突然發現網路上這種東西都被那種大師和財經達人拿來賣課程@@
我們就這樣直接分享出來會不會破壞行情xd
所以籌碼分析到底要怎麼開始? 從別人的文章或是教學來找靈感~
付錢的東西我們還是等有錢了再說,現在台股有辦法免費取得資料的方式有很多管道:
參考了一下,先來做看看這個
雖然是好幾年前的影片和文章了,還是可以借鑑一些內容:
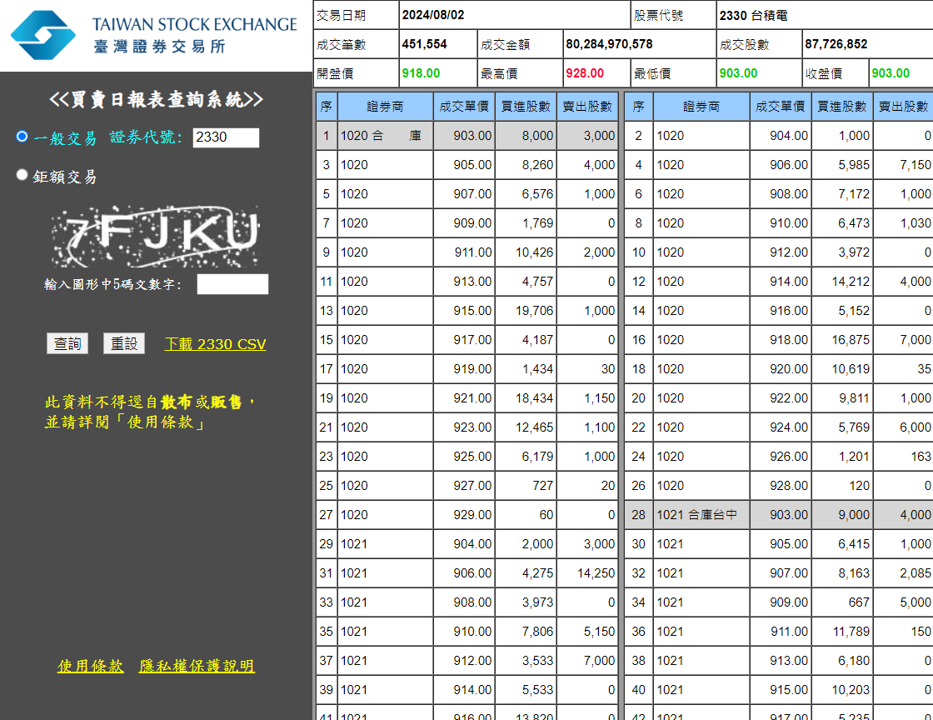
輸入你想要查詢的股票代號(證券代號) ex. 2330 (台積電)
(註. 選鉅額交易會是該交易日當天最大單、最多錢的交易紀錄,所以不會有股票代號讓你輸入)
輸入輸入圖形中5碼文數字的驗證碼 (如果會寫辨識驗證碼的程式,也是可以把這過程也自動化)

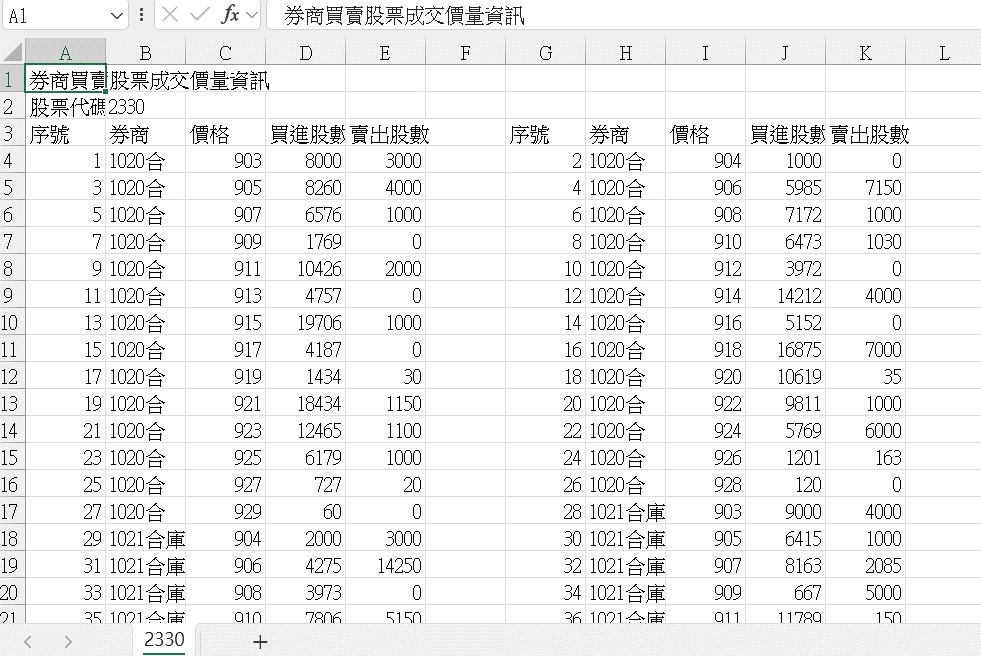
基於資料庫欄位的獨一性,那個並排的欄位和資料就不太OK~
如果在看文章的你不是資訊背景出身,可以參考一下網路上針對資料庫的一些基礎知識教學
(不然會有點霧煞煞,心裡想:為甚麼不行?? 蛤阿,好麻煩哦?)
