在建構分佈式追蹤系統的過程中,我們會遇到許多相較於日誌系統更為複雜的挑戰。這主要是因為日誌資料通常以文本格式儲存,並不需要遵循特定的格式或協議。然而,當前主流的追蹤信號皆由開源社群共同定義,形成了特定的格式和協議。由於分佈式追蹤的歷史發展因素,市面上存在著多種協議和選擇。
在開始使用 Grafana Tempo 之前,使用者需要具備一定的基礎知識。這方面的學習可以從 Opentelemetry 的官方文件入手,它提供了豐富的相關資訊和指南。而本章節將提供現成的追蹤信號範例,使我們能夠專注於探索如何在實務中充分利用 Grafana Tempo。
透過這種方式,我們不僅能夠更深入了解分佈式追蹤的原理和實踐,也能夠有效地掌握 Grafana Tempo 的運用,為我們的系統監控和效能優化奠定堅實基礎。

還記得我們在先前的 Grafana Loki 中,介紹了不同顆粒大小的部署模式。 而 Grafana Tempo 完全可以遵循同樣的概念來理解,也擁有不一種的部署模式,供我們依據實際需求來選擇,現在我們將要一起來看看 Grafana 為我們端出什麼好菜吧。
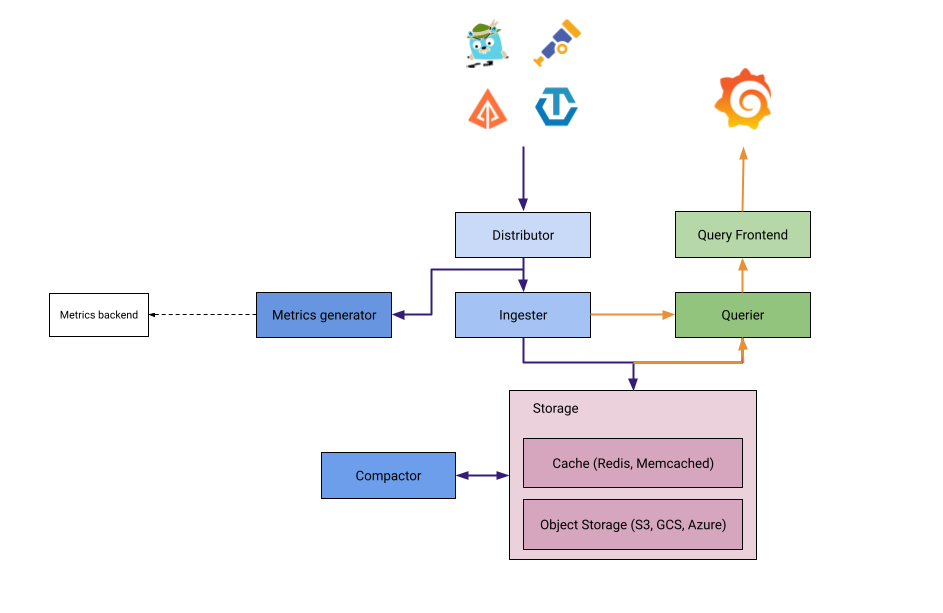
Grafana Tempo 的部署模式概念上可以分為單體和微服務模式。
單體模式是 Grafana Tempo 中最簡單的操作設定,開箱及用,對第一次體驗的人非常友善。單體模式可以讓我們在單一進程、一個二進制檔、一個 Docker Image 中,運作起包含所有微服務組件。
單體縮放模式可以理解為以單體模式為單位的水平擴展版本,因為所有組件都在同一個進程中運行,關鍵在於將進程設置 -target scalable-single-binary,來實現水平擴展。
這種模式為單體模式提供了更多的彈性,可以不需要理解微服務部署的複雜配置,就可以實現水平擴展。
微服務模式下的 Grafana Tempo 有有最大的彈性以及最細的控制顆粒程度,這是目前 Grafana Labs 對 Tempo 推薦的首選模式,不同於 Loki 推薦的讀寫模式。雖然使用微服務模式最為複雜,但同時也能達到最佳的調教效率。
每個組件部署關聯配置必須指定 target 為特定組件,像是 -target=querier,且必須為滿足 Tempo 最低所需的每種組件才能順利執行。
helm search repo tempo | grep grafana/tempo
------
NAME CHART VERSION APP VERSION DESCRIPTION
grafana/tempo 1.6.1 2.2.2 Grafana Tempo Single Binary Mode
grafana/tempo-distributed 1.6.5 2.2.2 Grafana Tempo in MicroService mode
...
