目前想找些學術跟應用價值都有的 github 項目。
我想先試著理解這個項目:LongWriter
LongWriter 這個項目簡單來說就是一次能輸出10000+的文本的應用。
github專案網址: https://github.com/THUDM/LongWriter
論文網址: https://arxiv.org/abs/2408.07055
LongWriter,一種能夠讓現有長上下文大型語言模型 (LLM) 生成超過 10,000 字輸出內容的方法。
主要發現和貢獻:
問題: 現有 LLM 雖然能處理長輸入(高達 10 萬 tokens),但輸出長度卻受限(通常不超過 2000 字)。
原因: 研究發現,模型的有效生成長度受限於其在監督式微調 (SFT) 階段所見到的樣本。
解決方案: 提出了 AgentWrite,一種基於代理的流程,將超長生成任務分解為子任務,使現有 LLM 能生成超過 2 萬字的連貫輸出。
LongWriter-6k 資料集: 利用 AgentWrite 構建了一個包含 6000 個 SFT 數據的資料集,輸出長度在 2k 到 32k 字之間。
模型改進: 通過將 LongWriter-6k 納入模型訓練,成功將現有模型的輸出長度擴展到 1 萬字以上,同時保持輸出品質。
LongBench-Write 基準測試: 開發了一個用於評估超長生成能力的綜合基準測試。
state-of-the-art 性能: 他們 9B 參數的模型,進一步透過 DPO 改進,在 LongBench-Write 上達到 state-of-the-art 性能,甚至超越了更大的專有模型。
結論:
LongWriter旨在解決目前大型語言模型(LLMs)在生成長文本時的限制。儘管現有的 LLMs 能夠處理高達 10 萬個標記的輸入,但在生成超過 2000 字的輸出時會遇到困難。這主要是因為現有的數據集缺乏長輸出的樣本,導致模型的生成能力受限。
為了解決這個問題,研究人員引入了名為 AgentWrite 的代理型管道,將超長生成任務分解為多個子任務,從而使現有的 LLMs 能夠生成超過 2 萬字的連貫輸出。利用這一管道,他們構建了一個包含 6000 條數據的 SFT(Supervised Fine-Tuning)數據集,輸出長度範圍在 2000 到 32000 字之間。將這個數據集應用於模型訓練後,他們成功地將現有模型的輸出長度擴展到超過 1 萬字,同時保持了輸出的質量。
此外,他們還開發了一個名為 LongBench-Write 的綜合基準,用於評估超長生成能力。他們的 90 億參數模型通過 DPO(Distributional Policy Optimization)進一步改進後,在這個基準上達到了業界領先的性能,甚至超越了許多規模更大的專有模型。
總的來說,這項研究展示了長上下文 LLMs 的潛力,只需要適當的數據集來解鎖這一能力。
研究發現目前長上下文大型語言模型雖然能處理很長的輸入,但輸出長度卻受限於監督式微調階段所見到的樣本。為解決此問題,研究人員提出了 AgentWrite,這是一種基於代理的流程,能將超長生成任務分解為子任務,使現有 LLM 能生成超過 2 萬字的連貫輸出。他們還構建了 LongWriter-6k 資料集,並透過將其融入模型訓練,成功將現有模型的輸出長度擴展到超過 1 萬字。此外,他們開發了 LongBench-Write 基準測試,其 90 億參數模型在該基準測試上達到最先進的性能。這項工作證明,現有的長上下文 LLM 已經具備生成更長輸出的潛力,關鍵在於在模型對齊階段提供具有更長輸出的數據。
儘管長上下文大型語言模型(LLM)在處理長輸入方面取得了進展,但它們在生成長輸出方面仍存在限制。研究發現,這種限制是由於監督式微調(SFT)階段缺乏長輸出樣本所致。為了解決這個問題,研究人員引入了 AgentWrite,這是一種將超長生成任務分解為子任務的方法,使現有 LLM 能夠生成更長的連貫輸出。他們還構建了一個包含長輸出樣本的資料集 LongWriter-6k,並透過將其融入模型訓練,成功地將現有模型的輸出長度擴展到超過 10,000 字。
