關於 RAG:Day 23: 什麼是 RAG?
其他可參考的資料:
其他大大的 RAG資料庫資料
RAG 綜述 簡中版 Retrieval-Augmented Generation for Large Language Models: A Survey
今天會理解完一個能根據特定的開源項目實作,明天會在此基礎上進行其他功能的實作:
Understanding And Querying Code: A RAG powered approach 原網址
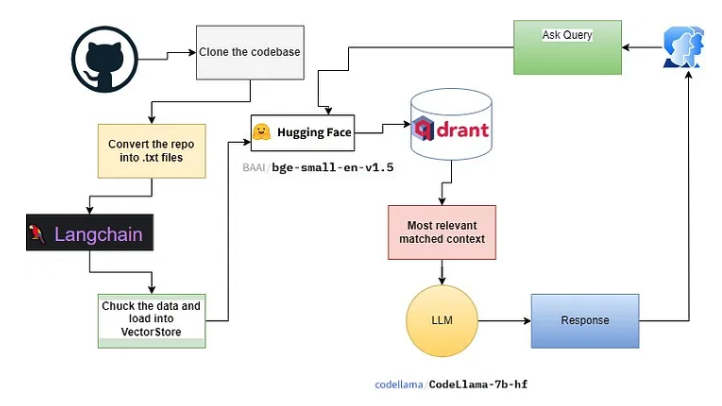
簡單來說就是把程式碼當成一般文字分析,並使用 codellm 運作,由於原網址 load 的程式碼大概只有一頁,所以其實讓我有點存疑 codellm 生成的真實性,不過後續運作的時候確實有抓到原項目裡的一些內容,只能說項目的真實性大概是一半上下左右,真的要能實際上使用大概還要再好好的調整。
我這邊大概根據他的程式碼進行分析
好的,讓我們來分析一下你提供的程式碼,看看它如何實現一個 RAG + Agent 系統,以及其中的一些關鍵點和潛在改進方向。
程式碼功能拆解
環境準備
langchain、transformers、accelerate、sentence-transformers、qdrant-client、langchainhub 和 gradio。chat-with-websites 倉庫:這可能是用於從網站提取內容的工具,但目前程式碼中似乎沒有直接使用到。文件轉換與加載
convert_files_to_txt:將指定目錄下的檔案轉換為 .txt 格式,以便後續處理。DirectoryLoader:從指定目錄加載 .txt 檔案。RecursiveCharacterTextSplitter:將加載的文本分割成適當大小的 chunks,以便 embedding 模型處理。Embedding 與向量存儲
HuggingFaceBgeEmbeddings:使用 HuggingFace 的 BGE 模型生成 embedding。Qdrant:一個向量數據庫,用於存儲和檢索 embedding。語言模型
HuggingFacePipeline:使用 HuggingFace 的 CodeLlama-7b-hf 模型作為 LLM。RAG 查詢
qdrant.similarity_search:根據查詢,在 Qdrant 向量數據庫中搜索最相似的程式碼片段。pretty_print_docs:美化輸出檢索到的文件信息和內容。Prompt 模板和鏈式調用
hub.pull("rlm/rag-prompt"):從 LangChain Hub 拉取一個 RAG prompt 模板。chain = prompt | gpu_llm | StrOutputParser():構建一個鏈式調用,將 prompt 模板、LLM 和輸出解析器串聯起來。RetrievalQA
RetrievalQA.from_chain_type:使用 "stuff" 鏈類型創建一個 RetrievalQA 對象,用於整合檢索和生成。Gradio 界面
load_documents:加載文件並構建 Qdrant 向量存儲。retrive_response:檢索並生成回答。gr.Interface:創建兩個 Gradio 界面,一個用於加載文件,一個用於提問。gr.TabbedInterface:將兩個界面組合成一個帶有標籤的界面。改進建議
總結
這段程式碼提供了一個基本的 RAG + Agent 系統的實現,具有一定的參考價值。透過進一步的改進和優化,可以使其更加強大和實用。
請注意: 由於沒有提供 codebase 檔案夾的具體內容,無法對程式碼的實際效果進行評估。
我想可能架構不改之外,可能用的embedding ,model 跟讀取的項目跟設定都要整個改掉,感覺才比較有可用性。
不過原網誌大概算是證明了這個方法是可能可行的就是了。