Grafana Tempo 提供了我們上面介紹提到的單體模式以及微服務模式兩種選擇,在經過我們的介紹以及實戰演練後,我們會對於每個元件的設定越來越熟悉,也可以一一拆解並了解其中的差異,選擇出最適合自己的專屬 Helm Chart:
Tempo Operator 是在 Kubernetes 和 OpenShift 叢集上,以各種 CRD 配置、安裝、升級和運營 Grafana Tempo 的解決方案。它不僅支持資源限制的靈活設定,確保各個組件得到適切的資源分配,而且還具備了 OpenID Control(OIDC)和基於角色的訪問控制(RBAC),提供了堅固的安全防護。此外,它的多租戶功能允許多個使用者向同一 Tempo 叢集發送跟踪,而 mTLS 則確保了組件間通信的安全。Tempo Operator 同時也讓您可以在 Jaeger UI 中清晰地視覺化跟踪,並通過 Ingress 或 OpenShift Route 進行暴露,加強了系統的可觀察性。此外,它與 Prometheus ServiceMonitors 的整合,使得操作數據的遙測監控變得觸手可及,使我們擁有對其的監控和管理能力。
注意:Tempo Operator 目前只提供微服務模式安裝。
在接下來的實戰中,我們將利用先前建立好的 Kube-Prometheus-Stack 及其相關設定來當作 Grafana Tempo 的可視化介面,其中詳細安裝過程可以回頭複習一下「Kube-Prometheus-Stack 實戰系列」。
不同的是我們將解開 Prometheus 進階功能的封印:
# values.yaml
....
prometheus:
enabled: true
prometheusSpec:
enableFeatures:
- exemplar-storage
enableRemoteWriteReceiver: true
我們只將原先的設定檔 enableRemoteWriteReceiver 參數調成 true,並且將 enbleFeatures 中添加 exemplar-storage 存儲功能,即可馬上執行 helm 更新。
注意:如果沒有開啟 exemplar-storage 但遠程寫入 Exemplar 時,在 Prometheus 中只能看到監控指標,而不是監控指標加追蹤訊息的 Exemplar。
helm upgrade --install prometheus-stack prometheus-community/kube-prometheus-stack --values=values.yaml -n prometheus --create-namespace
現在我們要使用 values.yaml 兩個參數檔,進行對 Grafana Tempo 的設定。
# values.yaml
fullnameOverride: 'tempo'
reportingEnabled: false
multitenancyEnabled: false
global_overrides:
metrics_generator_processors:
- service-graphs
- span-metrics
ingester:
replicas: 3
autoscaling:
enabled: false
resources: {}
persistence:
enabled: true
config:
replication_factor: 3
metricsGenerator:
enabled: true
replicas: 1
resources: {}
config:
storage:
remote_write:
- send_exemplars: true
url: http://prometheus-stack-prometheus.prometheus:9090/api/v1/write
distributor:
replicas: 1
autoscaling:
enabled: false
resources: {}
compactor:
replicas: 1
resources: {}
config:
compaction:
block_retention: 48h
querier:
replicas: 1
autoscaling:
enabled: false
resources: {}
queryFrontend:
replicas: 1
autoscaling:
enabled: false
resources: {}
traces:
jaeger:
grpc:
enabled: true
thriftBinary:
enabled: true
thriftCompact:
enabled: true
thriftHttp:
enabled: true
zipkin:
enabled: true
otlp:
http:
enabled: true
grpc:
enabled: true
opencensus:
enabled: true
kafka: {}
storage:
trace:
backend: local
memcached:
enabled: true
replicas: 1
resources: {}
memcachedExporter:
enabled: true
resources: {}
metaMonitoring:
serviceMonitor:
enabled: true
grafanaAgent:
enabled: false
installOperator: false
logs:
remote:
url: ''
metrics:
remote:
url: ''
prometheusRule:
enabled: true
gateway:
enabled: true
replicas: 1
autoscaling:
enabled: false
resources: {}
values.yaml 主要針對所有組件在 Kubernetes 叢集中的相關資源設定。
helm upgrade --install tempo grafana/tempo-distributed -n tracing -f values.yaml --create-namespace
---
Release "tempo" does not exist. Installing it now.
