上一篇文章我們了解了資料集的結構和如何設計,也了解了 FineTune 用到的 LoRA 的技術 (背後的數學和理論就不提了)。還有看了很多不同的微調框架,也有提到 OpenAI 和 Mistral 有自己家的 FineTune,還有台智雲的 No-Code 微調,所以今天就一一來程式實作吧!
昨天只有提到這個資料集被廣泛拿來作為微調模型的資料,那我們要客製化自己的資料集,就必須跟著 Alpaca 的結構來建立資料集。
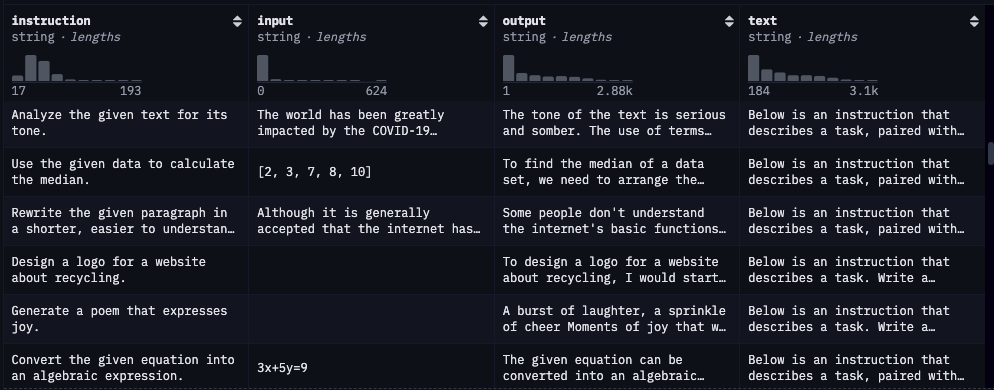
instruction:instruction 這個欄位主要就是放入你要輸入給模型的內容,這個內容可能是一個問題、可能是一個任務,算是 user 最主要輸入內容的部分。input:input 這個欄位可以是空值,要與 instruction 做搭配。我自己的認知是,如果今天 instruction 是個問題,那麼通常 input 就會是空的;但是如果今天 instruction 是一個任務,那麼 input 就會有輸入,但其實也沒有一定,還是要回到本身任務來依據狀況適當填入。
output:output 就很簡單是希望 AI 回傳的內容。text:就是在 instruction 前面會再給一串 prompt,通常是要 AI 根據 instruction 指令來完成特定任務,然後把 instruction、input、output 連在一起。所以在微調模型完,要測試的時候可以使用 text 來看看微調的成效如何。這邊要實作的是昨天有提到的三個框架,分別是 Axolotl、Unsloth、LlamaFactory。那我的執行環境都會是 Colab,只需要免費的 T4 GPU 即可運行,因為他們都只支援 CUDA (可能 Mac 可以是我不會操作)。然後這邊的數據集都會使用 Alpaca 資料或者遵循他的結構來客製化資料。
Axolotl 在他們 GitHub 有提供 Colab 程式碼,但是我自己測試什麼都沒改是沒辦法跑成功,所以經過了一些修正可以順利執行,但是使用 gradio 測試的部分我是不行,所以我是將模型上傳到 HuggingFace 再來測試。
!git clone -q https://github.com/OpenAccess-AI-Collective/axolotl