像是 資料庫( SQL ) 建立表格 欄位介紹
我都直接把右邊並排的資料用工人智慧剪貼到左邊下面,懶得寫程式(誤
接著把欄位"序號"刪掉,用不到。
因為前陣子的紅海危機(這陣子好像又來了),讓航運類股噴了一小段行情,
# TEST 讀取資料
data = pd.read_csv("E:/時空資料分析/關鍵分點籌碼分析_實測/files_ss/2609_20240513.csv",encoding='cp950',sep=',')
#記得要把檔案的路徑改成你的
#sep=',',
#header=None
#sep='delimiter'
data
*(註. 這邊debug了一段時間,後面的cp950和下面的註解就是血淋淋的成果)
*(註. 沒辦法執行或出bug的時候會很煩,現在有chatGPT後,很多stackoverflow上解不開的問題都可以解開)
得到以下輸出:
券商 價格 買進股數 賣出股數
0 1020合 庫 64.5 0 4000
1 1020合 庫 64.9 1000 0
2 1020合 庫 65.4 1000 0
3 1020合 庫 65.6 1000 52000
4 1020合 庫 65.8 2000 0
... ... ... ... ...
11135 9A9Z永豐復興 65.4 0 1000
11136 9A9Z永豐復興 65.8 0 1000
11137 9A9Z永豐復興 66.2 0 4000
11138 9A9Z永豐復興 66.4 0 2150
11139 9A9Z永豐復興 66.6 35000 40418
11140 rows × 4 columns
會發現 每個 券商 在很多價位都有買賣,
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import seaborn as sns
# 設定圖表字體,這邊我研究很久,好不容易讓中文可以在圖上顯示
zhfont = fm.FontProperties(fname=r'C:\Windows\Fonts\kaiu.ttf') # 使用原始字串
plt.rcParams['font.family'] = zhfont.get_name()
# 資料表保存在 'data.csv' 檔案中
data = pd.read_csv('E:/時空資料分析/關鍵分點籌碼分析_實測/files_ss/2609_20240513.csv',encoding='cp950',sep=',')
# 假設資料表包含 '券商', '買進股數', '賣出股數' 三列
# 需要調整以下代碼以適應實際資料表結構
# 計算買賣超 = 買進股數 - 賣出股數
data['買賣超'] = data['買進股數'] - data['賣出股數']