NAME: tempo
LAST DEPLOYED: Thu Sep 28 00:01:14 2023
NAMESPACE: tracing
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
***********************************************************************
Welcome to Grafana Tempo
Chart version: 1.6.5
Tempo version: 2.2.2
***********************************************************************
Installed components:
* ingester
* distributor
* querier
* query-frontend
* compactor
* memcached
* gateway
接下來我們就可以在 Kubernetes 叢集中看到熟悉各種 Tempo 組件:
kubectl get pods -n tracing
---
NAME READY STATUS RESTARTS AGE
tempo-compactor-86c45959f5-wrxkz 1/1 Running 1 39h
tempo-distributor-c57c5d9cb-7jxhf 1/1 Running 1 39h
tempo-gateway-5b9bbd9694-rzzkq 1/1 Running 1 39h
tempo-ingester-0 1/1 Running 1 39h
tempo-ingester-1 1/1 Running 1 39h
tempo-memcached-0 2/2 Running 2 39h
tempo-metrics-generator-57d596755d-kzg22 1/1 Running 1 39h
tempo-querier-b75fc4c4c-nv6vv 1/1 Running 1 39h
tempo-query-frontend-7d7547b67f-89fzc 1/1 Running 1 39h
現在我們已經成功運作起來完整的微服務模式 Grafana Tempo,但如果我們只空有分佈式追蹤服務卻沒有人來任何追蹤信號是不行的,所以我們這裡將使用一個 Grafana 團隊提供給我們 k6 範例,作為發送追蹤信號的角色。
# xk6-client-tracing.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: xk6-tracing
namespace: tracing
spec:
minReadySeconds: 10
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: xk6-tracing
name: xk6-tracing
template:
