之前已經介紹了一些分類的方法,但是究竟要如何評估模型的分類效果,判斷它是否真正學會了分類,今天會介紹如何評估分類結果的好壞。
準確率是一個常見的方法,就是把所有預測正確的樣本數除以所有樣本數。然而,這個方法有明顯的缺陷。例如,在預測癌症的模型中,機器只需要預測所有人都沒有癌症,就可以有很高的準確率,但這顯然不是一個好的模型。
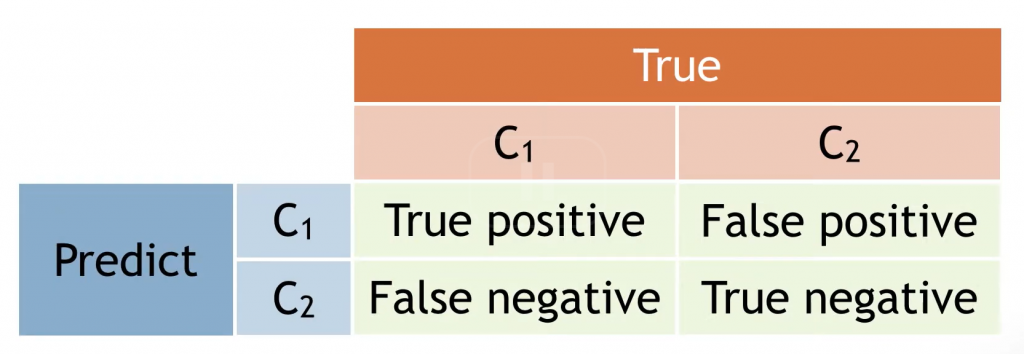
混淆矩陣是另一種評估方法,它的結構如下:
這個表可以用來計算兩種評估模型的方法:召回率 (Recall) 與精確率 (Precision)。
召回率的計算公式為:
TP/(TP+FN)
它表示在所有正樣本中,有多少被模型正確偵測出來。
精確率的計算公式為:
TP/(TP+FP)
它表示模型偵測出的正樣本中,有多少是真正的正樣本。
F1-score 將召回率與精確率結合,是它們的調和平均數,計算公式如下:

這些評估方式在各領域都有應用,不同領域有不同的名詞:
ROC 空間是由 TPR 與 FPR 所畫出的二維空間。
