想像你有一家公司,公司內部有成千上萬的資料,在多個不同的資料儲存處,例如Google Drive, One Drive, Drop Box, Confluence. 這些文檔都是大家覺得有必要就寫下來的,沒有遵循一個架構,你要找資料時,常常要花費大量時間搜尋,還有比對跟整理,最後才能找到你要的答案。
感謝大語言模型(以下簡稱LLM)的誕生,我們可以利用他,讓他學習我們的資料,然後回答我們的問題,省下我們大量時間。
直覺上,這聽起來是要用微調(fine-tunning)的方法,但是,在這裡我要介紹的是另一個比較好的解法,叫做RAG(Retrieval-augmented generation)。微調在面對小量資料時難以看見成效,因為你是在對參數達到7億~200億的大語言模型微調,資料量極度懸殊。
Retrieval (取回)-augmented(增強的) generation(產生),顧名思義,藉由“取回”相關文本這個額外動作,來“增強”LLM的回答能力跟正確性。
RAG架構
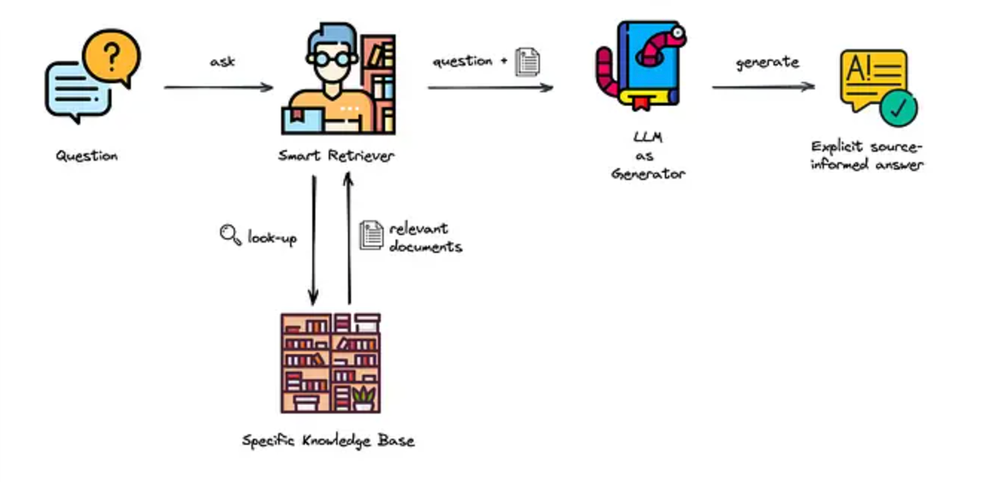
這個計畫目標在使用LLM以及RAG,以及你自己的資料,可以是公司內部的文檔,可以是超出現成LLM回答能力範圍的資料,或是特定的語言資料,例如我們都知道LLM在繁體中文的回答能力是較英文弱的。