metadata:
labels:
app: xk6-tracing
name: xk6-tracing
spec:
containers:
- env:
- name: ENDPOINT
value: tempo-distributor.tracing:4317
image: ghcr.io/grafana/xk6-client-tracing:v0.0.2
imagePullPolicy: IfNotPresent
name: xk6-tracing
接下來在我們執行安裝後,這個範例將會開始傳送以下模板產生出來的追蹤資料。
執行 K6 安裝:
kubectl apply -f xk6-client-tracing.yaml -n tracing
---
deployment.apps/xk6-tracing created
追蹤信號模板:
const traceTemplates = [
{
defaults: traceDefaults,
spans: [
{service: "shop-backend", name: "list-articles", duration: {min: 200, max: 900}},
{service: "shop-backend", name: "authenticate", duration: {min: 50, max: 100}},
{service: "auth-service", name: "authenticate"},
{service: "shop-backend", name: "fetch-articles", parentIdx: 0},
{service: "article-service", name: "list-articles"},
{service: "article-service", name: "select-articles", attributeSemantics: tracing.SEMANTICS_DB},
{service: "postgres", name: "query-articles", attributeSemantics: tracing.SEMANTICS_DB, randomAttributes: {count: 5}},
]
},
{
defaults: {
attributeSemantics: tracing.SEMANTICS_HTTP,
},
spans: [
{service: "shop-backend", name: "article-to-cart", duration: {min: 400, max: 1200}},
{service: "shop-backend", name: "authenticate", duration: {min: 70, max: 200}},
{service: "auth-service", name: "authenticate"},
{service: "shop-backend", name: "get-article", parentIdx: 0},