TPR 表示正樣本被正確判斷為正樣本的比例,FPR 表示負樣本被錯誤判斷為正樣本的比例。
假設我們有三個模型 A、B 和 C:
將它們在 ROC 空間中畫出來: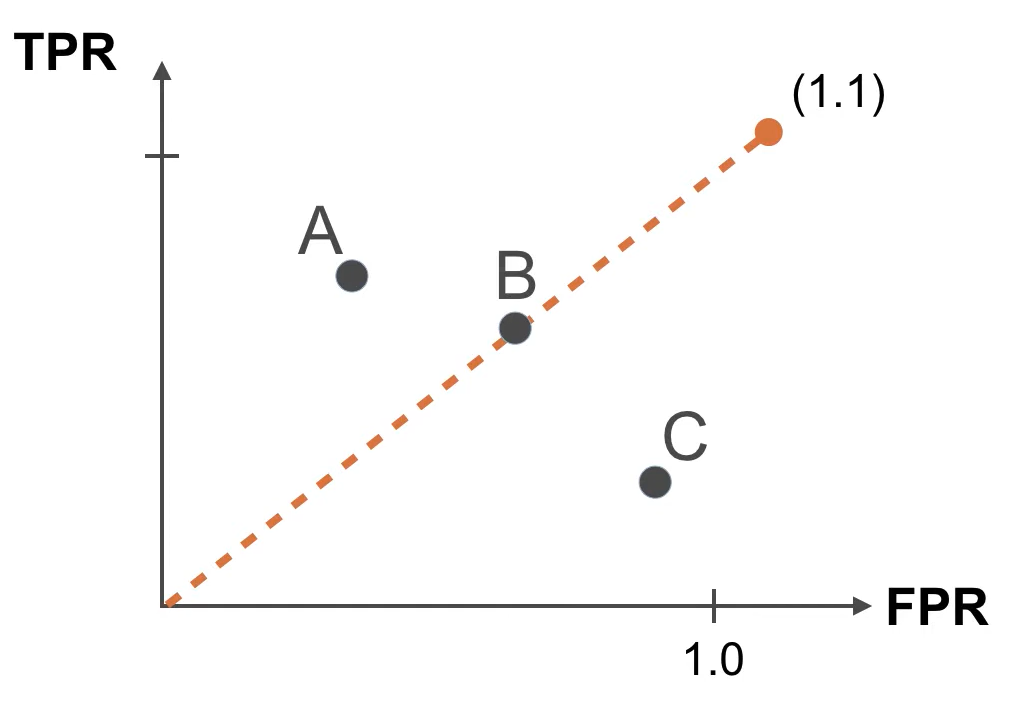
因此,越靠近左上角的模型越好,越靠近右下角的模型越差。
我們可以為模型設定不同參數,並在 ROC 空間中畫出如下曲線,稱為 ROC 曲線。評估這個曲線的方法是計算曲線下方的面積,稱為 AUC (Area Under the Curve)。理想的 AUC 為 1,表示完美的模型,但現實中 AUC 通常在 0.5 到 1 之間,AUC 越高表示模型越好。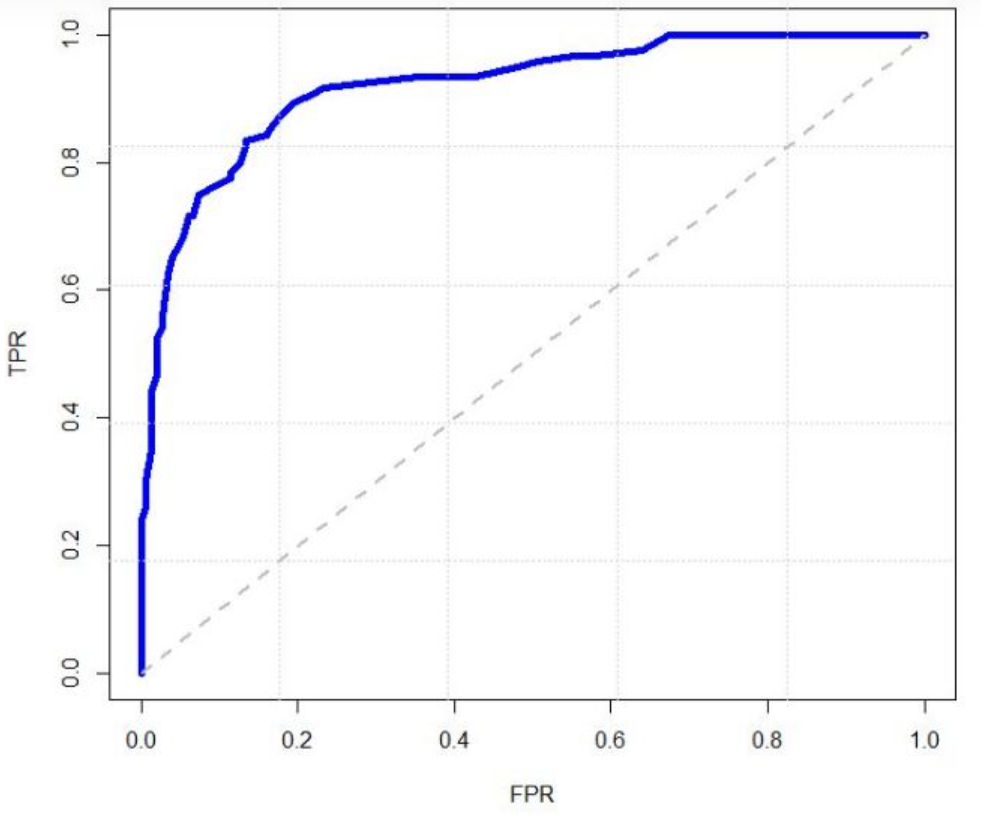
在選擇評估方式時,應根據樣本數控制不變的情況下選擇適當的方法。一般來說,ROC 或 AUC 不會受樣本數影響,是較佳選擇,F1-score 也不受樣本數影響,同樣是良好的評估方式。


 iThome鐵人賽
iThome鐵人賽