這篇論文探討了當前長上下文大型語言模型(LLM)在生成長輸出方面的限制,並發現其主要原因在於監督式微調(SFT)資料集中缺乏長輸出範例。為了解決這個問題,研究人員提出了 AgentWrite,這是一種基於代理的流程,透過將超長生成任務分解為子任務,使現成的 LLM 能夠生成超過 20,000 字的連貫輸出。他們還構建了一個包含長輸出樣本的資料集 LongWriter-6k,並透過將其融入模型訓練,成功地將現有模型的輸出長度擴展到超過 10,000 字。實驗結果表明,他們的模型在超長生成任務上取得了最先進的性能。這項工作證明,現有的長上下文 LLM 已經具備生成更長輸出的潛力,關鍵在於在模型對齊階段提供具有更長輸出的數據。
這項研究發現了限制當前長上下文大型語言模型輸出長度的主要因素,並提出了 AgentWrite 方法來克服這一限制。透過使用 AgentWrite 構建的 LongWriter-6k 資料集,成功地將現有模型的輸出窗口大小擴展到 10,000 多個詞,同時保持輸出品質。實驗結果表明,他們的模型在超長生成任務上取得了最先進的性能。
基於 AgentWrite 流程,作者們利用 GPT-4 生成了 6,000 筆長輸出 SFT 數據,命名為 LongWriter-6k,並將這些數據添加到現有模型的訓練中。值得注意的是,LongWriter-6k 成功地釋放了模型生成結構良好、長度超過 10,000 字的輸出的能力(詳見第 4 節)。為了嚴格評估我們方法的有效性,他們開發了 LongBench-Write 基準測試,其中包含一組多樣化的用戶寫作指令,輸出長度規格範圍從 0-500 字、500-2,000 字、2,000-4,000 字到超過 4,000 字。在 LongBench-Write 上的評估表明,我們的 9B 參數模型達到了最先進的性能,甚至超越了更大的專有模型。我們進一步構建了偏好數據,並使用 DPO (Rafailov et al., 2024) 來幫助模型更好地遵循長寫作指令並生成更高質量的書面內容,這在實驗中也得到了證明。
總之,他們的工作做出了以下創新貢獻:
首先,作者構建了 LongWrite-Ruler 評估方法,旨在輕巧地探究大型語言模型(LLMs)的生成長度極限。研究發現,訓練數據的最大輸出長度與模型生成能力呈正相關。同時,專有模型的有效輸出窗口往往小於其理論最大值,且當長度要求超過一定閾值時,平均輸出長度反而下降。
研究人員假設模型的常見 2,000 字輸出長度限制是由於監督微調(SFT)數據中固有的輸出長度限制。為了驗證這一假設,他們通過改變 SFT 數據進行了控制實驗。使用 GLM-4-9B 模型,他們通過過濾輸出長度超過 500、1,000 和 2,000 字的數據創建了三個訓練集。結果顯示,模型的最大輸出長度隨著 SFT 數據中的最大輸出長度成比例增加,分別達到約 600、900 和 1,800 字。這表明模型的輸出限制主要是由於 SFT 數據中的輸出長度不足,而這一限制無法通過合成的訓練數據或迭代 SFT 來克服。研究人員最後提出應探索構建具有更長輸出長度的 SFT 數據,以增強模型生成更長輸出的能力。
研究人員提出通過使用現成的大型語言模型(LLM)自動生成具有更長輸出的 SFT 數據,並設計了名為 AgentWrite 的分而治之式代理管道。AgentWrite 將長篇寫作任務分解為多個子任務,每個子任務只要求模型撰寫一個段落。隨後,模型依次完成這些子任務,並將輸出連接起來以形成最終的長篇輸出。這種利用 LLM 代理將複雜任務分解為子任務的方法已經在多個領域應用,但這項研究是首次探索將計劃整合進來,以使模型能夠完成複雜的長篇寫作任務。研究人員將詳細介紹 AgentWrite 的每個步驟。