{service: "article-service", name: "get-article"},
{service: "article-service", name: "select-articles", attributeSemantics: tracing.SEMANTICS_DB},
{service: "postgres", name: "query-articles", attributeSemantics: tracing.SEMANTICS_DB, randomAttributes: {count: 2}},
{service: "shop-backend", name: "place-articles", parentIdx: 0},
{service: "cart-service", name: "place-articles", attributes: {"article.count": 1, "http.status_code": 201}},
{service: "cart-service", name: "persist-cart"}
]
},
{
defaults: traceDefaults,
spans: [
{service: "shop-backend", attributes: {"http.status_code": 403}},
{service: "shop-backend", name: "authenticate"},
{service: "auth-service", name: "authenticate", attributes: {"http.status_code": 403}},
]
},
]
以下將詳細拆解我們使用到的參數設定檔,幫助大家了解實際設定。
metaMonitoring:
serviceMonitor:
enabled: true
prometheusRule:
enabled: true
幫助我們預先建立 Grafana Tempo 的 serviceMonitor 以及 prometheusRule,提供開箱及用的 Prometheus 指標設定和告警。
reportingEnabled: false
Grafana Labs 在 Tempo 中幫我們預先開啟了,回傳相關資料到官方,這裡我們可以選擇將這個貼心的功能關閉。
multitenancyEnabled: false
當我們開啟了 auth_enabled 參數時,代表著 Grafana Loki 將以多租戶模式運作,所有對 Loki 的寫入和讀取都需要使用帶有 X-Scope-OrgID 的 Header用來區分不同租戶。
注意:這邊為了 K6 範例發送追蹤信號方便,而不開啟。
querier:
replicas: 1
autoscaling:
enabled: false
resources: {}
queryFrontend:
replicas: 1
autoscaling:
enabled: false
