並不是。雖然高正確率是理想的,但過高的正確率可能意味著模型過於複雜,可能已經發生過擬合(overfitting)的情形。過擬合的模型在訓練數據上表現很好,但在未知數據上表現不佳。
不一定。雖然複雜的模型可能在訓練數據上表現優異,但容易過擬合。理想的模型應該能夠捕捉數據的趨勢,而不是記住每一個數據點。如下圖,我們可能會覺得右邊這種彎彎曲曲的線是一個比較好的模型,但是我們其實會傾向於使用左邊的這種線性回歸的模型,並不只是因為它比較好做,還有就是右邊這個模型很容易發生過擬合的情形。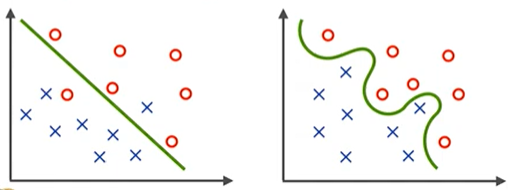
過擬合就像在考試時背下所有的考古題,若考題是考古題,正確率會很高,但如果考題是新的,正確率會很低。這種情形下,模型並未學習到數據的趨勢,而只是記住了訓練數據。
模型過於複雜時,容易記住訓練數據中的噪音點,這些噪音點可能並不代表真正的數據分布。相較之下,簡單的線性模型雖然可能會錯誤分類一些點,但這些錯誤點可能是噪音,並不影響模型的整體性能。
如果模型能夠完全正確地分類訓練樣本,但無法準確預測未知樣本,則模型可能已經過擬合。這可通過計算誤差與準確率來判斷。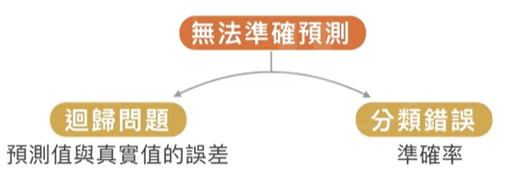
為了評估模型在未知數據上的性能,需要將資料切割成訓練集和測試集。訓練集用於訓練模型,而測試集用於檢驗模型是否過擬合。
通常,訓練集和測試集的比例為8:2或9:1。資料切割前需將資料打散,以避免取到極端值資料。為了更準確地評估模型,常使用交叉驗證法。
每次取出一個樣本作為測試樣本,剩下的作為訓練樣本,重複所有樣本,最後取平均。此方法在樣本數多時效率較低。
將資料集等分成k個子集,每次取一個子集作為測試樣本,其餘k-1個子集作為訓練樣本,重複k次,最後取平均。這是最常用的做法。

欠擬合是指模型無法在訓練樣本和測試樣本上取得足夠的準確率。它和過擬合一樣都是我們極力避免的情況。
在製作模型時,我們需要能夠觀察出這兩種情況的發生,並通過正確率來判斷模型是否適合。


 iThome鐵人賽
iThome鐵人賽