大家好,這裡是Caco的不嚴謹Web Worker效能測試,繼上次的Loka Veterra後,我為粒子加入了簡單的物理引擎,每個粒子都會被中心點的重力所吸引。
隨著演算法越趨複雜,掉禎的情況越趨明顯,於是,我希望透過在背景進行非同步的運算,來提升純前端的演算能力,每新增一個worker,理論上效率就會加倍,就算不是100%,至少也有80%對吧?就讓我們來實測看看吧。
不負責任聲明:小弟Caco第一次接觸Web Worker,因此不過多著墨技術名詞以免誤人子弟
如圖所示,左邊是在主線程中(main.js)運算的粒子系統,右邊則是在獨立線程中(worker.js)運算,下方我做了一個簡易的UI,可以知道當前畫面的禎數(左右各有2000個粒子,運算量約為4000個繪圖請求、4000次座標計算的迴圈)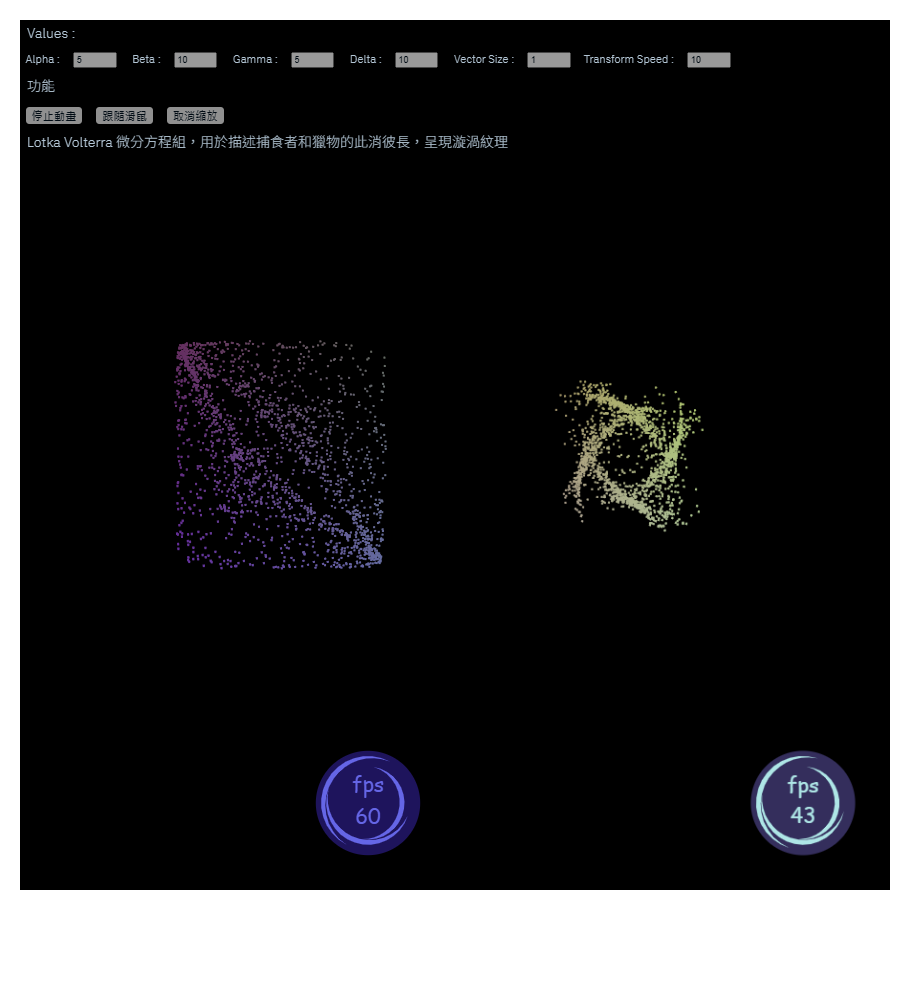
如果你心裡有這個想法,別緊張!基本上,我就是把原本的粒子系統、渲染系統的代碼複製了一份,貼到worker.js中,為什麼這麼做呢?因為方便,與其直奔渲染+演算協作模式,不如先用同樣的運算量,測試看看worker的能耐。
worker本身就屬於另外一個執行緒,不可能占用系統太多資源,能力差一點也是情有可原,不過這掉禎的速度確實有驚訝到我。
主要的知識點是worker可以調用Canvas API(真是太棒了!),乍聽之下讓人以為可以把繪圖的工作全部交給worker(不是嗎?),事實上,只有offScreenCanvas能夠給worker操作,無須多言,其意譯就是螢幕外的畫布,於是在worker.js中,讓它根據要求,創建一個新的畫布:
圖一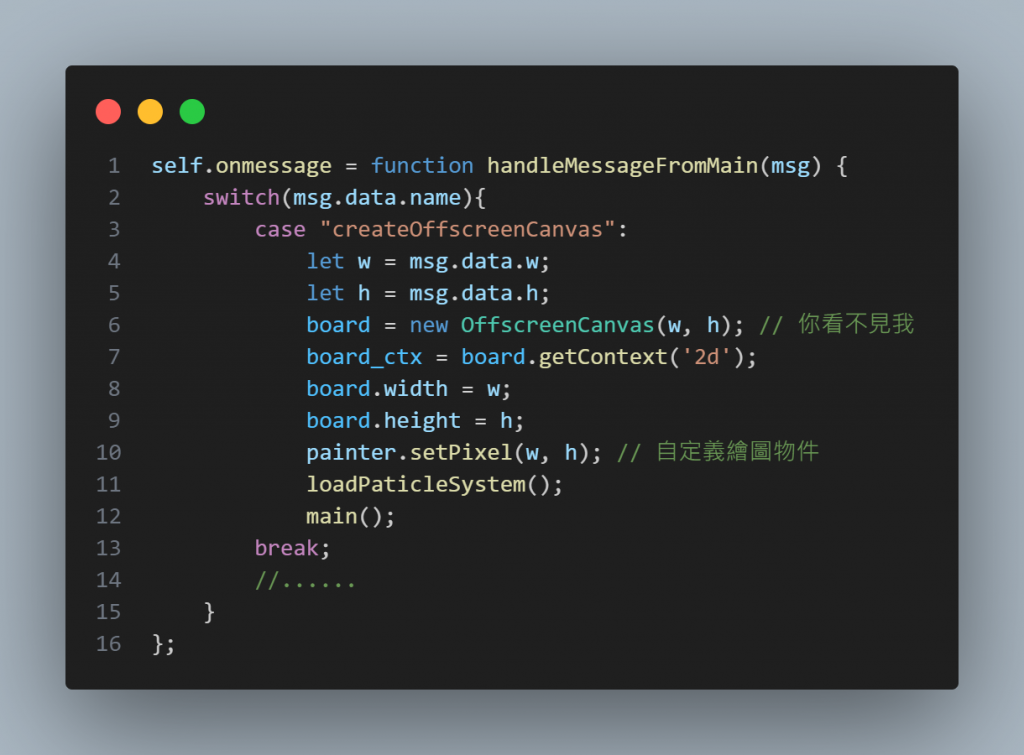
worker可以接收的訊息類型蠻多的,但沒時間跟你解釋了,先上車吧!只要不是奇怪的東西,基本都可以被postMessage方法複製一份。所以我選擇在main.js裡面寫一個物件,包含給它的指令、畫布的寬和高。
圖二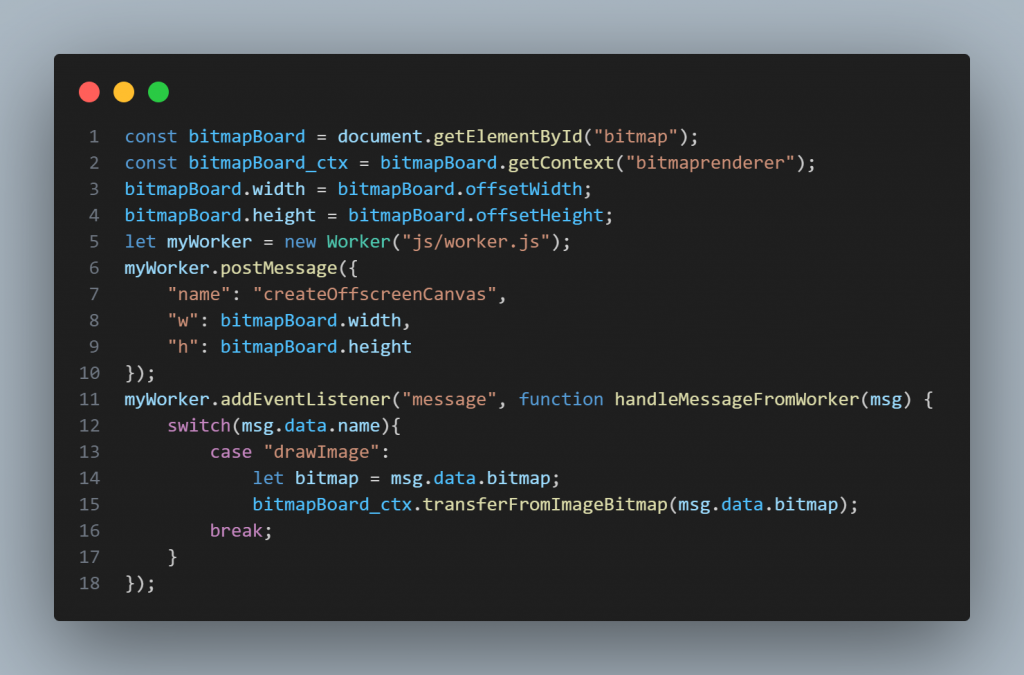
接收到bitmap後,用context.transferToImageBitmap繪圖,而且這個context還必須是用getContext("bitmaprenderer")所建立的