resources: {}
...others
在上面提供的設定檔中,各個組件使用的資源設定以及 autoscaling 的 HPA 都可以在 Helm Values 中特別設定,為了方便示範這邊沒有特別設定參數,請注意在生產環境中,依照自己的需求調整。
ingester:
replicas: 3
autoscaling:
enabled: false
resources: {}
persistence:
enabled: true
config:
replication_factor: 3
在 Ingester 組件中,我們開啟了 persistence 為 true,代表著 Tempo 將會替 Ingester 這個 Statefulset 資源掛上 PVC 持久卷,確保資料的持久性。此外,我們使用預設 replication_factor 為 3 的設定,可以利用資料冗餘的方式,降低單一節點資料遺失導致資料不一致的風險,同時我們必須注意 replicas 不得低於複製因子的最大容忍失敗數「2」,而如果開啟 autoscaling 功能時,也須確保 minReplicas 大於等於最大容忍失敗數。
最大容忍節點數量: maxFailure = floor(replication_factor / 2) + 1
gateway:
enabled: true
replicas: 1
autoscaling:
enabled: false
resources: {}
Gateway 是一個以 Nginx 服務在 Grafana Tempo 組件最前方替我們負載均衡所有讀寫請求的守門人,並且提供基本的驗證,相關設定都在此處調整,可以大大降低我們將 Tempo 端點公開的風險。
compactor:
replicas: 1
resources: {}
config:
compaction:
block_retention: 48h
Compactor 可以替我們將多個塊合併並且去重,達到更高的儲存效率,而 Compactor 同時也可以實現相關 retention 策略與刪除塊等操作。在此我們使用預設的保留資料 48 小時設定。
global_overrides:
metrics_generator_processors:
- service-graphs
- span-metrics
metricsGenerator:
enabled: true
replicas: 1
resources: {}
config:
storage:
remote_write:
- send_exemplars: true
url: http://prometheus-stack-prometheus.prometheus:9090/api/v1/write
關於 MetricsGenerator 的設定相當重要,官方並沒有太多範例或者文件敘述如何完整的設定其傳遞 Processor 和 Exemplars 這兩個強大功能。
除了開啟 MetricsGenerator 組件,我們需要注意到的點如下:
