2017 年 Transformer 的出現讓 NLP 的相關研究邁進了一大步,大家都開始朝著這個方向把模型的規模擴大,因為我們發現當模型的參數越多、疊越多層、訓練資料也越多,最終的表現就會越來越好,於是 LLM 就這麼出現了。
大型語言模型 ( Large Language Model, LLM ) 指的是擁有大約數十億或數百億以上參數的語言模型,他們通過在大量未標註的文本上訓練而成。目前,大多數的 LLM 都是在 Transformer 的基礎上建立的,靠著極為複雜的計算以及大規模的參數,在某種程度上獲得了理解自然語言的能力,並在多種任務中表現都非常出色。
這一點可以在 2022 年的論文《Emergent Abilities of Large Language Models》看到,我截了這張圖的一部分下來:
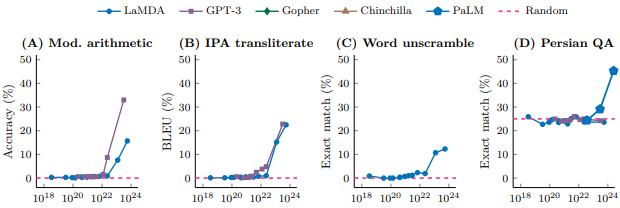
而我們也可以從這幾年的發展歷程來觀察:
2018 年的時候,OpenAI 推出了擁有 1.17 億參數的 GPT-1,而 Google 推出的 BERT 也有 3.4 億個參數。2019 年 GPT-2 擁有了 15 億個參數,而 Google 更是推出擁有 110 億參數的 T5 模型,就這樣規模越做越大,而表現也確實更好了。
此外,根據 Transformer 的 Seq2Seq 架構,也就是 Encoder 和 Decoder 這兩個部分,我們可以把 LLM 大致分為三類:
Encoder Only
顧名思義就是模型只包含編碼器的部分,我們以 BERT 為例,它的全名是 Bidirectional Encoder Representations from Transformers,也就是雙向的 Encoder 架構,主要使用了 Mask Language Model 和 Next Sentence Prediction 這兩種方式進行預訓練 ( Pretrain )。
BERT 在剛推出的時候各方面的表現都是最好的,譬如文本理解或文本分類,即便是現在也有許多 NLP 的任務是使用它經過優化後的模型。
Decoder Only
這個類型相較於前一種,更專注在生成任務上,最有代表性的就是 GPT 了,它的全名是 Generative Pre-Training Transformer,訓練方式是讓模型看過大量的資料,然後就像玩接龍一樣,不斷地預測下一個單詞的機率分佈,一步步生成出對應的句子。
Encoder-Decoder
這類模型就回到完整的 Transformer 結構了,代表的模型是 T5,它的全名是 Text-to-Text Transfer Transformer,目標就是將所有的任務不管是問答、翻譯、統整都轉換成 Text-to-Text 的統一格式,然後在前面附上任務名稱,以此獲得更好的回應,像這樣 Seq2Seq 的處理方式特別適合翻譯任務。
補充一下,然而這並不代表 BERT 跟 GPT 就可以和 Transformer 中的 Encoder 跟 Decoder 畫上等號,因為這兩個語言模型實際上都是在它的基礎之上進行一些預訓練和微調後的結果。
在實際應用上面,如果想要讓大型語言模型輸出品質更好、更符合我們期待的內容,只靠 ChatGPT 的聊天介面沒有辦法達到很好的效果 ( 以後或許有機會 ),因此,我們可以善用一些方式來應用 LLM,這些方式根據個人或企業的定位不同,能夠採取的作法也不太一樣。
這張圖可以把常用的四種應用方式表示出來:
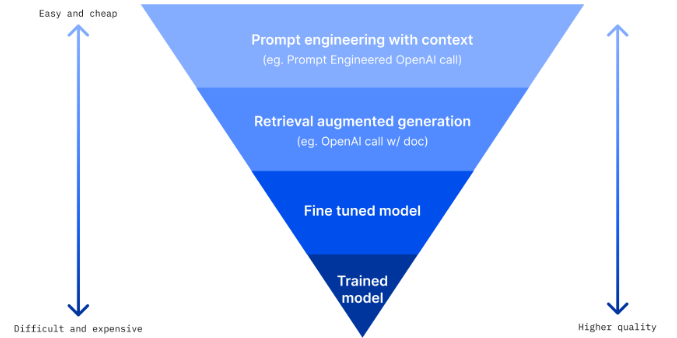
首先,我們最熟悉也最常用的方式就是提示工程 ( Prompt Engineering ),其實就跟我們平常在給 ChatGPT 下指令的概念類似,因為它容易上手而且成本比較低,會用到的技術比方說 Few Shot 或 Chain of Thought,這些 Prompting 的用法我之後會拉出一篇來聊聊。
接下來,還蠻實用而且也是我最近很常接觸的技術就是檢索增強生成 ( Retrieval-Augmented Generation, RAG ),它的想法其實就是通過資訊檢索的技術找到正確的資料並交給大型語言模型生成回應,避免 LLM 亂回答的問題,對於需要處理專業知識的任務來說是個不錯的選擇。
第三個做法是微調 ( Fine-Tuning ),從這裡開始就複雜一些了,假設我們如果希望 LLM 是在某個特定任務下的應用,比方說讓它成為一個對生物非常精通的專家,或是讓它每次生出來的句子都帶有「嗯」「啊」「哇塞」的語助詞,就可以通過微調的方式直接把這些知識直接讓模型吸收進去。像 ChatGPT 一開始就是從 GPT3.5 系列的模型微調而來,讓它更適合進行一些和人類對話的任務。
最後一個做法就是乾脆自己訓練一個模型,雖然這樣做的效果最好,但是成本非常驚人,需要超級大量的資料和計算資源,也只有大型企業才辦的到了。
所以我們在接下來的篇章中會比較偏向於前三種作法進一步的介紹,然後就可以開始收尾啦 ~
參考 & 推薦文章


 iThome鐵人賽
iThome鐵人賽