我規劃的下一個篇章是如何將非結構化的文字轉換成向量的形式,讓電腦可以處理,不過在這之前,我想要先來聊聊貝式分類器是如何應用在 NLP 任務上的。
根據我有點模糊的印象,貝式定理在高中和大學的時候有接觸過,剛好可以趁著這次機會來複習一下。
大家應該對條件機率 ( Conditaionl Probability ) 不陌生吧,它的定義是 ”事件 A 在事件 B 發生的條件下發生的機率”,我們可以用這個公式來表達: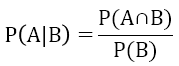
根據條件機率,我們可以推導出貝式定理的公式: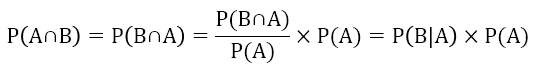
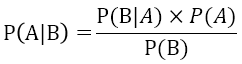
這個就是貝式定理,其中:
它的概念就像是我們如果要判斷今天出門會不會遇到塞車,通常會先考量尖峰時間、有沒有經過塞車路段、是不是連假等因素,而這些因素正是由過去觀察他們和發生塞車之間的機率來得知的。
那麼,我們要如何把貝式定理的概念用在 NLP 上面呢?
單純貝式分類器在 NLP 領域中通常用來解決文本分類的問題,假設我們收到了下面這幾條產品評論:
| Comment | label |
|---|---|
| The quality is fantastic and I am thoroughly impressed | Positive |
| It is the most effective product I have used | Positive |
| I am very impressed with the fantastic performance of this item | Positive |
| The product is poorly designed which is really disappointing | Negative |
| I am very disappointed and would not recommend it | Negative |
這個小小的資料集包含了評論和對應的分類標籤,我們希望可以通過這個資料集去訓練一個模型,當它收到新的評論的時候可以判斷這則評論是正面的還是負面的。
首先,通過貝式定理可以計算出: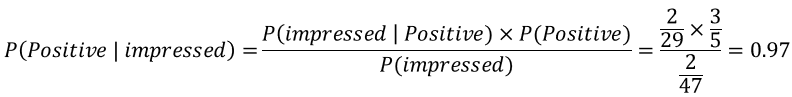
我們去計算了在 positive 文檔出現的情況下,該文檔包含單詞 impressed 的機率,以及它們各自出現的機率,進而推論出當某一篇未知文檔包含單詞 impressed 的時候,它屬於正面評論的機率很大。
如果我們換一個比較中性的單詞 product 來計算的話: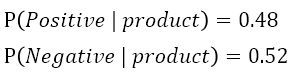
這個結果顯示出 product 不太適合用來判斷正面或負面評論。
而 Naive Bayes 就是在這個計算方式的基礎下繼續延伸,那麼就開始一步步推導公式吧!
一個句子可以拆分出很多單詞,每個單詞都有它對某些類別的偏重,如果要完全判斷這個句子屬於哪一個類別的話,可以拓展成: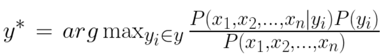
其中 X_i 代表這個句子中所有的單詞,argmax 是 “argument maximun”,它出現在式子前面的意思是從所有的類別中找出機率最大的那一個,所求出來的 y^* 就是這個句子最有可能的類別。
然後,又因為所有文檔固定不變的情況下,單詞出現的機率也是固定的,所以分母的部分可以忽略掉 ( 等同於正比的關係 ),整個式子變成: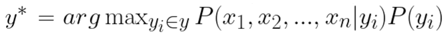
此外,我們假設每一個單詞出現的機率彼此之間是獨立的,因此他們都出現的機率可以用乘法來表示: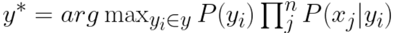
然而,這會出現一個尷尬的問題,因為如果所有單詞出現的機率都要相乘的話,數字會變的超級小,於是我們加上 log,讓它從連乘變連加: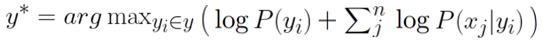
公式推導到這裡大致告一段落,還有剩下一些小細節需要調整,像是為了避免單詞出現個數為零而做的拉普拉斯修正,我們就先不深入談下去。
最後,我們來做個整理吧!Naive Bayes 其實並不難理解,因為它是從條件機率出發,一路推導到最終的公式,它的計算方便快速,適合用在分類任務上,比方說垃圾郵件分類或情緒分類。
不過它的缺點也很明顯,剛剛在推導公式的時候也有提到,它的計算方式必須建立在單詞之間的出現機率互相獨立,然而這在現實世界中並不成立,因此它只能做為一個基本的模型,進行簡單的分類任務。
推薦文章
PS : 今天還是沒搞懂公式要怎麼在這裡打出來...


 iThome鐵人賽
iThome鐵人賽