memcached:
enabled: true
replicas: 1
resources: {}
memcachedExporter:
enabled: true
resources: {}
這裡我們可以視需求開啟 MemCached 組件,增加查詢效率,並且 Tempo 也很貼心地替我們準備好 MemCached Exporter 提供我們監控指標。
metaMonitoring:
serviceMonitor:
enabled: true
grafanaAgent:
enabled: false
installOperator: false
logs:
remote:
url: ''
metrics:
remote:
url: ''
在 MetaMonitoring 設定中的 GrafanaAgent 選項中,Tempo 提供我們快速地以 GrafanaAgent Operator 建立出傳遞 Tempo 本身日誌及監控指標的 Grafana Agent,而 installOperator 則表示是否需要安裝 GrafanaAgent Operator(如果本來沒有安裝的話)。
注意:installOperator 安裝的部分,只有在第一次安裝 Grafana Tempo 時會生效。
traces:
jaeger:
grpc:
enabled: true
thriftBinary:
enabled: true
thriftCompact:
enabled: true
thriftHttp:
enabled: true
zipkin:
enabled: true
otlp:
http:
enabled: true
grpc:
enabled: true
opencensus:
enabled: true
kafka: {}
在 Traces 設定區塊中,指定著 Distributer 組件將要開啟哪些追蹤服務的協議端口,以及相關端口的客製設定,基本上 Tempo 涵蓋了所有能追蹤協議,我們只要依照需求來選取即可。
storage:
trace:
backend: local
在 Storage 區塊中,我們可以指定所有追蹤數據的儲存方式,目前支持使用本地儲存以及各大雲端平台的物件儲存服務,例如 GCS、S3、ABS(Azure Blob Storage)。此外 Tempo 也提供我們使用 Minio 來實現 S3 介面,當作一種以本地儲存使用物件儲存後端的使用方式。
首先讓我們將 Grafana 端點導出來:
kubectl port-forward service/prometheus-stack-grafana 3000:80 -n prometheus
------
Forwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000
接著進入我們本機中的 localhost:3000 就能看到精美的 Grafana Login 頁面。
現在我們就在 Data Sources 中將我們的 tempo-gateway 或 tempo-query-frontend 查詢組件的端點新增到 Grafana 上。