%cd axolotl
!pip install -qqq packaging huggingface_hub --progress-bar off
!pip install -qqq -e '.[flash-attn,deepspeed]' --progress-bar off
!pip install mlflow
import yaml
yaml_string = """
base_model: TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T
model_type: LlamaForCausalLM
tokenizer_type: LlamaTokenizer
is_llama_derived_model: true
load_in_8bit: false
load_in_4bit: true
strict: false
datasets:
- path: mhenrichsen/alpaca_2k_test
type: alpaca
dataset_prepared_path:
val_set_size: 0.05
output_dir: ./qlora-out
adapter: qlora
lora_model_dir:
sequence_len: 1096
sample_packing: true
pad_to_sequence_len: true
lora_r: 32
lora_alpha: 16
lora_dropout: 0.05
lora_target_modules:
lora_target_linear: true
lora_fan_in_fan_out:
wandb_project:
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
mlflow_experiment_name: colab-example
gradient_accumulation_steps: 1
micro_batch_size: 1
num_epochs: 4
max_steps: 20
optimizer: paged_adamw_32bit
lr_scheduler: cosine
learning_rate: 0.0002
train_on_inputs: false
group_by_length: false
bf16: false
fp16: true
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: false
warmup_steps: 10
evals_per_epoch:
saves_per_epoch:
debug:
deepspeed:
weight_decay: 0.0
fsdp:
fsdp_config:
special_tokens:
"""
# 將以上 yaml 檔內容放入 Python 變數
yaml_dict = yaml.safe_load(yaml_string)
# 指定 yaml 檔名詞
yaml_file = 'config.yaml'
# 寫入 ymal 檔
with open(yaml_file, 'w') as file:
yaml.dump(yaml_dict, file)
!accelerate launch -m axolotl.cli.train config.yaml
!accelerate launch -m axolotl.cli.inference config.yaml --qlora_model_dir="./qlora-out" --gradio
!python3 -m axolotl.cli.merge_lora config.yaml --lora_model_dir="./qlora-out"
from huggingface_hub import HfApi
from google.colab import userdata
new_model = "Your Model"
api = HfApi(token="hf_token")
# Upload merge folder
api.create_repo(
repo_id=new_model,
repo_type="model",
exist_ok=True,
)
api.upload_folder(
repo_id=new_model,
folder_path="qlora-out/merged",
)