# 按照券商分組,計算每個券商的總買賣超
grouped_data = data.groupby('券商')['買賣超'].sum().reset_index()
# 按買賣超排序,方便繪圖時顯示效果更好
grouped_data = grouped_data.sort_values(by='買賣超', ascending=False)
grouped_data["買賣超"] = grouped_data["買賣超"] /1000 # 1張=1000股,把股數轉換成張數
# 設定圖表大小
plt.figure(figsize=(10, 8))
# 繪製條形圖
sns.barplot(x='買賣超', y='券商', data=grouped_data, palette='coolwarm')
# 添加標題和標籤
plt.title('2609 陽明 各券商買賣超資訊', fontproperties=zhfont)
plt.xlabel('買賣超 (張數)', fontproperties=zhfont)
plt.ylabel('券商', fontproperties=zhfont)
# 顯示圖表
plt.show()
成功的話會出現這樣一張圖,
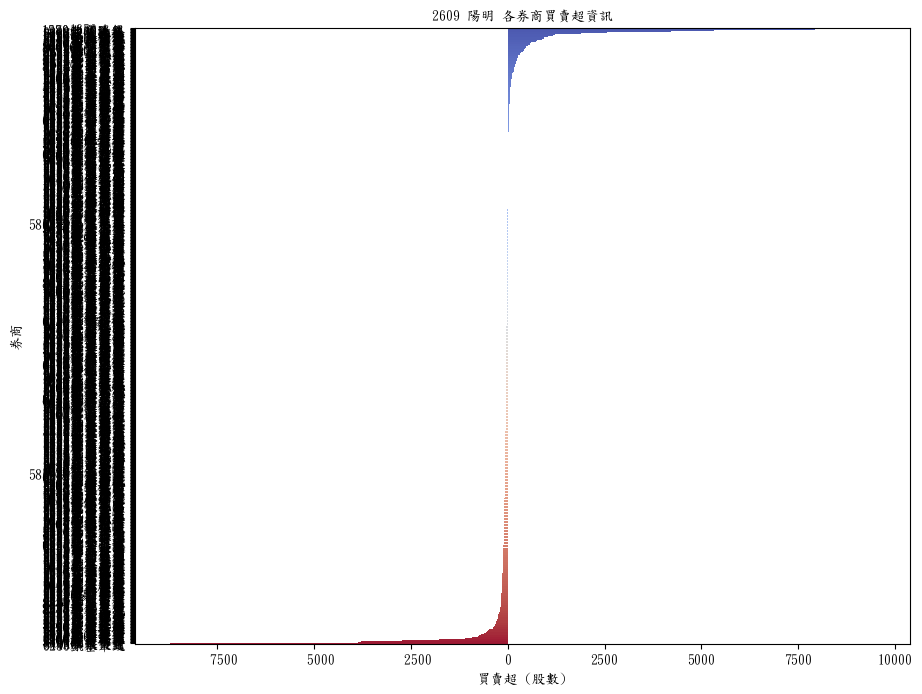
但...有沒有發現,黑壓壓的一片?
因為資料太多,字都疊在一起,也根本看不懂。
先把價格放一邊,只保留 買進張數、賣出張數
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 按買賣超排序,選取前 20 名
top_20 = grouped_data.sort_values(by='買賣超', ascending=False).head(20)
# 設定圖表大小
plt.figure(figsize=(12, 8))
# 繪製條形圖
sns.barplot(x='買賣超', y='券商', data=top_20, palette='coolwarm')
# 添加標題和標籤
plt.title('2609 陽明 各券商買賣超資訊 (買超前20名)')
plt.xlabel('買賣超 (張數)')
plt.ylabel('券商')
# 調整標籤的字體大小
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
# 顯示圖表
plt.show()
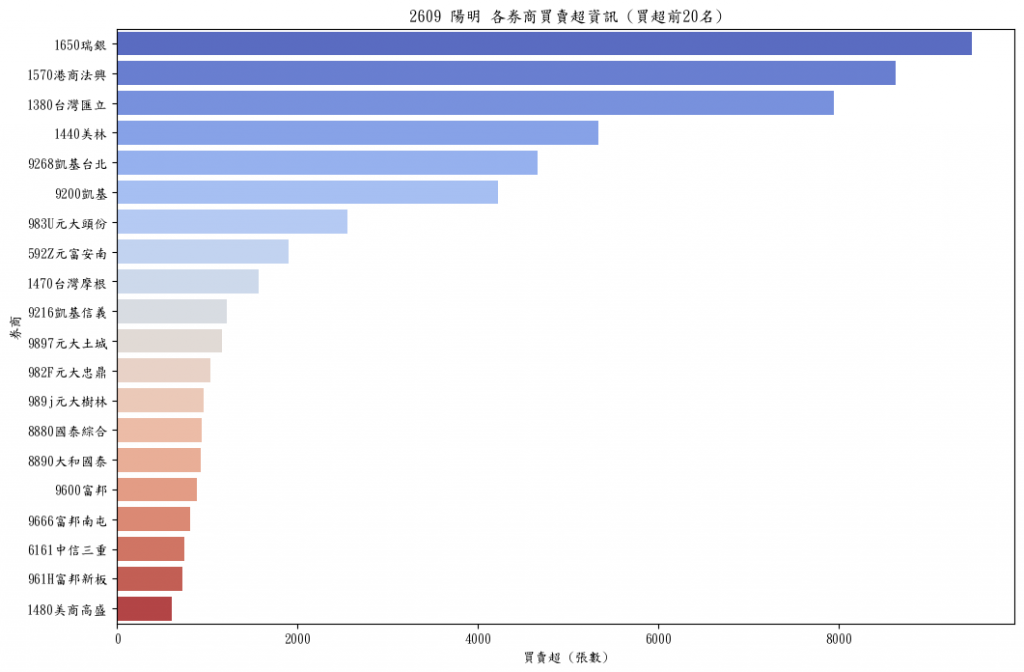
選買賣超後20名(tail,尾巴),當然就是賣超囉!