接著還要接收worker完成的圖像,必須以bitmap的格式傳送。因此回到work.js中,這邊我也是寫一個物件,把指令和bitmap放進去。
圖三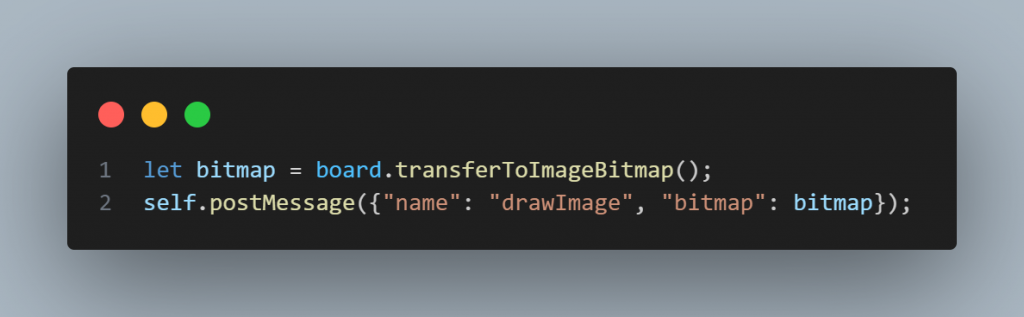
這是MDN對Web Worker的解釋:
Web Workers 可以在獨立於 Web 應用程式主執行線程的後台線程中運行腳本操作。這樣做的好處是,可以在單獨的線程中執行費力的處理,從而允許主線程(通常是UI)運行而不會被阻塞/減慢。
但是根據我這些天來爬文的資料(其實也爬不太到Orz,2020後的文章少之又少),有一派認為,由於worker不能操作DOM元件,使得通信需求和成本增加,其效率不如優化原本的代碼(不過這只是酸葡萄,他根本沒實操只是說說);還有一派用實驗告訴我們,worker大約兩三個就封頂了,再多也不會更快(好消息是那是好幾年前的事了)
首先,我們把粒子的數量從2000增加到5000,可以看到主線程fps顯著地下降了,並且左右的效能比大約從原本的7:5,變成了11:9,不難猜測,兩者之間肯定有相互影響。
接著,考慮到或許是由於一百萬像素的通信成本導致,我們先把圖三註解掉,讓worker自己畫完圖就完事了,無須擔心顯示問題,此時可以看到fps小幅提升了,看來果然有占用一些資源,但是並不多。
最後,我們直接放生worker,把圖二的postMessage註解掉,不給它指令了,換句話說,不讓它計算,此時fps從24來到了28,如此可見,多了一個worker在背景搞事情,對於主線程還是有一定的影響。
基本上不會,但嚴謹的我們還是做一下實驗,把main.js的粒子系統整個註解掉...摁,跟一開始的表現並無二致,一樣是18.19之間。
問題的關鍵是要找到關鍵的問題,那你要找到關鍵的問題,得要先找到問題的關鍵(?
拍謝XD,應該說這問題太難了,小弟不才,對硬體方面、線程、執行緒等知識不足,實在是難以下手,我只能簡化這個議題,不如想想,我每多指派一個worker,對主線程的影響程度有多大?
每個worker的任務相同,對5000個粒子進行10000次迴圈計算,並處理10000個繪圖請求。