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Your Model"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
device = torch.device("cuda")
model.to(device)
input_text = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction: What is the capital of France?
### Input:
### Response:"""
input_ids = tokenizer.encode(input_text, return_tensors="pt").to(device)
output_ids = model.generate(input_ids, max_length=100)
output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print(output_text)

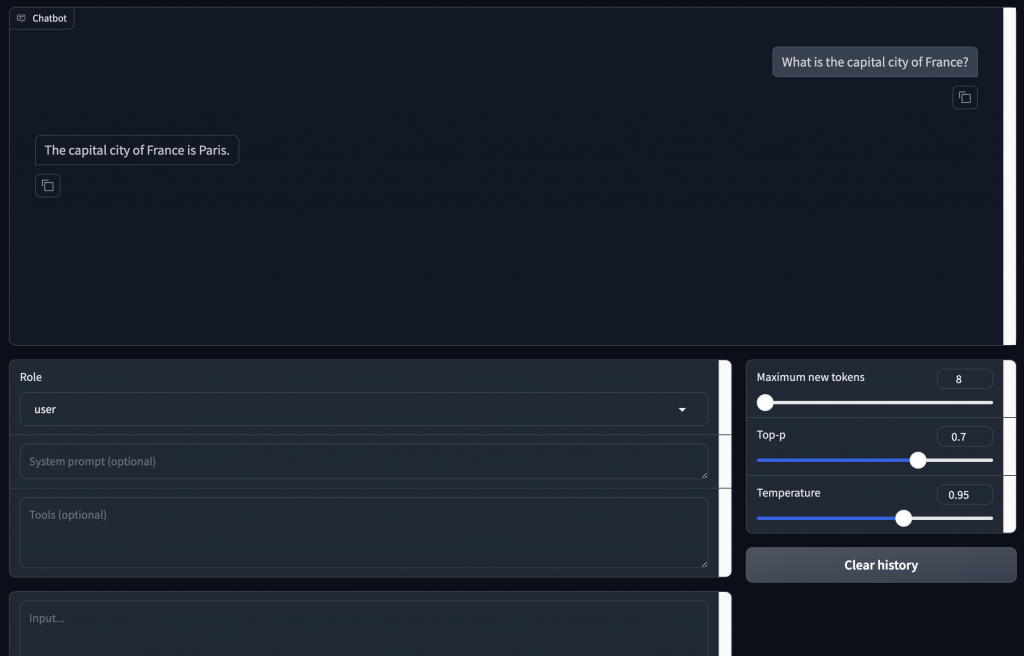
程式碼結果探討 🧐:
LLaMA-Factory 在他們 GitHub 有提供 Colab 程式碼,但我自己覺得是相對友善的,因為他的 Fine Tune 不需要寫程式。他的程式碼就是一路執行下去直到開啟 gradio 的頁面,就可以開始 Fine Tune 了。
4-bit 或 8-bit 量化,可以減少模型的內存佔用和推理時間,但可能會影響模型性能。bitsandbytes 是用來優化模型的內存使用和計算效率,可以大幅減少模型參數的佔用空間,特別適合在資源有限的情況下進行訓練。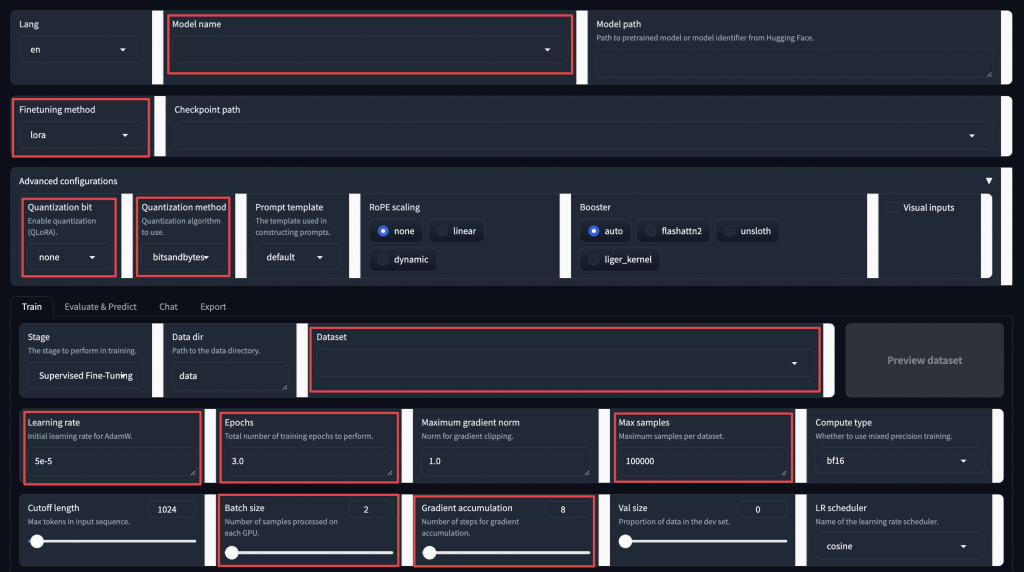
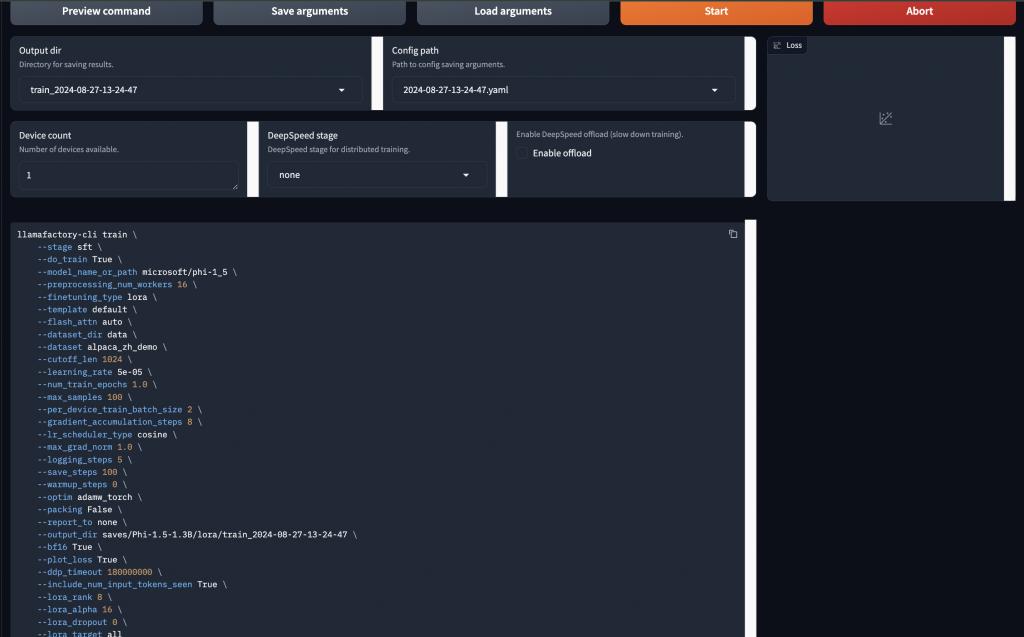
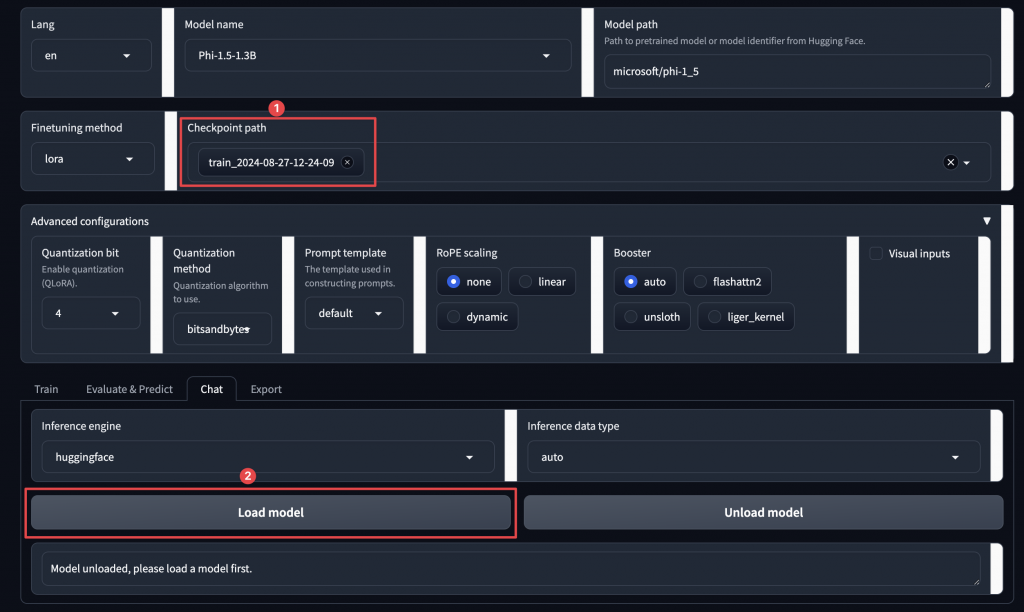
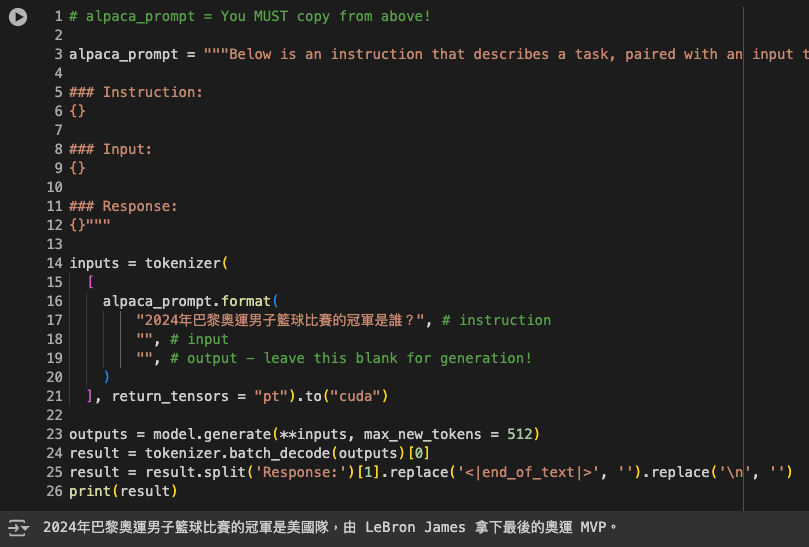
再來就要分享我覺得是目前最好用的 Colab 微調框架,而且他真的速度很快,微調效果也好,就來實作看看!