# 按買賣超排序,選取後 20 名 #賣超
tail_20 = grouped_data.sort_values(by='買賣超', ascending=False).tail(20)
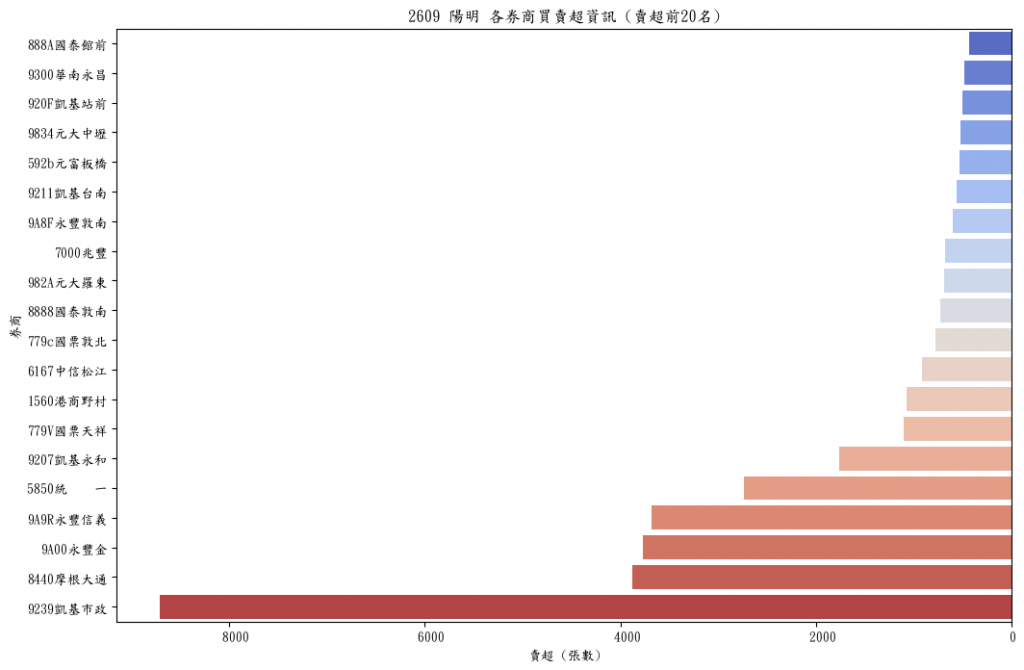
接下來嘗試把每個券商買賣的不同價格也放進來
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.font_manager as fm
# 設定字體
zhfont = fm.FontProperties(fname=r'C:\Windows\Fonts\kaiu.ttf') # 使用原始字串
plt.rcParams['font.family'] = zhfont.get_name()
# 資料表保存在 'data.csv' 檔案中
data = pd.read_csv('E:/時空資料分析/關鍵分點籌碼分析_實測/files_ss/2609_20240513.csv',encoding='cp950',sep=',')
# 確認數據表的列名
print(data.columns)
# 假設數據表包含 '券商', '分點', '買進股數', '賣出股數', '價格' 等列
# 計算買賣超
data['買賣超'] = data['買進股數'] - data['賣出股數']
#變成張數
data["買賣超"] = data["買賣超"] /1000
# 計算每個券商的總買賣超
total_buy_sell_diff = data.groupby('券商')['買賣超'].sum().reset_index()
# 計算每個券商的平均買入價格
average_buy_price = data.groupby('券商').apply(lambda x: (x['買進股數'] * x['價格']).sum() / x['買進股數'].sum()).reset_index()
average_buy_price.columns = ['券商', '平均買入價格']
# 合併買賣超和平均買入價格數據
merged_data = pd.merge(total_buy_sell_diff, average_buy_price, on='券商')
# 按買賣超排序,選取前 20 名
top_20 = merged_data.sort_values(by='買賣超', ascending=False).head(20)
# 設定圖表大小
fig, ax1 = plt.subplots(figsize=(14, 8))
# 繪製買賣超條形圖
bar = ax1.bar(top_20['券商'], top_20['買賣超'],color='lavender', label='買賣超')