做一個簡易的計算,將算力當作fps*1來看,再用worker的數量乘上右側的fps:
| Worker | fps(左) | fps(右) | equation | = cp |
|---|---|---|---|---|
| 2 | 19 | 17 | 19 + 2 x 17 | = 53 |
| 5 | 17 | 14 | 17 + 5 x 14 | = 87 |
| 8 | 14 | 9 | 14 + 8 x 9 | = 86 |
如此可見,我的電腦使用到5個worker,就已足以應付目前的需求,且可把禎數提升到至少87禎(介於17和14乘以6之間);另一方面,如果只用2個worker,不一定足夠,但至少有53禎。
透過以上,我們可以知道worker的能力是有限的,假如想要全部交給worker,光是2000個粒子就使禎數下降至43,如此可見至少還需要再一個worker幫忙,才能提升效能,取代主線程的工作。沒錯,目標應該是讓主線程越輕鬆越好,這樣才有更多心力去串接其他系統。
不過,現階段用worker解決效能問題,只不過是治標不治本,當繪圖愈加複雜,愈會力不從心,此時引入函式庫就會是好選擇,例如three.js,其底層使用的WebGL才是能解決效能的秘方!然而這也不代表現在的努力會白費,期待未來有能力使用Worker操作各種不同的函式庫,也是很不錯的。
在寫這篇文章前,我有草擬一個方式,是在跑4000次迴圈計算的時候,逐次傳遞訊息給worker,每次最小化訊息傳輸,並且非同步等待worker回傳粒子的座標,這個方案的優點同時也是缺點,如果算力不足,會有部分的粒子來不及在畫面渲染前更新,然而,因為大部分粒子都有刷新,人眼便看不出來掉禎的問題,即使動畫的速度的確稍有變慢。
也因為,並不能保證worker有能力處理4000次的請求,避免請求不斷堆積,故才要有等待的動作,在歷遍迴圈時,若worker還未回傳上次的請求,就不會發送,比如正常情況下,禎數只有30時(一半),在此設計下,worker僅在60禎畫面刷新前處理並回應了2000次請求,那麼另外2000次就會繼續等待,從而達到滾動式的修正。
 jerrythepotato
jerrythepotato
