前情提要: 昨天分享了最近我關注的github,每個領域都有,可以找自己有興趣的研究研究。
今天剛好看到這個 https://github.com/Lightning-AI/LitServe ,跟我們之前講的fastapi + lightning一樣,他把它包得更好,效率更高,讓我們一起來研究看看吧。
pip install litserve
# server.py
import litserve as ls
# (STEP 1) - DEFINE THE API (compound AI system)
class SimpleLitAPI(ls.LitAPI):
def setup(self, device):
# setup is called once at startup. Build a compound AI system (1+ models), connect DBs, load data, etc...
self.model1 = lambda x: x**2
self.model2 = lambda x: x**3
def decode_request(self, request):
# Convert the request payload to model input.
return request["input"]
def predict(self, x):
# Easily build compound systems. Run inference and return the output.
squared = self.model1(x)
cubed = self.model2(x)
output = squared + cubed
return {"output": output}
def encode_response(self, output):
# Convert the model output to a response payload.
return {"output": output}
# (STEP 2) - START THE SERVER
if __name__ == "__main__":
# scale with advanced features (batching, GPUs, etc...)
server = ls.LitServer(SimpleLitAPI(), accelerator="auto", max_batch_size=1)
server.run(port=8000)
當run起來會長這樣,此時在相同目錄下就會自動多出一個client.py,讓你用於測試
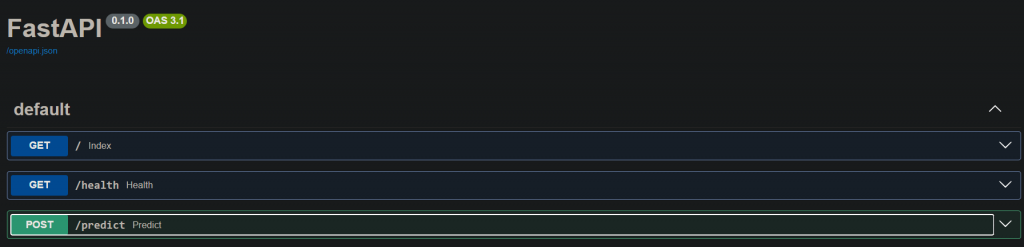
一樣在網址後面多/docs,會出現這個測試頁面,我想說/predict,是不是對應def predict,不過我多新增其他的,他似乎不會讀到,所以跟lightning一樣是固定名稱的。
[8/29更新]
參考: https://lightning.ai/docs/litserve/api-reference/litserver
在這邊可以決定你使用的URL path
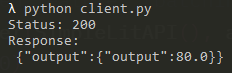
import requests
response = requests.post("http://127.0.0.1:8000/predict", json={"input": 4.0})
print(f"Status: {response.status_code}\nResponse:\n {response.text}")
雖然還沒更深入研究,不過流程大致上如下:
[8/29更新] 這裡補上網址:
https://lightning.ai/docs/litserve/api-reference/litapi
https://lightning.ai/docs/litserve/home/benchmarks#text-classification
分成兩種方式處理: Not batched, Batched
在大量被連線的情況下選用Batched,可以更好的增加效能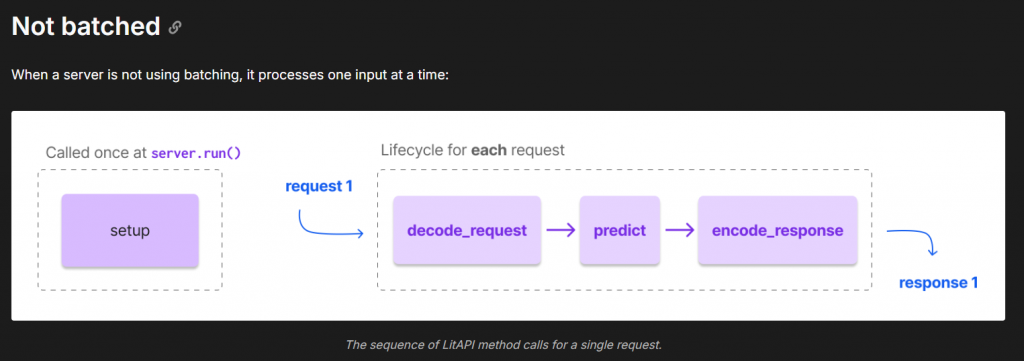
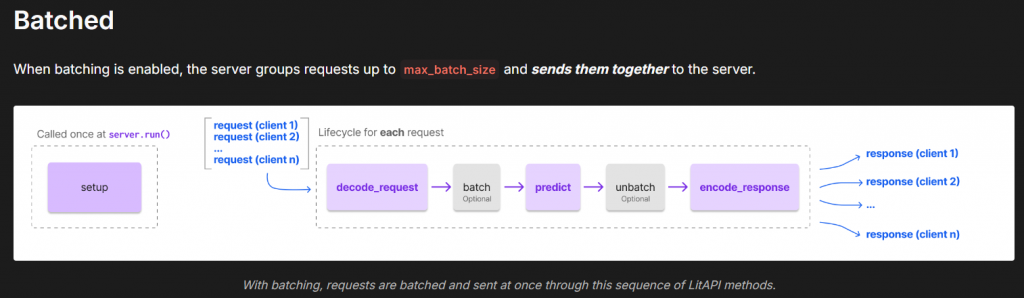
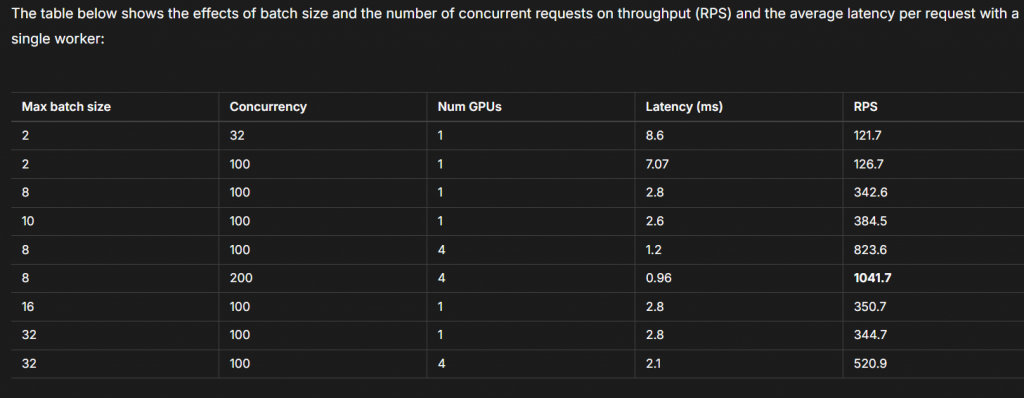
程式看起來確實精簡很多,不過需要去熟悉一下,以及看更多範例去實作,不過在我的筆電上跑要斷掉時會卡死,不確定在linux會不會,感覺還要研究。
今天就更新到這囉~~ 明天繼續把研究的結果跟大家分享。


 iThome鐵人賽
iThome鐵人賽