研究人員受到人類作家思維過程的啟發,通常在進行長篇寫作任務時,會先制定整體計劃,概述結構並規劃每個部分的內容和長度。他們運用 LLM 的計劃能力來根據給定的寫作指令生成寫作大綱,該大綱包括每個段落的主要內容和字數要求。研究人員還提供了用於此目的的提示詞。
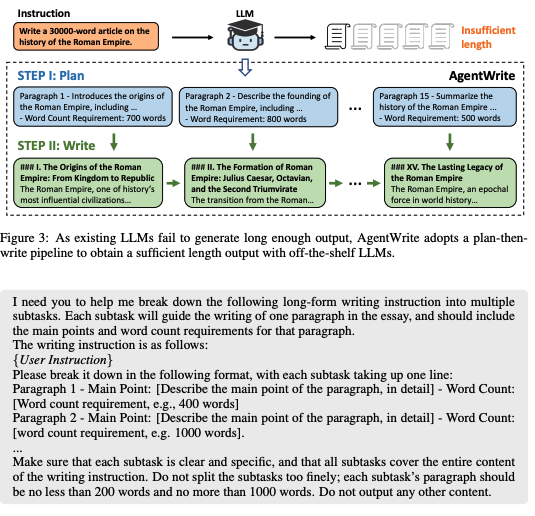
在獲得寫作計劃後,研究人員使用 LLM 依次完成每個子任務,逐段生成內容。為了保持連貫性,在生成第 n 段時,他們會輸入前面已生成的 n−1 段,讓模型能夠基於已有的內容繼續撰寫。雖然這種串行方式無法同時平行處理多個子任務,且輸入的長度會增加,但他們的驗證結果顯示,以這種方式生成的寫作內容在整體連貫性和質量上遠優於平行生成的輸出。他們也提供了用於此過程的提示詞。


研究人員使用兩個長篇寫作數據集測試了他們提出的 AgentWrite 方法的生成長度和質量。第一個數據集 LongWrite-Ruler 用於測量該方法能生成的最大輸出長度。第二個數據集 LongBenchWrite 是專門構建的,主要用來評估模型生成的內容在長度和寫作質量方面與用戶指令的符合程度。
LongBench-Write 評估模型在多樣化的長篇寫作指令上的表現,收集了120個不同的用戶寫作提示,其中60個為中文,60個為英文。為了更好地評估模型是否滿足用戶的字數要求,所有這些指令都明確規定了字數要求。這些指令被分為四個子集,基於字數要求分為0-500字、500-2,000字、2,000-4,000字和超過4,000字。此外,這些指令根據輸出類型被分類為七種類型:文學與創意寫作、學術與專著、科普文章、功能性寫作、新聞報導、社區論壇以及教育與培訓。各子集中的數據數量列於表1中。
在評估過程中,使用兩個指標:一個用於評分輸出字數,另一個用於評分輸出質量。希望模型的輸出字數盡可能接近指令中指定的要求,因此使用分段線性函數來計算輸出字數分數 (S_l)(其中 (l) 是要求的字數,(l') 是實際輸出字數)。
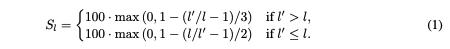
簡而言之,當模型的輸出長度符合要求時,得分為100分。如果輸出長度超過要求的4倍或低於要求的1/3,得分將線性下降至0分。由於輸出過短通常比過長更具問題性,因此對於過短輸出設定了較高的得分衰減係數。
為了自動評估輸出質量,採用了LLM-as-a-judge的方法,選擇了最先進的GPT-4o模型作為評判模型,從六個維度進行打分:相關性、準確性、連貫性、清晰度、廣度與深度,以及閱讀體驗(具體打分提示請參考附錄C)。為了儘量將質量指標與長度分數 (S_l) 解耦,指示評判模型僅基於輸出質量進行打分,不考慮輸出長度。最後的質量分數 (S_q) 是六個維度分數的平均值,最終分數 (S¯) 則是 (S_l) 和 (S_q) 的平均值。
研究發現,AgentWrite 成功將 GPT-4o 的最大輸出長度從2,000字擴展到約20,000字。此外,作者在 LongBench-Write 上評估了輸出質量和對要求字數的符合程度。考慮到 GPT-4o 能夠成功完成字數在2,000字以下的任務,因此在評估 AgentWrite 的性能時,作者僅在要求輸出字數超過2,000字的指令上應用 AgentWrite。他們還評估了一個 AgentWrite 的變體,稱為 "+Parallel",該變體在第二步中並行調用模型來為每個段落生成輸出。
結果顯示,AgentWrite 在提高內容長度的同時,對生成內容的質量並未造成明顯影響,尤其在廣度和深度維度上分別提升了5%。然而,連貫性和清晰度分數略有下降(減少2%)。文本中還指出,使用 AgentWrite 生成的內容有時會出現重複現象,例如重複前面段落的內容或頻繁進行總結。另外,+Parallel 處理在一定程度上增加了內容長度,但對質量,特別是連貫性,產生了負面影響(下降6%)。這表明在 AgentWrite 的第二步驟中,必須為模型提供先前生成的上下文。