#color='light lavender'(#dfc5fe)
# 添加標題和標籤
ax1.set_xlabel('券商',fontsize="12")
#ax.set_xticklabels(categories, rotation=45, ha='right')
ax1.set_ylabel('買賣超 (張數)',fontsize="12")
ax1.set_title('前 20 名券商 買超 資訊及平均價格',fontsize="16")
ax1.tick_params(axis='x', rotation=45) #讓下面的X軸資料字體不疊在一起,斜45度
# 創建第二個y軸
ax2 = ax1.twinx()
line = ax2.plot(top_20['券商'], top_20['平均買入價格'], color='r', marker='o', label='平均買入價格')
ax2.set_ylabel('平均買入價格 (元)',fontproperties=zhfont)
# 添加圖例 (右上角那個小小的方框)
bars = [bar]
lines = [line[0]]
ax1.legend(bars + lines, [bar.get_label() for bar in bars] + [line.get_label() for line in lines])
# 顯示圖表
plt.tight_layout()
plt.show()
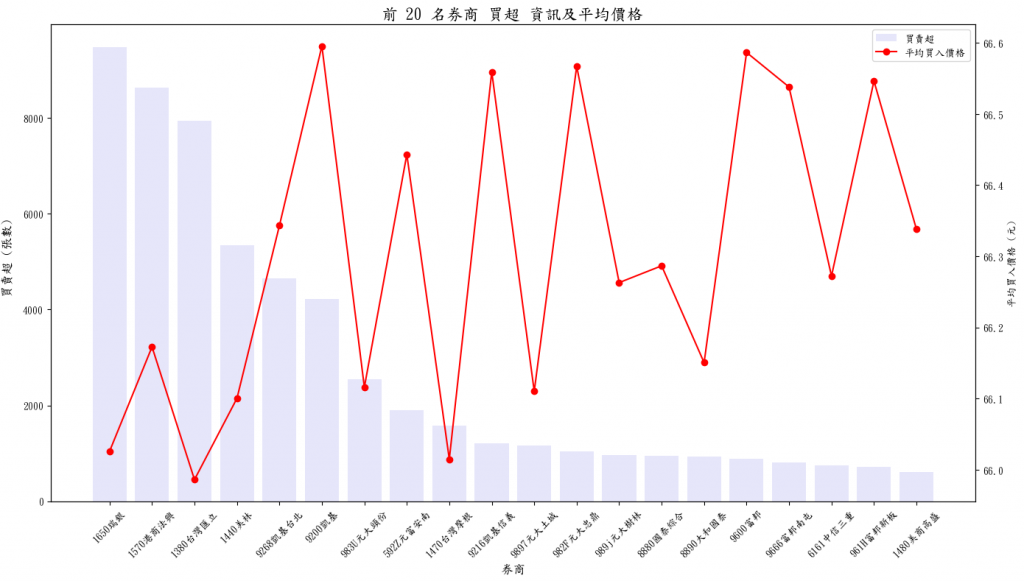
比較喜歡看數字,也可以直接看top_20
券商 買賣超 平均買入價格
71 1650瑞銀 9476.000 66.025881
69 1570港商法興 8637.000 66.172722
64 1380台灣匯立 7945.000 65.986130
65 1440美林 5337.000 66.100368
517 9268凱基台北 4658.416 66.343176
462 9200凱基 4226.445 66.595545
700 983U元大頭份 2553.941 66.115936
184 592Z元富安南 1904.160 66.443186
66 1470台灣摩根 1576.000 66.014743
485 9216凱基信義 1215.711 66.559148
746 9897元大土城 1162.650 66.110275
688 982F元大忠鼎 1037.500 66.567083
774 989j元大樹林 964.665 66.263047
396 8880國泰綜合 942.181 66.286631
407 8890大和國泰 930.000 66.150538
573 9600富邦 881.926 66.586528
618 9666富邦南屯 808.921 66.537988
