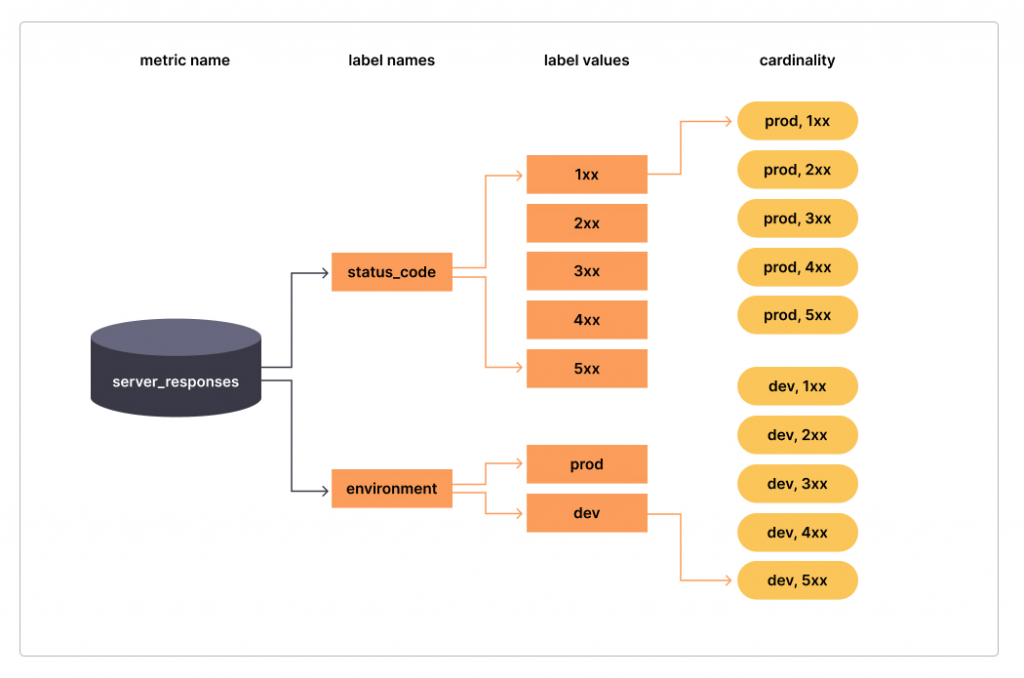
基數的概念在可觀測性世界中非常重要,可以直接影響資源的使用負載,如果使用不當導致發送的追蹤信號數量呈指數級增加,那我們的帳單也會增加。因此,控制基數也可以帶來一些實際的成本效益。
Tempo 使用 Cortex 雜湊環實現一致性,預設情況下,環在所有 Tempo 元件之間進行同步。
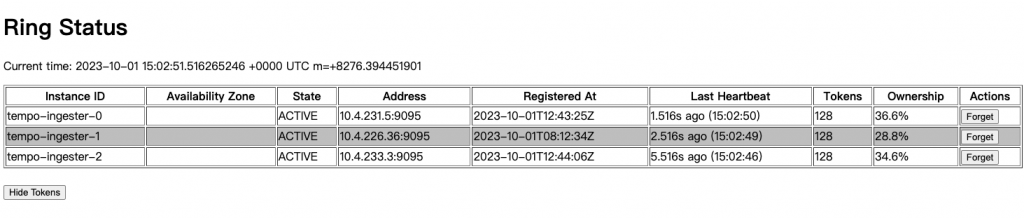
在大部分的情況下,雜湊環會自動維護其叢集的健康,但有時我們還是會遇到如下需要手動的處理的錯誤:
expanding series: too many unhealthy instances in the ring
此時我們則需要進入各個元件中 /{component}/ring 路徑去手動 Forget 不健康的節點,使雜湊環自動恢復健康狀態。
在本章中,我們將從讀寫、存儲,以及維運心法的角度,深入探討 Grafana Tempo。這裡匯集了我在實際運環境下的慘痛經驗以及所踩過的坑,而某些特定內容由於打算單獨介紹,故在此並未詳盡展開。值得注意的是,Grafana Tempo 仍在以驚人的速度不斷進化,我們必須持續學習以追趕其發展腳步。相信經由這幾個簡短章節的學習,我們能夠具備應對大多數生產環境的能力。接下來,我們將踏入高擴展性監控指標的世界,一同探索 Grafana 團隊為我們精心打造的解決方案 Grafana Mimir。
相關程式碼同步收錄在:
https://github.com/MikeHsu0618/grafana-stack-in-kubernetes/tree/main/day27
References
Tune the consistent hash rings | Grafana Tempo documentation
What are cardinality spikes and why do they matter? | Grafana Labs
Too many jobs in the queue | Grafana Tempo documentation
Response larger than the max | Grafana Tempo documentation
使用Grafana Tempo和Grafana Agent进行跟踪采样的介绍 - 掘金
An introduction to trace sampling with Grafana Tempo and Grafana Agent | Grafana Labs
Improve performance with caching | Grafana Tempo documentation