這節主要描述了在已有的代理框架下,使用現成的大型語言模型(LLM)來自動生成較長的輸出內容後,提出了一個新的問題:是否可以教導這些模型具備生成超長內容的能力,讓它們能夠在單次輸出中完成長篇寫作任務?為了回答這個問題,作者進行了模型訓練實驗,並將在後續部分討論訓練數據的構建、模型訓練過程及實驗結果。
這節描述了作者如何選取和處理訓練數據,以訓練模型生成超長內容。具體步驟如下:
選取用戶指令:從現有數據集中選取了需要長篇輸出的6,000條用戶指令,這些指令的輸出要求超過2,000字。具體來說,從GLM-4的SFT數據中選取了3,000條指令(主要為中文),另外從WildChat1M(主要為英文)中選取了3,000條指令。
自動選擇過程:使用GPT-4o進行自動選擇,並通過規則匹配過濾掉有害指令和意圖進行數據抓取的指令。經過人工檢查,確認超過95%的指令確實需要生成數千字的回應。
使用AgentWrite生成回應:對這6,000條指令,使用AgentWrite流程與GPT-4o來生成回應。隨後對生成的數據進行後處理,包括過濾掉過短的輸出,以及模型在AgentWrite第一步中因計劃步驟過多而崩潰的情況。最終過濾掉約0.2%的數據,並清除模型可能添加的無關標識符(如“第1段”、“第2段”)。
形成最終數據集:最終得到的長篇輸出數據集被稱為“longwriter-6k”。
模型訓練:為了保證模型的通用能力,作者將longwriter-6k與通用SFT數據結合,形成完整的訓練集。在實驗中,使用了來自GLM-4的180k條聊天SFT數據作為通用SFT數據。圖5展示了獲得數據的輸出長度分佈,顯示出longwriter-6k有效補充了通用SFT數據在2,000字以上輸出長度方面的稀缺性,且longwriter-6k的輸出長度在2,000-10,000字之間分佈相對均勻。
此節的研究探討了如何通過監督微調和對齊技術來提升大型語言模型(LLMs)生成超長內容的能力。研究主要集中在使用最新的開源模型進行訓練,以滿足長篇輸出需求,並進一步優化模型的輸出質量和指令長度的遵循性。
首先,研究選擇了兩個開源基礎模型進行監督微調,分別是 GLM-4-9B 和 Llama-3.1-8B。這兩個模型都支持最多128k tokens 的上下文窗口,使它們非常適合用於長篇輸出內容的訓練。為了提高訓練效率,研究採用了結合損失權重的打包訓練方法。通過這一過程,研究成功地訓練出兩個新的模型,即 LongWriter-9B(基於 GLM-4-9B 的版本)和 LongWriter-8B(基於 Llama-3.1-8B 的版本)。
在訓練過程中,研究團隊發現,如果按序列平均損失,即在一個批次中取每個序列的平均損失,則長篇輸出數據中每個目標 token 對損失的貢獻會顯著小於短篇輸出的 token。這導致模型在處理長篇輸出任務時表現不佳。為了解決這一問題,研究採用了一種按 token 平均損失的策略,這種策略計算的是批次內所有目標 token 損失的平均值,從而更好地平衡了長短篇輸出數據的訓練效果。整個模型訓練過程使用了8個 H800 80G GPU,結合了 DeepSpeed+ZeRO3+CPU 卸載技術,批次大小為8,學習率設定為1e-5,打包長度為32k,共訓練了4個 epoch,總計約需2,500到3,000個步驟。
為了進一步提升模型的輸出質量並加強其遵循指令長度限制的能力,研究團隊對已經進行過監督微調的 LongWriter-9B 模型進行了直接偏好優化(DPO)。DPO 數據主要來自 GLM-4 的聊天 DPO 數據集(約50k條),此外,研究團隊還專門針對長篇寫作指令構建了4,000對數據。具體來說,對於每條寫作指令,研究從 LongWriter-9B 中取樣了4個輸出,並根據參考文獻中的方法對這些輸出進行打分。同時,研究還結合了一個長度跟隨分數,選取得分最高的輸出作為正樣本,並隨機選擇其餘三個輸出中的一個作為負樣本。最終,研究在這些數據的基礎上對 LongWriter-9B-DPO 模型進行了250步的訓練,並成功提升了模型的輸出質量。