[
{
"instruction": "2024年巴黎奧運男子100米短跑的金牌得主是誰?",
"input": "",
"output": "2024年巴黎奧運男子100米短跑的金牌得主是美國的 Noah Lyles。"
},
{
"instruction": "2024年巴黎奧運女子舉重59公斤級,中華隊郭婞淳成績?",
"input": "",
"output": "2024年巴黎奧運女子舉重59公斤級的台灣的郭婞淳傷癒復出征戰奧運奪下銅牌。"
},
{
"instruction": "2024年巴黎奧運羽毛球男子單打的金牌得主是誰?",
"input": "",
"output": "2024年巴黎奧運羽毛球男子單打的金牌得主是丹麥的維克托·阿薩爾森(Viktor Axelsen)。"
},
{
"instruction": "台灣在2024年巴黎奧運拳擊女子57公斤比賽中獲得了什麼獎牌?",
"input": "",
"output": "台灣在2024年巴黎奧運拳擊女子57公斤比賽中林郁婷獲得了金牌。"
},
{
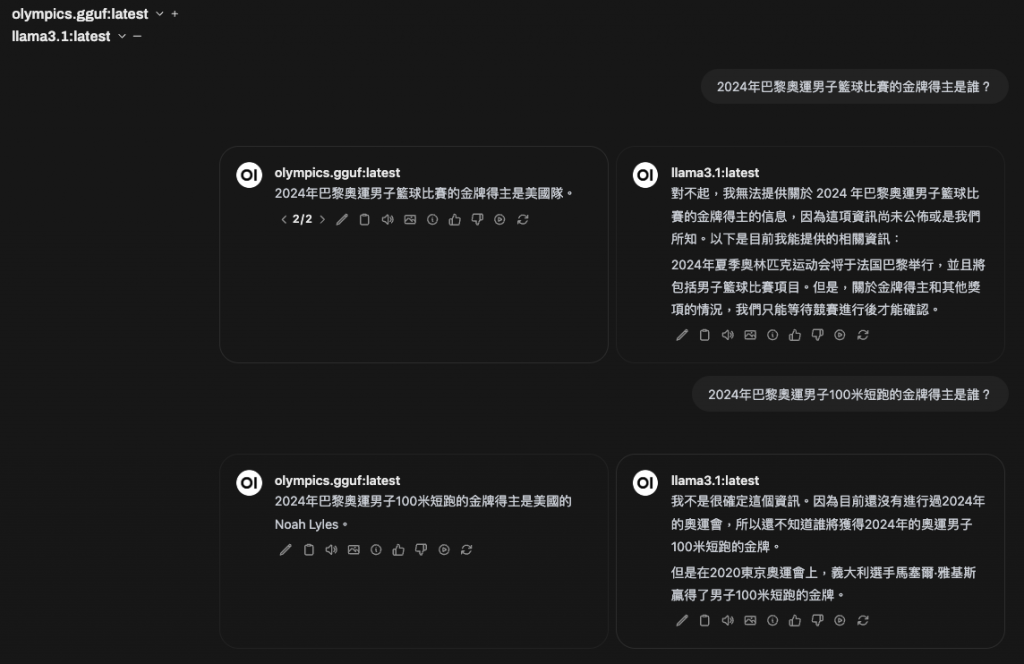
"instruction": "2024年巴黎奧運男子籃球比賽的金牌得主是誰?",
"input": "",
"output": "2024年巴黎奧運男子籃球比賽的金牌得主是美國隊,由 LeBron James 拿下最後的奧運 MVP。"
},
{
"instruction": "台灣在2024年巴黎奧運羽毛球男子雙打比賽中獲得了什麼獎牌?",
"input": "",
"output": "台灣在2024年巴黎奧運羽毛球男子雙打比賽中獲得了金牌,由王齊麟和李洋搭檔獲得。"
}
]
