今天繼續來挑戰怎麼理解 Transformer 架構吧!
Attention 的概念其實之前就有了,不過在 2017 年發表的論文《Attention Is All You Need》中,介紹了自注意力機制如何應用在 Transformer 的模型,並在翻譯等任務上有了出色的表現,那什麼是自注意力機制呢?
還記得之前提過的 Word2Vec 嗎?我們談到,它存在的一個缺陷是只為每個單詞生成了一個固定的向量表示,如果在不同情境之下這個單詞有了不同的含意,它還是只能用同一個向量,這會導致模型對整篇文章的理解產生一點偏差。
而 Attention 很厲害的地方在於,它會在轉換成向量的時候把周邊單詞的因素也考量進來,如此一來,即便是同樣的單詞在不同情境下也會有不一樣的向量表示,就能夠更精確的理解語意。
我們可以從這張圖來去理解自注意力機制在做的事情:
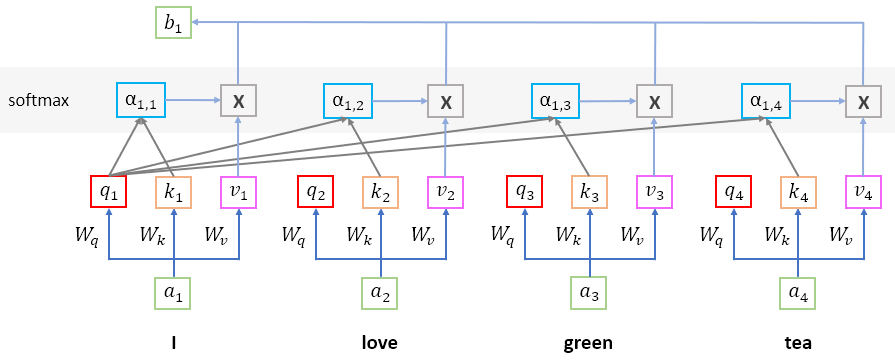
假設在文字被 embedding 之後,input 的 sequence 中有這四個向量,分別用 a1、a2、a3、a4 表示,首先來看 a1 的部分,我們在之前的神經網路訓練過程中獲得了 Wq、Wk、Wv 三個權重矩陣,將他們分別乘上 a1,可以獲得 q1、k1、v1 這三個向量。
根據我的理解,這三個向量代表的含意有點像是:
PS : 這個部分如果有人知道比較詳細的話,我也希望可以多了解一下 ~
因此,注意力其實就是根據其它單詞對這個單詞所提供的一些資訊,去決定他們對自己最終輸出的影響程度。
那麼就繼續來計算注意力吧!
接著,我們要去計算在這個 sequence 當中其他單詞對 a1 的重要程度,所以會將 q1 分別與 k1、k2 和 k3 內積,最後獲得的分數 α 我們把它叫做 attention score,在繼續下一個步驟之前,會先對 α 做 softmax,獲得 α'。
自注意力相較於注意力多做的事情就是,它除了關注其它詞,也希望可以關注對自身不同部分的訊息,也就是 k 的部分。
接下來,將每一個單詞對 a1 的重要程度 α' 乘上各自對應的值 v,計算出來的結果再全部加總,獲得最終的輸出 b1,也就是說,如果前一步計算 attention score 的時候某一個單詞對 a1 的重要程度比較大,最終它就會對 b1 造成較大的影響。
最後,我們對所有的 a 都做一遍同樣的事情,可以獲得 b1、b2、b3、b4 這四個向量,這就是自注意力機制在做的事情。
接著要來解釋為什麼這個流程可以平行運算,我們把所有的 a 合起來變成一個矩陣 I,直接做矩陣運算就會獲得 Q = Wq * I、K = Wk * I、V = Wv * I,接著要對 Q 和 K 內積,一樣是矩陣運算得到 α = Q * (K ^ T),T 是轉置矩陣的意思,對 α 做完 softmax 之後,最後再乘上剛剛算出來的矩陣 V 就可以得到由全部 b 組成的矩陣 O 了。
也就是說,整個計算注意力的過程都只涉及線性變換,也沒有任何的循環流程,因此可以整個 sequence 同時進行。
這就是原始論文中提到計算 attention 的公式,其中 dk 的作用是要抑制因為做內積而導致數值規模太大的問題:
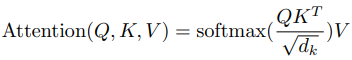
而論文中提到的多頭自注意力 ( Multi-Head Self Attention ) 機制則是讓模型可以把注意力放在不同字上,而不是原先側重於其中一個字,它的做法是把權重矩陣 Wq、Wk、Wv 分成多個頭,各自計算完之後再組合起來。
這樣一來,我們就把最重要的部分講完了,回到 Transformer 的架構圖上:
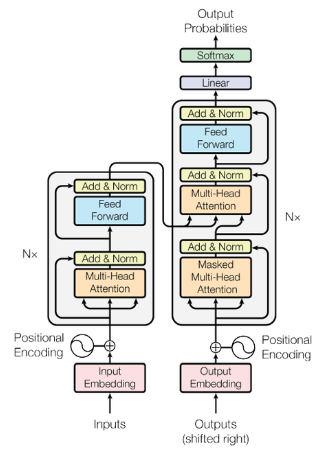
前面這些步驟都是屬於線性變換,而當我們把 Multi-Head Attention 計算完之後會進入前饋神經網路 ( Feed Forward Neural Network, FFNN ),也就是深度學習的部分,這一整個區塊會執行 N 次,執行完之後就會輸出 Encoding 的結果。
而在 Decoding 的部分,會做 Masked Multi-Head Attention 的原因在於,我們在輸出前面部分的時候並不知道後面長什麼樣子,自然就沒辦法進行關注,只有在輸出後面部分的時候,才能夠去計算它和前面的注意力。整個 Decoder 也是執行 N 次。
整個 Transformer 的架構大致就是這樣,裡面還有無數的細節可以拿出來討論,這也是我之後要繼續努力的目標。
而也因為這個架構本身支持並行運算,只要硬體跟得上就可以把規模放大,也就是把 N 執行上百次,讓它能夠對自然語言的理解更好,可以處理更長的文本。
現在有很多的大型語言模型 ( Large Language Model ) 就是在這個架構的基礎之上做了一些調整,然後疊超級多層,累積幾百億個參數之後就發現模型好像產生了頓悟現象,各方面的表現都變的超強,這也是 LLM 能夠獲得成功的原因之一。
明天想要聊聊我對大型語言模型的基本認識,以及現階段的我可以怎麼去應用它。
推薦文章
PS : Attention 這張圖是我在看了李宏毅教授的影片後自己試著畫畫看的,花了好幾個小時才全部理解完 ……


 iThome鐵人賽
iThome鐵人賽