作者對4個專有模型和5個開源模型進行了LongBench-Write評估,這些模型的詳細信息列於表5中,同時還包含了我們訓練的LongWriter模型。據我們所知,Suri-IORPO (Pham et al., 2024) 是目前唯一一個針對長篇文本生成進行過對齊的先前模型。該模型基於Mistral-7B-Instruct-v0.2 (Jiang et al., 2023) 進行了訓練,並使用了LoRA (Hu et al., 2021) 技術。
為了保持與LongWrite-Ruler評估設置的一致性,我們將輸出溫度設置為0.5,並將模型的生成最大tokens參數配置為API調用允許的最大值。對於開源模型,我們將該參數設置為32,768。主要結果列於表3中,我們還在表8中報告了平均回應長度和中位數回應長度。圖6則繪製了在LongBench-Write中的120條指令下,各模型回應長度相對應需求長度的變化圖。以下是我們的主要發現。
長篇文本生成能力:各模型在長篇文本生成方面的表現存在顯著差異,訓練後的LongWriter模型在回應長度和質量方面表現優異,尤其是在生成超過2,000字的長篇內容時。
回應長度:專有模型和開源模型的回應長度均達到了預期目標,但在回應質量方面存在差異。LongWriter模型的回應更符合指令中的長度要求,平均回應長度較其他模型更接近需求長度。
Suri-IORPO的表現:Suri-IORPO作為唯一針對長篇文本生成進行過對齊的先前模型,在某些指標上與LongWriter模型相當,但在某些情況下,回應的長度和質量略遜於LongWriter模型。
過去的研究和實驗表明,大多數現有模型難以滿足超過2,000字的文本生成要求。特別是在需要生成4,000到20,000字的長文本時,許多模型幾乎無法達到目標輸出長度,甚至有的模型在這一範圍內得分為0,這意味著這些模型生成的文本長度不足所需長度的三分之一。唯一的例外是Claude 3.5 Sonnet模型,在需要2,000到4,000字的指令中表現相對較好,長度分數(Sl)達到了相對令人滿意的水平。
為了解決這一問題,作者引入了LongWriter模型,通過加入來自LongWriter-6k的訓練數據,使得模型能夠在生成長文本方面表現出色。另外為了驗證LongWriter模型生成的長文本是否具有這些特性,作者採用了長上下文LLM的累積平均負對數似然(NLL)測試。這一測試通常用來評估長上下文LLM在建模長文本中的長距依賴性能力,並且可以反向應用來檢測生成文本中的長距依賴性,以確保文本的質量。
在測試中,使用了兩個支持128k上下文窗口的現有長上下文模型:GLM-4-9B 和 Llama-3.1-8B。我們在大約100個超過8,192 tokens的文本樣本中進行了測試,結果顯示,這兩個模型在文本後期位置的預測顯著改善,這表明LongWriter模型的輸出中存在廣泛的長距依賴性。因此,可以確定LongWriter模型生成的長文本不僅僅是無關段落的簡單拼湊,而是具有連貫性和邏輯性的高質量長文本。
研究發現,通過對LongWriter-9B模型進行DPO訓練,該模型的長度分數(Sl)提高了4%,質量分數(Sq)提高了3%,這種提升在所有範圍內都是一致的。這表明DPO在長文本生成場景中能顯著提升模型的輸出品質,並更好地使輸出長度與要求對齊。手動標注的結果顯示,58%的情況下,人們更偏好經過DPO訓練的模型,而LongWriter-9B-DPO的表現甚至與參數更多的GPT-4不相上下。
目前,LongWriter模型的輸出長度擴展到10k至20k字之間,但要支持更長的輸出,還需要更多具有長輸出的數據。測試結果顯示,模型的最大生成長度受限於10k-20k字。缺乏更長輸出的SFT訓練數據是阻礙模型實現更長輸出的主要原因。未來如果能構建更長的訓練數據集,模型的輸出長度可能會突破到100k字甚至更長。