# !pip install datasets
# !pip install huggingface_hub
from huggingface_hub import login
from datasets import Dataset
login()
import json
with open("ithome_unsloth.json", "r") as f:
data = json.load(f)
formatted_data = {
"instruction": [item['instruction'] for item in data],
"input": [item['input'] for item in data],
"output": [item['output'] for item in data]
}
dataset = Dataset.from_dict(formatted_data)
dataset.push_to_hub("SeanNChen/ithome-2024-alpaca")


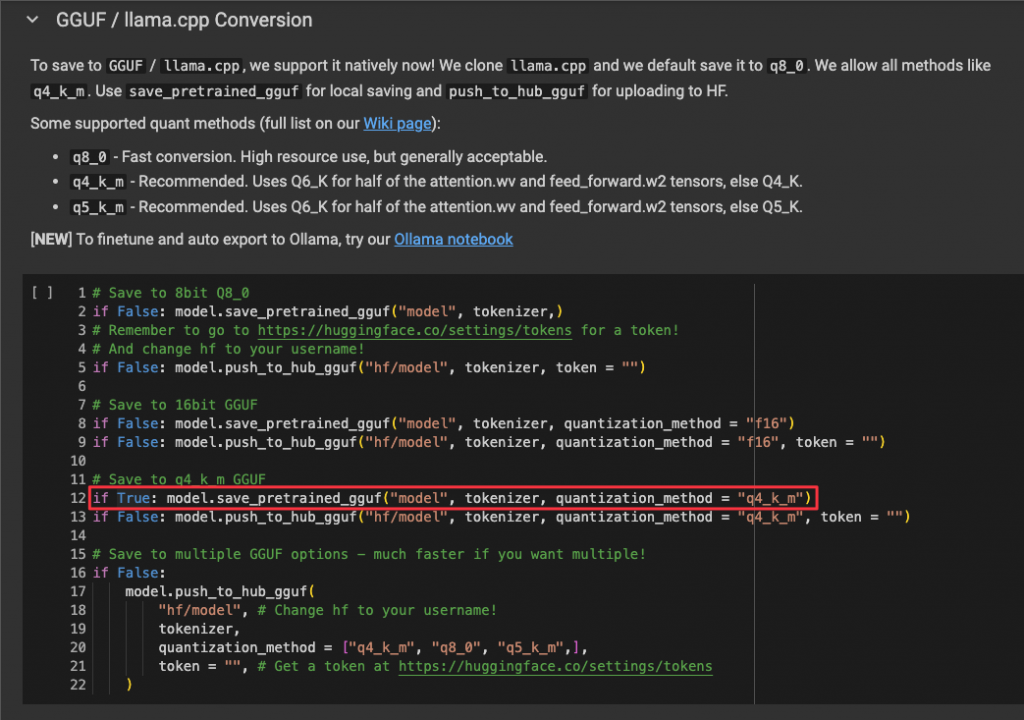
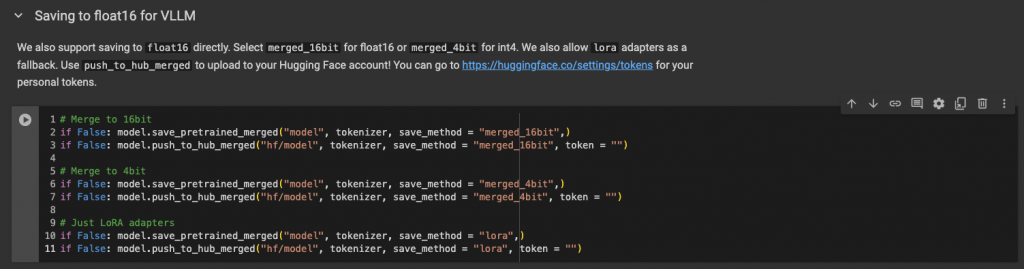
from google.colab import drive
drive.mount('/content/drive')
import shutil
local = '/content/model-unsloth.Q4_K_M.gguf'
google_drive = '/content/drive/My Drive/model-unsloth.Q4_K_M.gguf'
shutil.copy(local, google_drive)
