在過去的幾天,我們陸續介紹了各種前處理的技術,並實際應用在資訊檢索的主題裡面。接下來,我們要嘗試把非結構化的文字轉成數值型態的向量,讓電腦學會每一個單詞代表的意思,朝著語言模型的方向前進。
我們人類在日常生活中所使用的自然語言長這樣:
我喜歡看電影。
而電腦可以處理的資料長這樣:
[[0.453, 0.815, 0.655, …], [0.894, 0.286, 0.546, …], …]
因此,如果要讓電腦看懂人類語言的話,最直觀的想法就是向量化 ( Vectorization ),接下來會簡單聊聊幾種將文字向量化的方式,並在接下來的篇章詳細介紹。
單熱編碼 ( One-hot Encoding ) 可以說是把文字轉換成向量最簡單最無腦的方式,它的概念是把文本中所有相異的單詞整理成一個詞彙表 ( Volcabulary ),然後對於每個單詞,把它在詞彙表中的位置設為 1,其他位置設為 0。
我們舉一個例子來說:
I like to watch movies on the weekend.
這個句子如果按照 One-hot Encoding 的方式編碼,會像這個方式呈現:
當我們把整個詞彙表建立好的時候,假設有一個新的句子要被編碼,那麼就可以很快速的從詞彙表中把對應的單詞提出來做轉換。
然而 One Hot Encoding 的缺點也不少,比方說它的儲存方式太浪費空間而且不必要,隨著詞彙表規模的成長,這個缺點會更明顯。
此外,它也無法捕捉單詞之間語意的關係。One Hot Encoding 僅僅是完成了將文字轉化為向量的任務而已,電腦其實並不理解這個單詞代表的含意,比方說它不能判斷出 [’cat’, ‘dog’] 和 [’cat’, ‘tree’] 哪一組單詞的語意更接近。
詞袋 ( Bag of Word, BoW ) 的概念和 One hot encoding 概念有點像,都是通過建立詞彙表的方式來編碼。但兩者不一樣的地方在於,前者是將文本編碼成向量,而後者是把單詞編碼成向量。
舉例來說,我們會將編碼出來的結果像這樣表示:
至於中間的轉換過程就是明天要討論的主題了,我們會一併介紹如何實作 Bow of Word。
BoW 的缺陷和 One hot encoding 一樣,它也有稀疏向量造成空間浪費的問題,也同樣無法捕捉單詞之間的關係。
TF-IDF 前幾天在聊資訊檢索的內容中提到過了,有興趣可以回去翻翻哦!
它的做法是利用計算單詞在文檔中的出現頻率 ( Term Frequency ) 以及這個單詞有出現的文檔數 ( Document Frequency ),來決定這個單詞對這篇文檔的重要程度,所以也算是將文本轉化為數值表達的方式,不過它的應用更偏向於資訊檢索,在這裡就沒有更多的討論。
好的,在介紹完這三種把文字轉換為數值型態的方式後,我們可以發現,他們共同的問題幾乎都是一樣的,那麼要如何解決呢?
詞嵌入 ( Word Embedding ) 就是一個很好的解決辦法,它的概念是將單詞映射到一個連續的向量空間中,讓語意相似的單詞在向量空間中的分布更靠近。
最一開始,我們提出了一個想法:在一篇文章中,是不是越常出現在一起,用法越相似的兩個單詞,他們的關係越緊密?
舉個例子來說:
我喜歡吃陽春麵
我喜歡吃炒飯
我喜歡吃水餃
這裡的 陽春麵、炒飯、水餃 都是食物,比較常出現在一起,而根據上下文,他們前面通常會接 吃 這個動詞,因此,語意上會比 我喜歡看電影 的 電影 來的更相近。
這個就是分布假說 ( Distributional Hypothesis ) 想要表達的意思,而後又演變出了許多根據上下文來決定單詞語意的作法,這就是 Word Embedding 的由來。
我們可以從這張圖來理解 Word Embedding 的做法: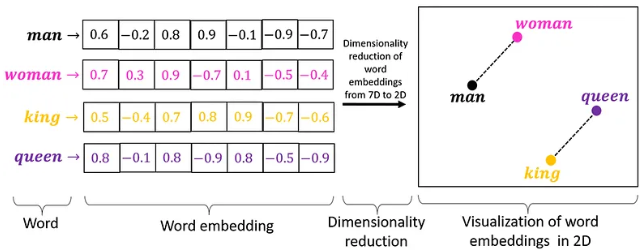
其中,比較具有代表性的就是在 2013 年提出來的 Word2Vec, 它包含了 CBOW 和 Skip-Gram 兩種訓練詞向量 ( Word Vector ) 的方法,這也是我們之後要介紹的主題。
關於詞嵌入的研究到這裡還遠遠沒有結束,像 Word2Vec 這種編碼方式我們把它叫做 Static Embedding,因為它僅僅是將單詞轉換為固定的詞向量,但無法更加複雜的語意表達,舉個例子來說:
為了解決順序或一字多義造成語意不同的問題,因此後來又發展出 Contextualized Embedding 的做法,比方說應用 RNN 和 LSTM 技術的 ELMo,或是應用了 Self-Attention 技術而在 NLP 領域中鼎鼎大名的 Transformer 架構。
就是在這些基礎之下,大型語言模型 ( Large Language Model, LLM ) 的雛形逐漸顯露出來,變成像今天這樣的盛況。
今天這一篇算是把之後想要介紹的主題都先確定了下來,可以的話我就把它慢慢補完吧!
推薦文章


 iThome鐵人賽
iThome鐵人賽