研究人員進行了一系列消融實驗,以評估不同數據集和技術對 LongWriter-9B 模型的影響。結果顯示,LongWriter-6k 數據集對於模型處理長輸出和提升輸出質量至關重要,特別是在回答需要詳細闡述的提問時。雖然加入 LongWriter-6k 數據集後,模型在處理 2,000 字以上的輸出時表現出色,但並未觀察到模型因此偏向生成更長的回應。
此外,表格數據揭示了其他訓練數據集和技術對模型性能的影響。通過這些實驗,研究人員能夠更深入地了解模型各個組件的作用和相互關係。
研究人員還探討了「計劃增強輸出數據」對模型的影響。他們嘗試在生成內容前,先讓模型輸出寫作計劃,希望藉此提升長文本任務的表現。然而,實驗結果顯示,這種方法並未帶來顯著的性能提升。研究人員推測,這可能是因為模型在訓練過程中已經內化了類似的「思考鏈」過程,因此不需要明確輸出寫作計劃。
研究人員還探討了使用「指令回譯」來合成長輸出訓練數據的效果。這種方法雖然在過去的研究中常用,但在本實驗中未能有效提升模型生成長文本的能力。分析原因,可能是因為所選取的長文本品質不佳,以及回譯產生的指令與真實用戶指令存在差異。這提示未來研究可著重於收集更高質量的長文本,並生成更貼近真實用戶需求的指令,以進一步提升模型在長文本生成方面的表現。
**較大輸入窗口的 LLM :**如果將大型語言模型(LLM)比作人類大腦,那麼上下文窗口就相當於其工作記憶。一個高級智能體需要足夠的工作記憶來完成各種複雜的任務。同樣,一個優秀的LLM也需要足夠長的上下文長度來替代人類完成這些任務。
目前,有一系列研究探索如何擴展LLM的上下文窗口長度以支持長上下文任務,從而使LLM「看到更多內容並理解更長的內容」。這些方法包括零樣本擴展方法(Han et al., 2023; Xiao et al., 2023; Zhang et al., 2024a; Jin et al., 2024; An et al., 2024)以及通過在更長的序列上微調模型來實現更長記憶的方法(Chen et al., 2023a; Peng et al., 2023; Xiong et al., 2024; Chen et al., 2023b; Bai et al., 2024a; Fu et al., 2024)。
對於一個擁有足夠工作記憶的智能體來說,它們不僅應該能夠理解更長的輸入,還應該具備生成更長輸出的能力。然而,在當前的長上下文LLM中,我們發現它們的最大輸出長度(約2000字)遠遠短於它們可以接受的最大上下文長度(超過100000字)。為了彌合這一差距,我們的工作研究如何擴展長上下文LLM的最大輸出長度。
對齊LLM以遵循指令中的限制: 由於研究者的方法主要依賴於對齊大型語言模型,使其遵循用戶指令並提供更長、更豐富的輸出,他們調查了關於大型語言模型對齊的研究。先前的研究表明,通過對齊訓練,包括監督式微調和從人類反饋中進行強化學習(Ouyang et al., 2022; Achiam et al., 2023),可以教導大型語言模型優先處理特權指令(Wallace et al., 2024)、遵循長度限制(Yuan et al., 2024),以及遵循多重限制指令(He et al., 2024; Sun et al., 2024; Pham et al., 2024)。我們的對齊方法專門解決了一個尚未被充分探索的問題:如何對齊大型語言模型,使其滿足要求超長輸出的用戶指令。
在這項工作中,他們發現了當前大型語言模型(LLMs)存在2000字的生成限制,並建議通過在對齊過程中添加長輸出數據來增加它們的輸出窗口大小。為了自動構建長輸出數據,他們開發了AgentWrite,這是一個基於代理的管道,它使用現成的大型語言模型來創建擴展的、連貫的輸出。通過他們構建的LongWriter-6k,他們成功地將當前大型語言模型的輸出窗口大小擴展到10000字以上。對訓練數據的廣泛消融研究證明了他們的方法的有效性。
對於未來的研究,他們建議以下三個方向:
有興趣的可以看下他們寫的code,感覺那才是主要的,論文只是開胃的。