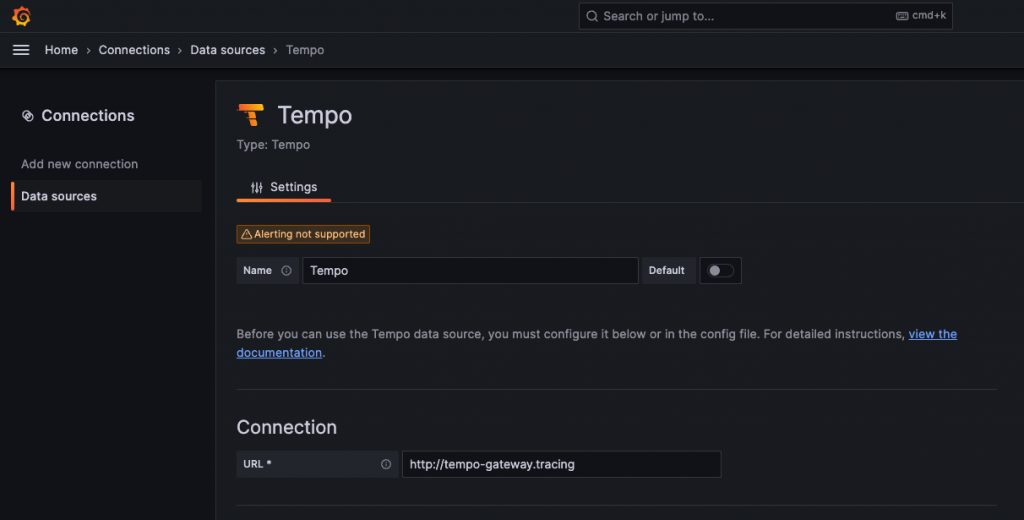
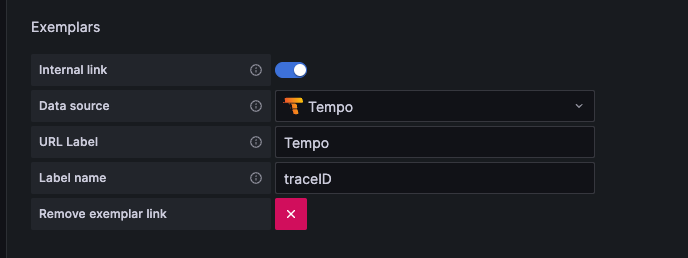
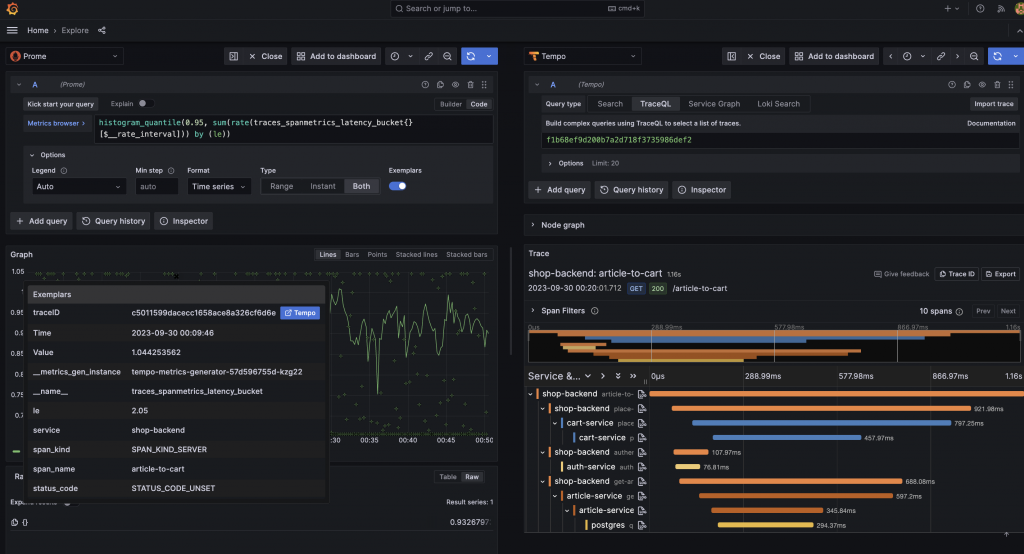
在Data Sources 的 Prometheus 需要額外的設定,才能串接實現 Exemplars 無縫跳轉到 Tempo 的功能。
現在,我們可以成功地在 Grafana Tempo 中看到所有來自 Kubernete 叢集發送的追蹤指標了,並且還能看到每個不同的微服務彼此串連起來的跨度。
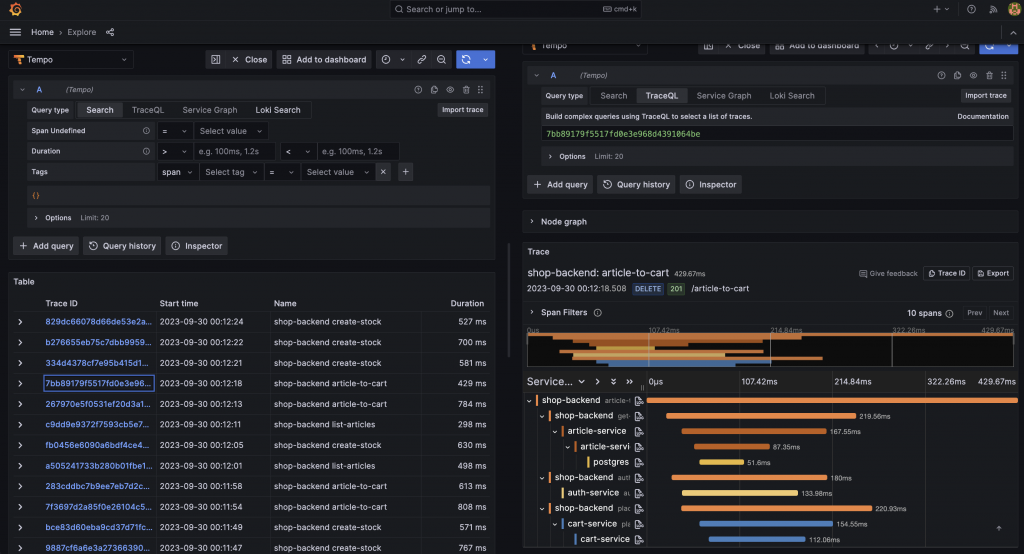
相信 Grafana Tempo 提供的使用體驗不在話下。
點開 Node Graph 摺疊面板後,我們可以清楚地看到整條分佈式追蹤的完整路程,並且可以對於每個跨度的使用情況一目瞭然,例如 Http code、請求時間。
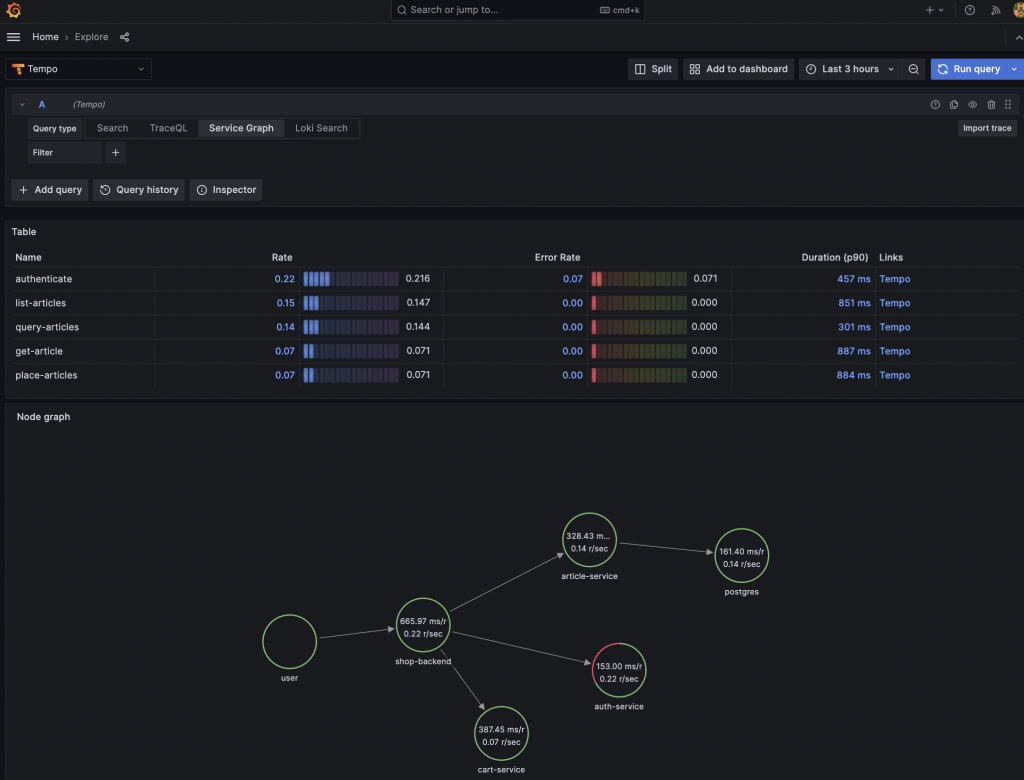
服務圖可以幫助我們了解分散式系統的結構,以及其元件之間的連接和依賴關係:
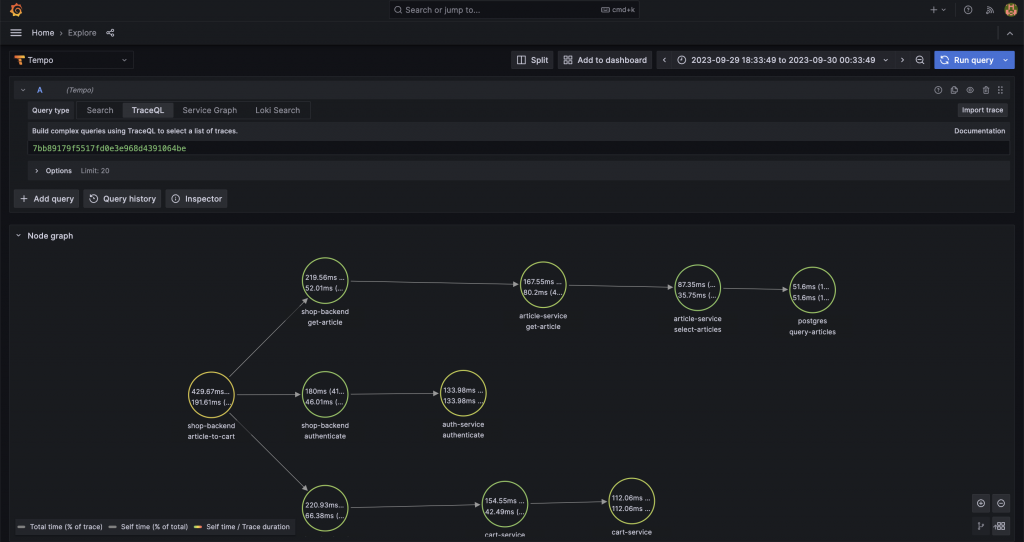
多虧了我們在 MetricsGenerator 組件的複雜設定,它將幫助我們將原有的追蹤信號,額外加工成更有價值的數據,我們可以:
再經過我們對 MetricsGenerator 組件以及 Prometheus 的相關設定後,現在 Exemplar 已經可以被順利儲存,並以小亮點的方式出現在 Prometheus 監控指標上,靠近時即可出現當下的監控指標所關聯到的追蹤數據,並且實現無縫跳轉到 Tempo 的操作。
在本章節,我們深入探討並實戰演練了 Grafana Tempo 的使用方法,且詳細剖析了每個設定參數背後所隱含的涵義。藉由一系列的測試資料,我們得以親身體會到,在生產環境中,微服務間是如何協同運作的。進一步地,我們還透過 Grafana 的直觀可視化介面,實際操作並配置了 Grafana Tempo 的相關連接設定,親身體驗了它的強大功能,以及與 Prometheus 的無縫整合和互動。然而,正如我們之前所提,Grafana 的可觀測性宇宙最獨特且厲害的地方,莫過於不同可觀測性維度間的流暢跳轉。至此,我們所展示與體驗的,還遠未能充分展現 Grafana 的細節。由於篇幅所限,可能會特地寫一篇,深入探討與講解這一方面的細節與操作。對於有興趣深入了解的同學們,請務必敲碗讓我知道你們的期待,也衷心感謝每一位能堅持到這裡的人。
相關程式碼同步收錄在:
https://github.com/MikeHsu0618/grafana-stack-in-kubernetes/tree/main/day26
References
Plan your Tempo deployment | Grafana Tempo documentation