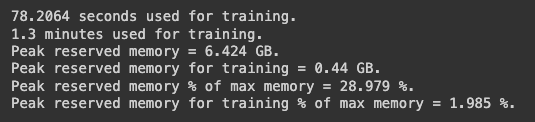
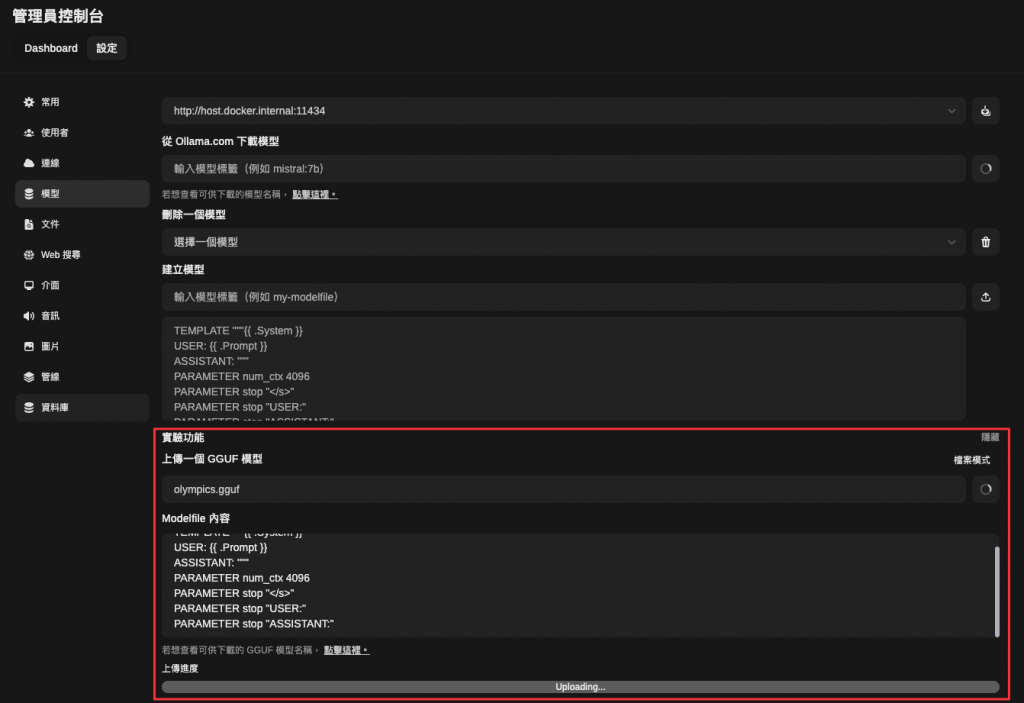
在 Mistral 他們 GitHub 有提供 Colab 程式碼,他們的資料集就不是使用 Alpaca 的資料型態,但他們程式碼中有展示他們範例的資料型態,我們在用 LangChain 的 ChatPromptTemplate 很像。那我自己是有換成自己的資料集測試,結果是一路都可以很順的執行,模型訓練的速度也很快,但是在最後要測試模型訓練效果的時候,他顯示爆 RAM 了,所以沒辦法使用,因此沒有測試結果。如果大家有用 Mistral 自家的 FineTune 程式訓練測試成功 Mistral 模型的的話,歡迎跟我分享喔~
我目前是還沒使用過 OpenAI 的 FineTune,但作為目前最強 AI,如果能 FineTune 那應該效果不會太差。在 OpenAI 官網 有很明確的介紹了如何 FineTune OpenAI 的模型,也有表示要使用哪種資料型態。我同事有 FineTune 過 gpt-3.5,但我們推測是樣本數太少導致學習效果不好。如果大家有 FineTune 過 OpenAI 的話歡迎跟我分享喔~
我們今天實作了目前開源的三個框架,其實各有好壞,或許有本機 GPU 的人不會選擇 Unsloth 架構。但我覺得在資源有限的情況下,Unsloth 是最適合初學者也最省時的。微調 LLM 是一個既有挑戰又充滿可能性的過程。選擇合適的工具、設計好資料集,並適時進行實驗和調整,能夠顯著提升模型的應用效果。
最近被通知入伍時間了,要準備去當兵了~看來離社畜人生又更進了一步😆


 iThome鐵人賽
iThome鐵人賽