反向索引 ( Inverted Index ) 是資訊檢索中非常重要的一種資料儲存方式,我們接下來要介紹的 TF-IDF 和 BM25 都會用到這個概念。
反向索引也常被叫做倒排索引,為什麼會說它是反向的呢?
同樣以這三篇文章為例:
doc1 : “I like banana.”
doc2 : “I don’t like orange.”
doc3 : “I don’t like apple.”
一般儲存的方式大多是把整篇文章放在一起,比方說像下面這張圖:
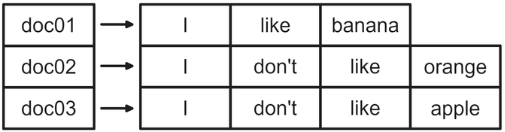
這樣在做 Linear Search 的時候就需要每一篇文章都檢查過一次,效率不好。
然而反向索引非常特別的是,它採用了像教科書後面索引 ( Index ) 這樣的儲存方式,也就是在每一個單詞的後面紀錄它有出現的文章,像下面這張圖:
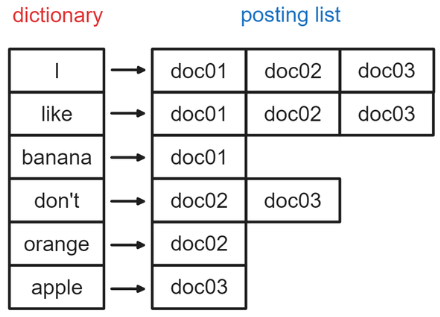
我們把每一個單詞叫做一個 term,所有單詞的集合叫做 dictionary 或 vocabulary,而每一篇文章的 ID 用 docID 或 posting 來表示,一個單詞後面指向的文章 ID 集合就叫做 posting list。
如此一來,我們不只從原本 Term-Document Incidence Matrix 只記錄 0 和 1 的方式,變成更省空間的 Inverted Index,而且如果使用者想要從關鍵字去找相關文檔的話,只需要把 term 對應的 posting list 拉出來運算就能得到檢索結果,效率提升很多。
在了解反向索引這麼好用之後,我們就來實作看看吧!
之前學到的資料前處理在這裡派上用場了,我們要做的事情就是先建立一個字典,然後對每一篇文章掃過去,一步一步把 docID 和新的 term 補齊:
import string, nltk
from nltk import word_tokenize
from collections import defaultdict
nltk.download('punkt')
def preprocess(text):
text = text.lower()
text = ''.join([word for word in text if word not in string.punctuation])
tokens = word_tokenize(text)
return tokens
def build_inverted_index(documents):
index = defaultdict(list)
for doc_id, doc in enumerate(documents, start = 1):
tokens = preprocess(doc)
for token in tokens:
if doc_id not in index[token]:
index[token].append(doc_id)
return index
documents = ["I like banana.", "I don't like orange.", "I don't like apple."]
total_docs = set(range(1, len(documents) + 1))
inverted_index = build_inverted_index(documents)
print(inverted_index)
{'i': [1, 2, 3], 'like': [1, 2, 3], 'banana': [1], 'dont': [2, 3], 'orange': [2], 'apple': [3]}
這樣就成功建立起一個反向索引了!
接著,我們可以應用剛剛創造出來的 inverted_index 去進行布林檢索,這邊的 user query 格式是我自己定義的:
# find posting list
def F(term):
return set(inverted_index.get(term, []))
# boolean retrieval
def NOT(posting_list):
return total_docs - posting_list
def AND(term_1, term_2):
return term_1 & term_2
def OR(term_1, term_2):
return term_1 | term_2
user_query = AND(F("dont"), NOT(F("apple")))
result = [documents[i - 1] for i in user_query]
print(result)
["I don't like orange."]
不過,布林檢索本身還是存在一些問題的。
首先,它只能呈現二元的搜尋結果,也就是判斷這個文章是相關還是不相關,然而我們熟知的搜尋引擎卻不是這個樣子。
以 google search 為例,使用者輸入關鍵字之後,它不僅會傳回相關文檔,還會按照相關性做排名,而在布林檢索中,使用者無從得知這些找到的文檔中誰的相關性更高。
另外一個問題是,它無法處理更彈性的提問,舉例來說,使用者如果輸入 查詢有 love 和 banana 的文章 的話,就不符合布林檢索要求的格式了,而且因為電腦無法分辨 love 和 like 的語意相似性,因此所有和 like 相關的文檔都無法被檢索到。
這些問題都導致布林檢索只能在簡單的情境中應用,不過後續要介紹的檢索方式就會越來越複雜,逐步解決這些問題。
推薦文章
【資訊軟體知識】資料檢索技術 — 倒排索引(Inverted Index)
Inverted index in information retrieval


 iThome鐵人賽
iThome鐵人賽