213 6161中信三重 752.050 66.272246
580 961H富邦新板 725.583 66.546356
67 1480美商高盛 603.000 66.338141
# 按買賣超排序,選取後 20 名
tail_20 = merged_data.sort_values(by='買賣超', ascending=False).tail(20)
# 設定圖表大小
fig, ax1 = plt.subplots(figsize=(14, 8))
# 繪製買賣超條形圖
bar = ax1.bar(tail_20['券商'], tail_20['買賣超'],color='beige', label='買賣超')
#color='light lavender'(#dfc5fe)
# 添加標題和標籤
ax1.set_xlabel('券商')
ax1.set_ylabel('買賣超 (張數)')
ax1.set_title('前 20 名券商 賣超 資訊及平均價格')
ax1.tick_params(axis='x', rotation=45)
# 創建第二個y軸
ax2 = ax1.twinx()
line = ax2.plot(tail_20['券商'], tail_20['平均買入價格'], color='g', marker='o', label='平均賣出價格')
ax2.set_ylabel('平均賣出價格 (元)',fontproperties=zhfont)
# 添加圖例
bars = [bar]
lines = [line[0]]
ax1.legend(bars + lines, [bar.get_label() for bar in bars] + [line.get_label() for line in lines])
# 顯示圖表
plt.tight_layout()
plt.show()
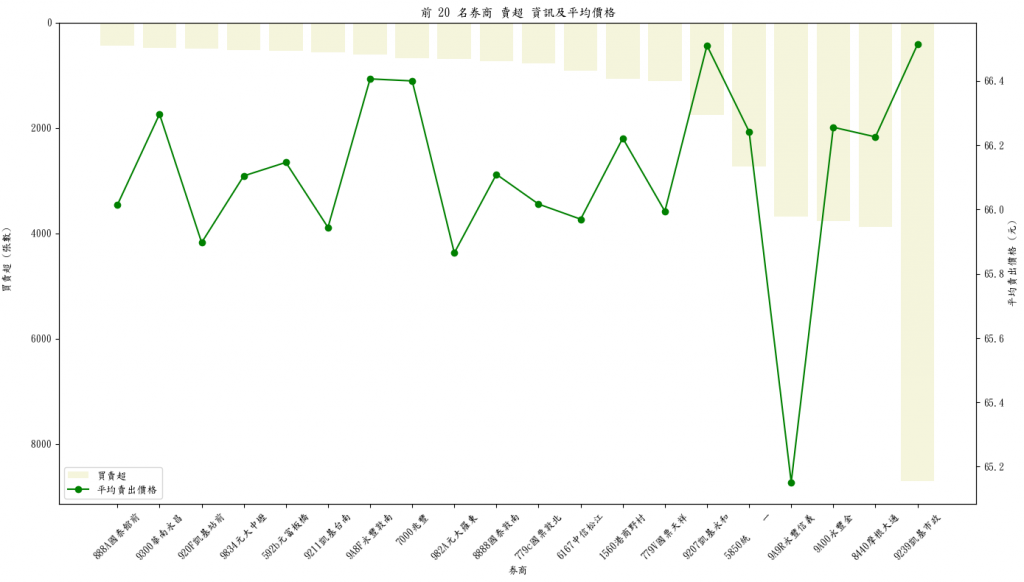
(這些券商APP也是可以查到,不過若是靠自己將這些流程自動化,
後續自己做策略,就可以不用開APP在那邊按了)
明天繼續,各位晚安!
每日記錄:
其實自己有點拖延症,看到有人在看自己的文章很開心也很驚訝,想要偷偷的寫文章度過三十天,
但是又會擔心自己亂教東西給大家(不想分享不實用的東西), by 一邊小內耗一邊前進著的I人。
文章內容幾乎都是一個字一個字打的,因為覺得用chatGPT很敷衍,一眼就看得出來了,
如果可以把內容用白話一點、簡單一點的方式讓別人學會,何不美哉(對自己的小要求)
然後原本文章打到一半,按到其他網頁跳轉,內容沒存到又重打了RRR
這個寫文章好搞剛..,上傳圖片還要把網頁移到最上面去按按鈕,傳完再回來繼續寫文章(吐血
歡迎來打招呼、問問題,按按讚~ 謝謝~

